我做数据这么多年,总是会听到:
"我快被这个月的数据搞疯了!上周做的销售报表,今天业务部门说数据对不上,差了好几十万。"
"数据一直对不上,是不是数据源有问题?"
"一堆格式不对的数据,光整理这些就花了两天时间,结果还是出错了。"
听着是不是很熟?
其实说白了,这些问题都在于数据清洗没做好。如果忽视数据清洗,就算有再精妙的计算公式和再高级的工具也是白搭,后续分析一定会出错,决策还是不精准。
那到底要怎么做好数据清洗呢?
下面我来给大家好好讲讲数据清洗,这样你就对它有了一个整体把握,也能从中得到解决方法。
一、 我们为什么要进行数据清洗?你可能会想,数据拿到手,直接导入工具分析不就行了吗?为什么非要花费大量时间,去做清洗这种看似“枯燥”的工作呢?
简单来说,真实世界的数据,绝大多数都是不完美,甚至是“脏”的,它们可能来自不同的业务系统,由不同的人录入,经历了复杂的流转过程。
数据清洗,就是把这些原始数据变得规整、干净、可用的过程。
那么,这么做具体能带来什么好处呢?
保证分析结果的准确性:这是最核心、最根本的原因。如果基础数据本身就是错的,那么无论你的模型多高级、算法多精妙,得出的结论也必然是错误的,甚至会引导你做出完全错误的决策。这背后有一个著名的原则:垃圾进,垃圾出。你想,如果你的销售数据里混入了测试数据,或者客户年龄出现了负值,基于这些数据制定的市场策略,怎么可能正确呢?
提升数据分析的效率:干净、规整的数据,能被分析工具,比如Python的Pandas, SQL等更快速、更高效地处理。如果数据中存在大量缺失值、异常值或者不一致的格式,计算过程会不断报错、中断,或者产生不可预知的后果,极大地拖慢你的工作进度。
统一数据口径,确保一致性:不同部门、不同时期录入的数据,标准可能完全不同。比如,性别字段,有的记录是“男/女”,有的是“1/2”。如果不进行统一,计算机在统计时就会把它们当成三种不同的类别,结果自然是混乱的。
那我们要怎么实现呢?
