Momenta R6强化学习大模型是什么?
实验测试实际效果如何?
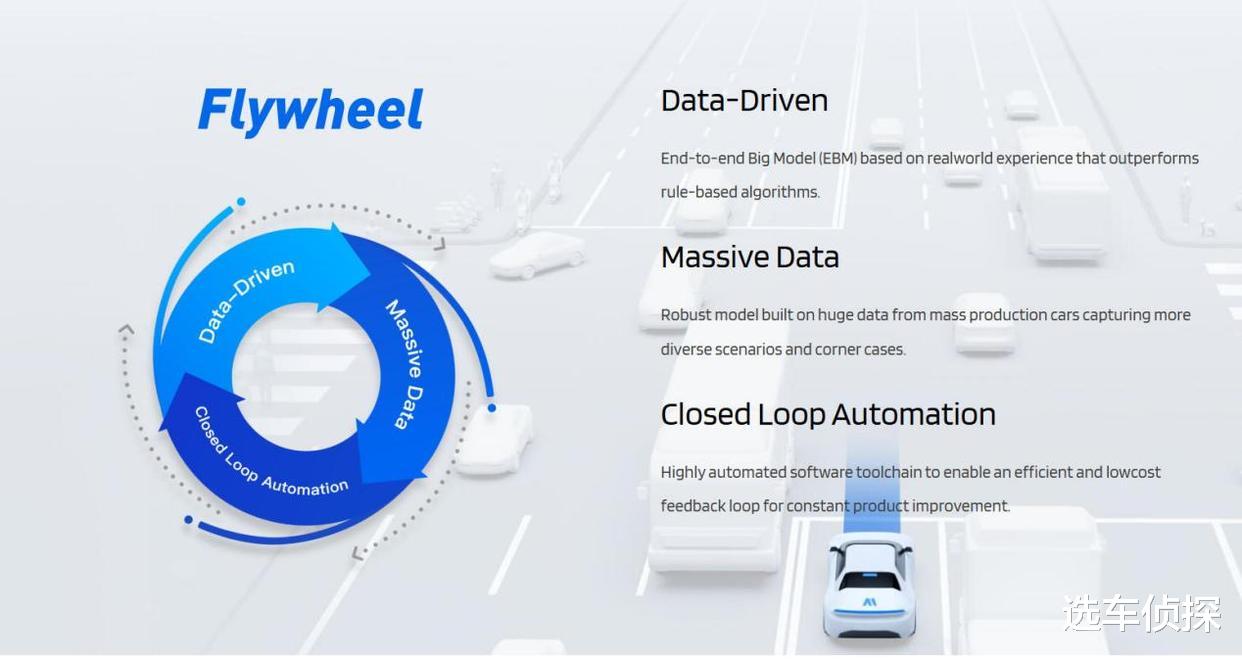
Momenta R6强化学习大模型是什么?
传祺向往S7在OTA升级4.0版本后,Momenta R6强化学习大模型正式上车,基本原理在于采用了闭环、端到端的数据驱动算法,尤其是深度强化学习技术。简单来说,系统通过海量的真实驾驶场景数据不断自我训练和迭代,像一个经验飞速增长的“老司机”,学习在复杂交通环境中如何感知,如何决策,转化成执行,而不是仅依赖预设的规则。

主要变化包括三方面,首先决策更像人,体验更自然,相比早期版本固定场景的算法,R6通过大模型对驾驶场景的理解更为深刻。能综合考量安全性、舒适性、通行效率等因素,做出更近似人类老司机的平顺决策,例如更线性柔和的刹车力度、更果断安全的变道时机。

第二点就是可以应对更复杂的环境,传统算法对罕见或极端场景处理能力有,比如冬天的雪堆等特殊障碍物,马路上突然出现的加塞等。R6大模型凭借数据驱动学习能力,可以更好地处理没有在代码中明确定义的场景,在复杂环境中也可以交给辅助驾驶。

第三点就是个性化与自适应,新版本引入了可自定义的驾驶风格,比如柔和、标准、敏捷,意味着系统不仅能安全驾驶,还能根据你的偏好调整驾驶策略,这是从单一安全逻辑向个性化舒适体验的提升,就像你突然多了三个老司机辅助,可以根据自己的喜好选择一个,而不是固定的一位。

实验测试
在实际道路与专业场地测试中,R6强化学习大模型表现怎么样?首先是主动安全测试,在专业的AEB自动紧急制动测试中,车辆以60km/h速度直面模拟障碍物(一个假车)。R6可以瞬间识别风险、触发制动,刹车的力道线性稳定,一方面确保车辆在短距离内安全刹停,另一方面避免了车内乘员被急刹冲击。在模拟鬼探头和倒车后方电动车横穿等突发场景下,系统均能完成感知,快速刹车,也就是说,前进后退都不怕。


日常驾驶中,新手司机最怕的就是突发状况,导致手忙脚乱,大脑一片空白,把油门当刹车,在油门防误踩测试中,当检测到前方有障碍物,驾驶员仍猛踩油门时,系统会立即判断为碰撞风险,果断限制动力输出并发出警示,防止因紧张或失误导致的事故。


同时我们也实测了R6大模型的个性化驾驶模式,有柔和、标准、敏捷三种可自定义的驾驶风格。实测中,在拥堵中切换至敏捷风格,车辆变道超车更为果断,应对加塞也比较自然,不会突然一脚刹停;使用柔和风格,转向与加减速都更为平缓,市区跟车更舒适。整个试驾过程中,系统未出现压线、抢道等违规行为,甚至在施工路段也能基于导航提前规划,平顺绕行,不怕违反交通规则。测试中,我们长时间脱手,S7出现三级提醒,如果不接手,还会自动靠边停车,避免对辅助驾驶严重依赖。

停车也是大部分用户的“头大”之处,Momenta R6强化学习大模型面对比车身宽40厘米的窄车位,可以自动折叠后视镜,然后规划路径,一气呵成完成泊入,折叠后视镜也是普通用户倒车时不敢操作的,这是辅助驾驶的优势之一,车内还可以自定义泊车后的车身位置,比如居中/偏左/偏右,比如一边靠墙无法开门,就可以偏向另一边,防止停车到位了,就是下车不容易。


选车侦探观点:简单来说,Momenta的R6模型就是一个经过海量“实战练习”的超级AI司机。以前的自动驾驶系统,像个分工明确的团队,有人看路,有人想路线,有人操作方向盘。而R6就像一个老司机,把看路、想事、操作这些事融会贯通,一气呵成。不是靠死记硬背规则,而是在无数次的驾驶经验中,自己琢磨出了流畅拟人的开车方式。所以传祺向往S7 4.0 OTA后开起来更丝滑,处理突发情况更像人类,能更好地应对那些没见过的复杂路况。这算是自动驾驶技术向老司机思维迈进的一大步。
评论列表