最近有一个话题的热度明显在往上走,就是本地化AI部署。不少开发者都在抱怨,云端API用着方便,但数据出域的问题始终绕不过去,而自己攒一台能跑千亿参数模型的机器,成本和技术门槛又太高。技嘉这次推出的AI TOP ATOM工作站,恰好卡在这个节点上,而且它的定位很直接——桌面级、开箱即用、能跑2000亿参数模型。

技嘉AI TOP ATOM工作站的核心是NVIDIA GB10 Grace Blackwell芯片,这是一颗把CPU和GPU通过先进封装整合在一起的超级芯片。制程用的是台积电3nm,TDP控制在140W左右,这意味着它能在迷你机箱里稳定运行,不需要像传统工作站那样配大尺寸散热器。GPU部分继承Blackwell架构,6144个CUDA核心,数量上和RTX 5070一致,但它的AI算力表现远超后者,关键差异在于两点:一是Tensor Core支持FP4和FP8低精度计算,在FP4精度下可以达到1000 AI TOPS;二是统一内存架构,CPU和GPU共享128GB LPDDR5x内存,通过NVLink-C2C互联,带宽是PCIe 5.0的五倍左右。

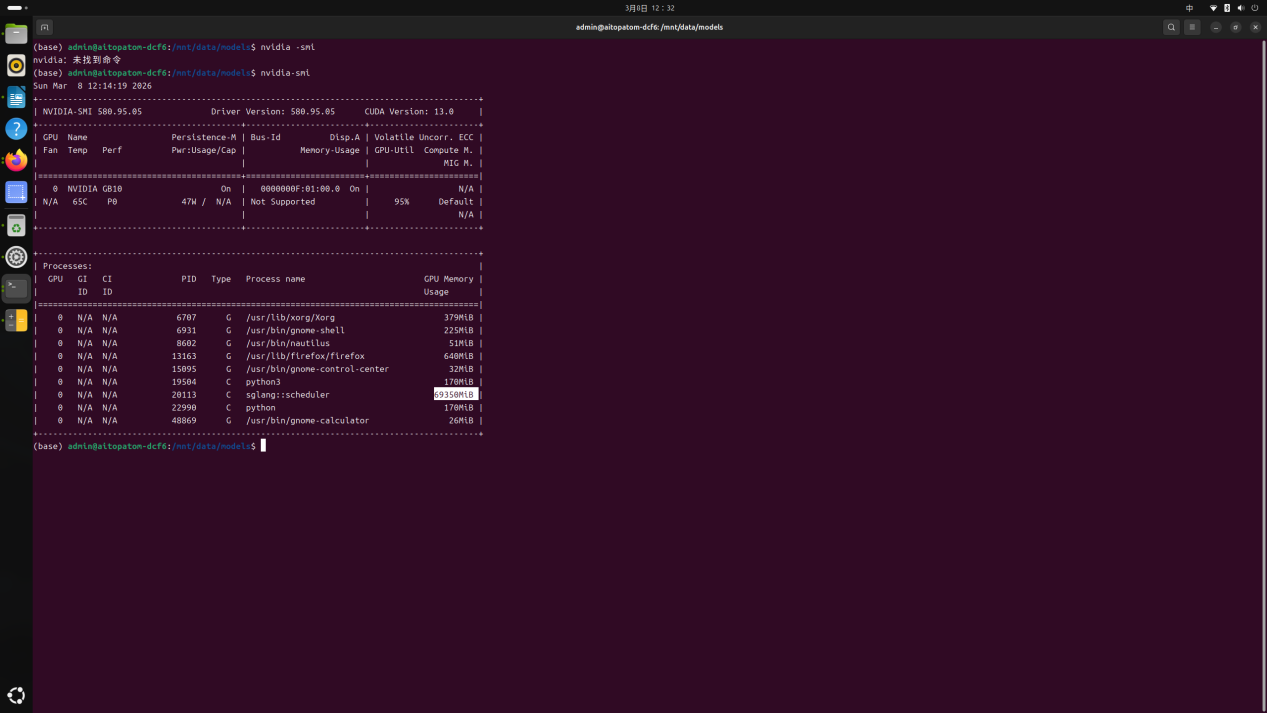
这个统一内存设计对于大模型推理非常关键。传统PC的显存和系统内存是分离的,模型加载时经常卡在显存容量上。而AI TOP ATOM的128GB统一内存可以被CPU和GPU无缝访问,实测运行GLM-4.5-Air 106B NVFP4模型时,显存占用约为68-69GB,剩余空间足够同时跑Embedding和Rerank实例。也就是说单机就能完成完整的RAG链路,不需要多台服务器拼凑。
整机尺寸150mm×150mm×50.5mm,金属外壳采用银灰色哑光磨砂处理,没有RGB灯效,散热出风口位于正面和接口侧,栅格内侧加了强化筋。背部接口包括3个USB 3.2 Type-C、1个HDMI 2.1a、1个万兆RJ-45,还有一个NVIDIA ConnectX-7接口。这个ConnectX-7值得单独提一下,它支持两台AI TOP ATOM直连,实现算力池化和显存叠加,理论上可以跑4000亿参数以上的模型。对于有扩容需求的开发团队来说,这种乐高式拼接比一次性采购大型服务器灵活得多。