我们可以利用数据集成工具,比如我常用的FineDataLink,它就能一键添加清洗规则,直接把清洗后的数据呈现出来,非常方便,新手也能快速上手。
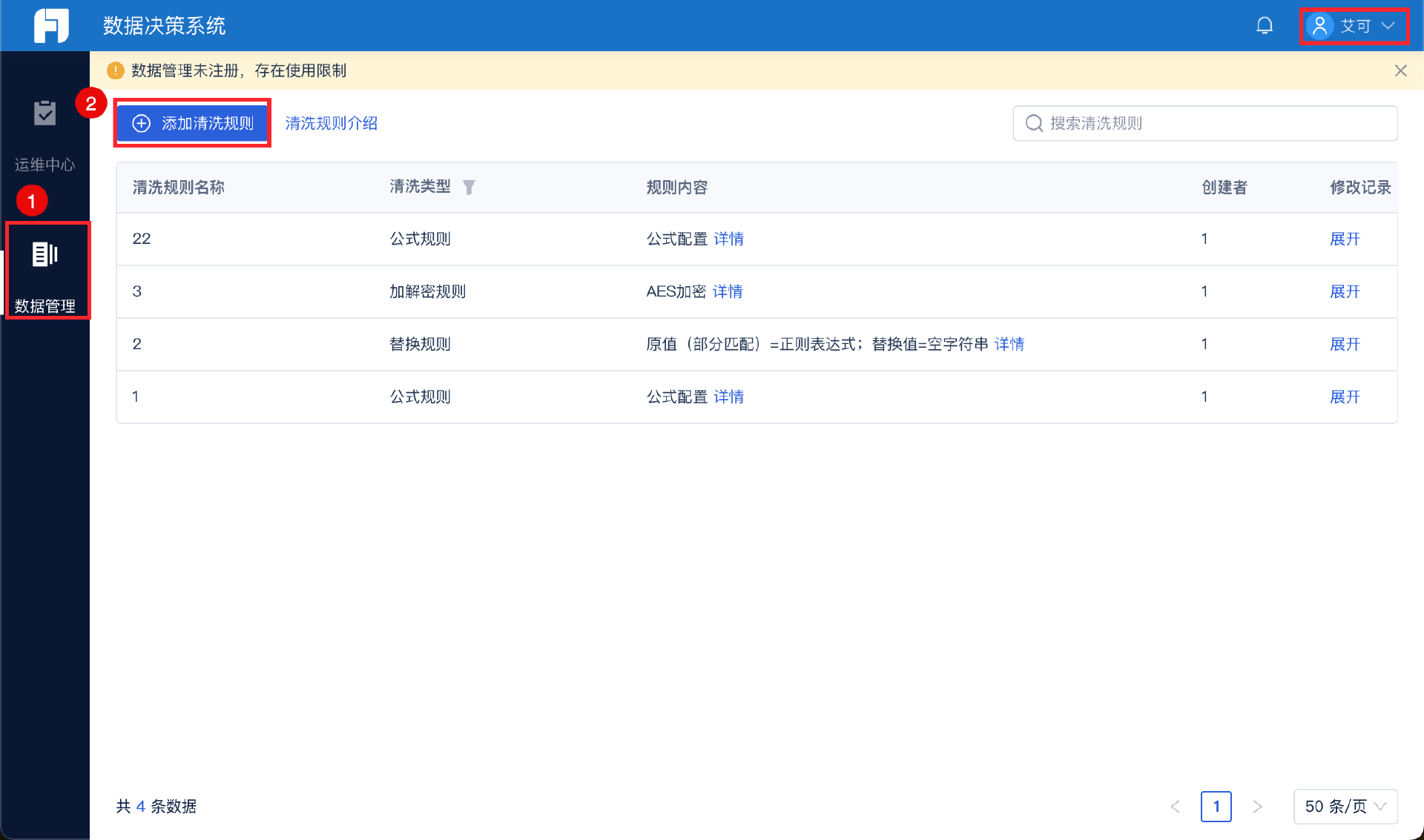
说白了,数据清洗不是一个可选项,而是一个必选项,它是你对数据负责、对分析结果负责的第一步。
聊完了为什么,咱们再看看,这个过程里具体有哪些让人头疼的地方。
二、 数据清洗的痛点有哪些?知道了必要性,我们还得清醒地认识到其中的挑战。这些痛点,几乎每个数据分析师都深有体会。
耗时耗力,成就感低:数据清洗工作往往会占据一个数据分析项目70%-80%的时间。你花了大量精力在查找、判断、修正数据上,但最终成果却大多隐藏在后台,无法直接体现在光鲜的分析报告里。这种“幕后英雄”式的付出,有时会让人觉得付出与回报不成正比,因此可能会出现数据清洗不全面,员工积极性不高等情况。
规则制定困难:这是最考验专业能力和经验的地方。比如,看到一个缺失的年龄值,你是直接删除这一行?还是用平均年龄填充?或者通过其他信息推断?每一种选择都会对后续分析产生不同影响:规则定得太严,可能会误删大量有效数据;定得太松,又可能留下隐患。
问题隐蔽难发现:有些数据问题不是一眼就能看出来的。比如,日期格式看起来都是“2023-01-01”,但可能混入了极少数“2023/01/01”的格式,在批量处理时就会导致错误;或者数值看起来合理,但单位不统一,这种问题不经过仔细检查,极易被忽略,从而导致分析结果出现数量级的偏差。
业务理解的挑战:数据清洗不仅仅是技术活,更是业务活。一个值在技术上看起来是异常值,比如,某个商品的销售额突然飙升,但在业务上可能是一次成功的促销活动。如果你不理解业务背景,仅凭统计规则去清洗,很可能把最有价值的信息给“洗”掉了。你懂我意思吗?脱离业务的数据清洗是盲目的。
既然有这么多困难,我们总不能束手无策。那么,具体要怎么操作呢?
