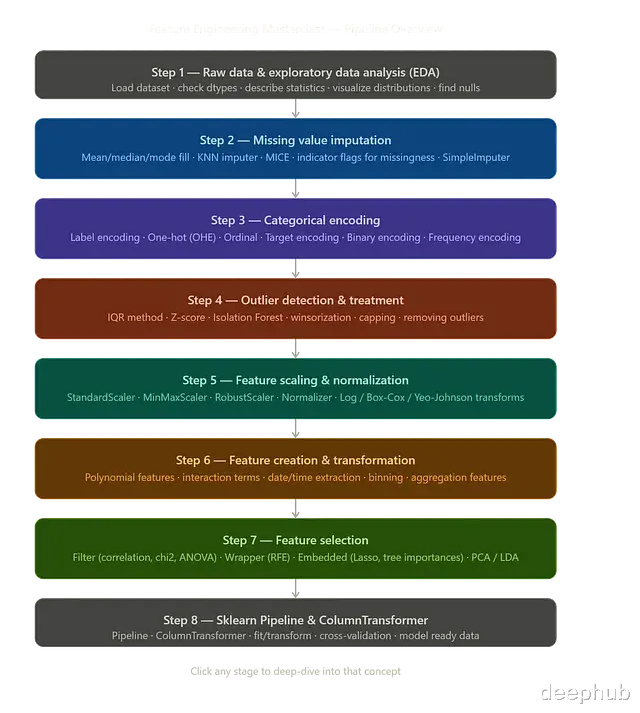
Feature engineering 是机器学习 pipeline 里最关键的一环。算法再好,如果输入数据噪声大、不一致或者缺乏有意义的特征,模型表现都不会很好
这篇文章用 Pandas 和 Scikit-learn,把一条完整的 feature engineering pipeline 做个完整的介绍
把原始数据转换成有意义的输入变量(特征),让机器学习模型表现更好——这就是 feature engineering。
动手做特征之前,先把数据看明白。
import pandas as pd import numpy as np np.random.seed(42) df = pd.DataFrame({ 'Age': [25, 30, np.nan, 40, 35, 120, 28], 'Salary': [50000, 60000, 55000, 80000, np.nan, 1000000, 62000], 'Gender': ['Male', 'Female', 'Female', np.nan, 'Male', 'Male', 'Female'], 'City': ['NY', 'LA', 'NY', 'SF', np.nan, 'LA', 'SF'], 'Experience': [1, 3, 2, 10, 7, 25, 4], 'Date': pd.date_range(start='2024-01-01', periods=7), 'Target': [0, 1, 0, 1, 0, 1, 0] }) print(df) print(df.head()) print(df.info()) print(df.describe())
检查缺失值
print(df.isnull().sum())
查看分布
import matplotlib.pyplot as plt df.hist(figsize=(12, 10)) plt.show()
Step 2 — 缺失值填补缺失值会拉低模型准确率。
均值 / 中位数填补
from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy='median') df['Age'] = imputer.fit_transform(df[['Age']])
众数填补
cat_imputer = SimpleImputer(strategy='most_frequent') df['City'] = cat_imputer.fit_transform(df[['City']])
KNN 填补
from sklearn.impute import KNNImputer knn_imputer = KNNImputer(n_neighbors=5) numeric_cols = df.select_dtypes(include=['int64', 'float64']) df[numeric_cols.columns] = knn_imputer.fit_transform(numeric_cols)
Step 3 — 类别编码模型只认数字,不认文本。
Label Encoding
from sklearn.preprocessing import LabelEncoder encoder = LabelEncoder() df['Gender'] = encoder.fit_transform(df['Gender'])
One-Hot Encoding
df = pd.get_dummies(df, columns=['City'], drop_first=True)
使用 Scikit-learn OneHotEncoder
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(handle_unknown='ignore')
Step 4 — 异常值检测与处理异常值会扭曲模型的学习过程。
用 IQR 检测异常值
Q1 = df['Salary'].quantile(0.25) Q3 = df['Salary'].quantile(0.75) IQR = Q3 - Q1 lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR outliers = df[(df['Salary'] < lower) | (df['Salary'] > upper)] print(outliers)
移除异常值
df = df[(df['Salary'] >= lower) & (df['Salary'] <= upper)]
Winsorization
from scipy.stats.mstats import winsorize df['Salary'] = winsorize(df['Salary'], limits=[0.05, 0.05])
Step 5 — 特征缩放与归一化不同量纲的特征会影响模型表现。
StandardScaler
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df[['Age', 'Salary']] = scaler.fit_transform(df[['Age', 'Salary']])
MinMaxScaler
from sklearn.preprocessing import MinMaxScaler minmax = MinMaxScaler() df[['Age', 'Salary']] = minmax.fit_transform(df[['Age', 'Salary']])
RobustScaler
数据里有异常值时使用。
from sklearn.preprocessing import RobustScaler robust = RobustScaler() df[['Age', 'Salary']] = robust.fit_transform(df[['Age', 'Salary']])
Step 6 — 特征构造与变换构造出有意义的特征,往往是准确率拉升最明显的一步。
日期特征抽取
df['Date'] = pd.to_datetime(df['Date']) df['Year'] = df['Date'].dt.year df['Month'] = df['Date'].dt.month df['Day'] = df['Date'].dt.day
多项式特征
from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(degree=2) poly_features = poly.fit_transform(df[['Age', 'Experience']])
数值变量分箱
df['Age_Group'] = pd.cut( df['Age'], bins=[0, 18, 35, 60, 100], labels=['Teen', 'Young', 'Adult', 'Senior'] )
Step 7 — 特征选择挑出真正重要的特征,可以减少过拟合,也能让模型跑得更快。
基于相关系数的选择
import seaborn as sns corr = df.corr(numeric_only=True) sns.heatmap(corr, annot=True)
SelectKBest
from sklearn.feature_selection import SelectKBest, f_classif X = df.drop('Target', axis=1) y = df['Target'] selector = SelectKBest(score_func=f_classif, k=5) X_new = selector.fit_transform(X, y)
递归特征消除(RFE)
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression model = LogisticRegression() rfe = RFE(model, n_features_to_select=5) X_rfe = rfe.fit_transform(X, y)
Pipeline 把预处理自动化,也能降低数据泄露的风险。
完整 Pipeline 示例
from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split X = df.drop('Target', axis=1) y = df['Target'] numeric_features = ['Age', 'Salary', 'Experience'] categorical_features = ['Gender', 'City'] numeric_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), ('scaler', StandardScaler()) ]) categorical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='most_frequent')), ('onehot', OneHotEncoder(handle_unknown='ignore')) ]) preprocessor = ColumnTransformer( transformers=[ ('num', numeric_transformer, numeric_features), ('cat', categorical_transformer, categorical_features) ] ) model_pipeline = Pipeline(steps=[ ('preprocessor', preprocessor), ('classifier', LogisticRegression(max_iter=1000)) ]) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 ) model_pipeline.fit(X_train, y_train) print("Model trained successfully")
总结Feature engineering 是机器学习项目能否成立的基石。干净、变换过、有意义的特征,往往胜过用劣质数据训练的复杂算法。
上面把这些步骤都做扎实,模型的准确率和稳健性都会上一个台阶。
在真实的机器学习项目里,feature engineering 往往比挑哪个模型更决定胜负。特征做得好,预测自然好。
https://avoid.overfit.cn/post/188a618a76db427191da88bb4a7aba5c
by Dhivakar