软件层面,这次技嘉和趋境科技做了深度整合。预装的趋境智问系统基于Ubuntu底层,但做了全图形化封装,用户不需要敲命令行就能完成模型管理和调用。登录后台管理界面后,趋境AIMA平台会展示GPU/CPU负载、显存占用、Tokens消耗量等关键指标的动态图表。通过使用量排行榜可以快速定位资源消耗大户,方便管理员做配额优化。
模型管理方面,系统预装了GLM-4.5-Air 106B NVFP4大模型,同时也支持用户自行导入Qwen、Llama等私有模型。实测在模型管理界面下载Qwen 2.5 7B后,放在/mnt/data/models目录下,配置好参数即可生效。更实用的场景是多实例并行:我们在测试中同时启动了GLM-4.5-Air对话、Embedding向量化和Rerank重排序三个实例,系统自动分配资源,互不干扰。
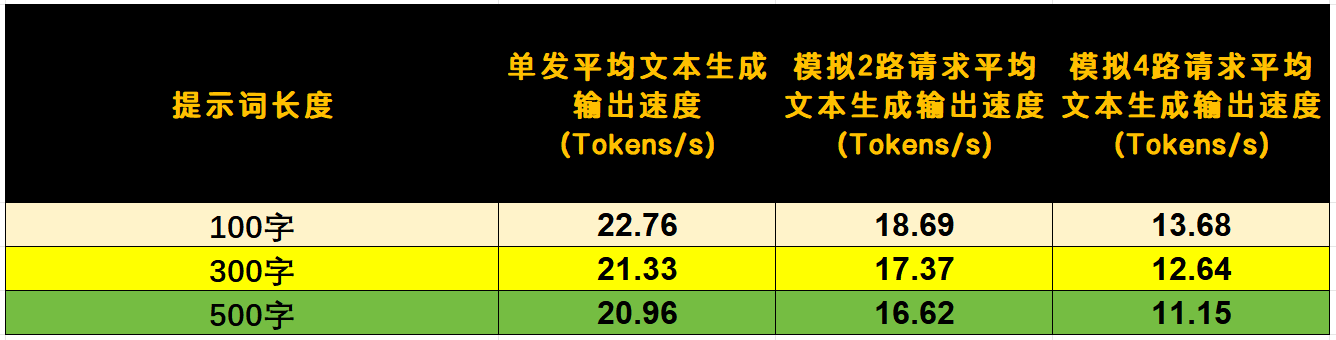
文本生成性能方面,在GLM-4.5-Air 106B NVFP4模型下,100字提示词的平均输出速度为22.76 Tokens/s,300字时21.33 Tokens/s,500字时20.96 Tokens/s。这个速度对于本地部署的千亿模型来说属于优秀水平,Blackwell架构的Tensor Core在NVFP4精度下的加速效果很明显。并发处理方面,4线程以内平均推理速度能保持在10 Tokens/s以上,这个表现已经足够作为小型团队共享的AI服务器使用。
需要特别说明的是,所有数据处理都在本地完成,物理层面与云端隔离。对于企业用户和注重数据隐私的个人开发者来说,这意味着没有数据出域风险,也不需要担心云端API的调用记录被留存。
总体来看,技嘉AI TOP ATOM解决的核心问题是:如何让个人开发者或小型团队,用可接受的成本获得本地化千亿模型推理能力。它没有堆砌夸张的硬件规格,而是通过GB10芯片的统一内存架构、NVLink-C2C互联、ConnectX-7扩展接口这三项关键技术,在迷你机身内实现了以往只有机架式服务器才能提供的AI算力密度。再加上趋境科技提供的全图形化软件栈,从模型管理到应用调用都无需编写代码,上手门槛大幅降低。
对于AI开发者、科研人员、数据科学家,以及有私有化部署需求的中小企业,这款产品提供了一个明确的选项:不需要自建机房,不需要聘请运维团队,桌面上一台迷你主机就能跑通千亿模型的训练微调和推理应用。在AI本地化这个确定的发展方向上,技嘉AI TOP ATOM工作站把门槛降到了目前桌面级硬件能做到的最低程度。