三、 数据清洗有哪些核心方法?面对这些痛点,我们要有一套系统性的方法来应对。下面我梳理出一个清晰的流程,你可以把它当作一份操作指南。
第一步:理解数据与诊断问题
在动手之前,先为数据做一次全面体检。使用描述性统计查看数据的基本分布,检查是否有明显的异常值,查看数据的前几行和后几行,对数据有个直观感受。这个阶段的目标是发现问题的范围和类型。
第二步:处理缺失值

缺失值是最常见的问题。主要有以下几种处理方式:
删除:如果某一行或某一列的缺失值比例非常高,并且对分析目标不重要,可以考虑直接删除。
填充:这是更常用的方法。可以用统计量填充,比如均值、中位数、众数等,也可以用前后值填充(适用于时间序列数据),或者通过算法模型预测填充。选择哪种方法,取决于数据的特性和业务逻辑。
保留并标记:有时,缺失本身也是一种信息。你可以创建一个新的标志字段,比如“是否缺失年龄”,将其作为一个新的特征放入模型中,有时会带来意想不到的效果。
第三步:处理异常值
异常值是指那些明显偏离其他数据点的值。
识别:可以通过箱线图、散点图可视化发现,也可以通过统计方法,如Z-score、IQR法则来量化识别。
处理:同样需要谨慎。如果是录入错误,可以修正或视为缺失值处理;如果是业务上的特殊情况,则需要结合业务判断是保留还是剔除。
对于数据缺失和异常,我会利用FineDataLink的数据过滤功能,设置过滤条件就能一键得到想要的数据。

第四步:处理不一致数据
这是个体力活,但至关重要。
格式标准化:将日期、时间、数字、文本等统一成一致的格式。比如说,把所有日期转为“YYYY-MM-DD”格式。
文本清洗:包括去除首尾空格、统一大小写、纠正拼写错误、将同义词统一。
数据类型转换:确保每一列的数据类型是正确的,比如把存储为字符串的数字,转换为数值类型,才能进行数学运算。
第五步:处理重复数据
完全重复的行通常没有分析价值,反而会干扰统计结果,一般直接删除。但需要注意,有些数据可能不是完全重复,只是关键字段重复,需要根据业务主键来判断。
第六步:数据转换与重构
为了满足特定分析模型的需要,有时还需要进行一些转换。
数据规范化:将数值缩放到一个特定的区间,消除量纲影响,这在很多机器学习算法中是必须的步骤。
数据离散化:将连续数据分段,变成类别数据。比如将年龄分为青年、中年、老年。
比如在FineDataLink里,可以制定清洗规则,也就是统一字段标准 + 建立映射规则,这样就能保证数据的规范性,是不是在后续工作里就十分便利了?


我一直强调,这个流程不是僵化的,你需要根据手中数据的具体情况和你的分析目标,灵活地选择和调整步骤。
掌握了基本方法,是不是就高枕无忧了?别急,还有一些关键的心法和原则,能让你事半功倍。
四、 数据清洗的注意事项最后,结合我自己的教训,给你几点关键的注意事项。
保留原始数据:要注意,任何清洗操作,都必须在数据的副本上进行。你必须确保在任何时候,都能回溯到最原始的数据状态。这是一个重要的保障。
结合业务知识:我一直强调,技术手段必须与业务知识结合。在清洗每一个字段前,最好都能结合业务知识,保持和业务人员的沟通交流,他们的经验能帮你避免很多想当然的错误。
迭代进行,循序渐进:可以先处理最严重、最明显的问题,然后进行一轮简单的分析,看看效果,接着再处理下一层问题。这种迭代的方式,能让你及时发现问题,避免在错误的方向上走得太远。
保持怀疑,持续验证:清洗后的数据,并不代表就是绝对正确的。你要持续地用各种方法去验证它,比如与历史报告对比,与业务常识核对。
总结说到底,数据清洗是一项无法绕开的基础性工作,它看似繁琐枯燥,却是整个数据分析流程的基石。数据清洗考验的不仅是技术,更是耐心、严谨和对业务的理解深度。
现在你看完了这篇文章,相信你对数据清洗有了一个整体的把握,下次在面对杂乱的数据时你就有了一个清洗思路。要知道,数据清洗的目的始终是为了最后的决策支持,数据清洗做好了,就能为后续的工作节省大量的时间,帮助你及时调整策略,而不是只凭经验和感觉。