在生物信息学这一充满无限可能的领域中,组学(Omics)无疑是一个具有划时代意义的概念。它依托高通量、高灵敏度的实验技术,是一门系统性、全局性地收集并研究生物体在不同生命阶段产生的大规模数据的交叉学科。
组学的核心在于从整体视角全面描绘生物分子,以此揭开生命活动本质规律的神秘面纱。随着技术的持续革新,组学研究早已突破传统单一分子层次的局限,迈向多层次、多维度的系统生物学研究新阶段。
每一种“组学”都聚焦于生命系统的不同维度展开深度探索,通过多角度、多时间点、多空间层次的数据采集与整合,精准反映生物体内错综复杂的分子调控网络和生理状态。
接下来,一同深入了解4种组学的概念以及它们常见的分析流程。
No.1 基因组生信分析基因组数据分析有着一套严谨且关键的常见流程,每个步骤都环环相扣,共同保障数据的准确性和分析结果的可靠性。

获取基因组数据主要有两种途径。一是借助高通量测序技术,像Illumina、PacBio或Nanopore平台,这些技术能生成原始序列数据,通常以FASTQ格式呈现。二是从公共数据库下载已有的基因组数据,这些数据文件可能包含单端或双端测序数据。
质量控制原始序列数据的质量参差不齐,需要进行全面评估。利用FastQC这类工具,可以检查序列的质量分数、碱基组成偏倚等情况。对于质量不佳的数据,需使用Trimmomatic和Cutadapt等工具进行清理,去除低质量碱基和接头序列。在评估过程中,Phred评分用于衡量每个碱基的测序质量,而GC含量异常可能暗示存在测序问题,接头污染则会影响后续比对的精准度。
序列比对将测序得到的reads准确比对到参考基因组上,是进一步分析的基础。常用的比对软件有BWA、Bowtie、SHISAT2等。比对完成后,输出结果会以SAM/BAM格式的文件存储,方便后续处理。
变异检测依据比对结果,能够识别出单核苷酸多态性(SNPs)、插入缺失(Indels)以及其他结构变异。GATK、FreeBayes等是常用的变异检测工具。
功能注释对检测到的遗传变异进行功能注释至关重要,这有助于筛选出在临床或功能上具有重要意义的变异,并确定它们是否会对基因功能产生影响。VEP、SnpEff和ANNOVAR等注释工具能将变异与已知的基因、蛋白质影响以及人群频率等信息进行比对分析。
下游分析下游分析内容丰富多样,涵盖多个领域:
功能富集分析:借助DAVID、clusterProfiler等工具,挖掘基因功能背后的生物学意义。
群体遗传学分析:利用PLINK、ADMIXTURE等工具,研究群体间的遗传关系和结构。
肿瘤学分析:通过MutationalPatterns、PyClone等工具,深入探究肿瘤的遗传特征和进化规律。
可视化工具:IGV可用于直观查看变异情况;R/ggplot2能进行统计分析和可视化展示;Circos则擅长生成基因组图谱,让数据一目了然。
基因组学应用前景基因组学在多个领域展现出巨大的应用潜力:
精准医疗:以癌症基因组分析为例,它能够为靶向治疗提供精准指导,实现个性化医疗。
结合AI创新:与人工智能技术相结合,可进行基因功能预测和新基因发现,为生命科学研究开辟新路径。
基因治疗突破:基因编辑技术(如CRISPR)的发展,有力推动了基因治疗的落地应用,为攻克疑难病症带来新希望。
No.2 转录组生信分析转录组生物信息分析,本质上是一个从RNA测序数据中深度挖掘生物学信息的过程。其核心目标在于精准理解基因的表达模式,精准识别出在不同条件下差异表达的基因,并深入探索这些基因所具备的功能。
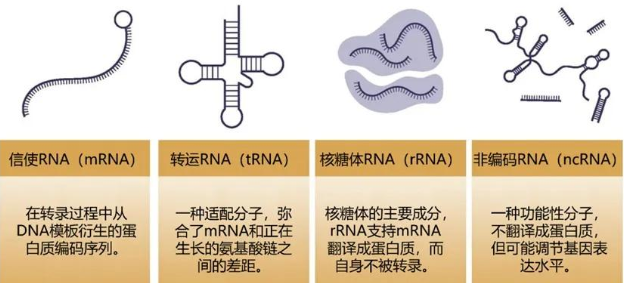
质控检查:首先,要对原始数据进行全面的质量控制检查。可借助NanoPlot和SMRTLink等工具,对数据的各项指标进行详细剖析,以此判断数据质量是否达标。
纠错提升:为了进一步提升数据质量、降低错误率,会使用LoRMA或Proovread等工具对数据进行纠错处理。通过这一步骤,能有效减少数据中的错误信息,为后续分析提供更可靠的数据基础。
序列比对与聚类比对参考:利用minimap2、GMAP或STAR - long等工具,将经过处理的高质量数据精准比对到参考基因组上。这一步骤如同将拼图碎片准确拼接到完整的拼图板上,为后续分析提供准确的定位信息。
优化聚类:完成比对后,需要去除数据中的冗余信息,并合并相似的转录本。这一过程能显著提高分析的准确性,常用的工具包括cDNA_Cupcake、StringTie和FLAIR等。
转录本注释结构分析:使用SQANTI3、gffcompare和TALON等工具,对转录本进行详细注释,深入分析转录本结构的分类情况。这有助于我们了解转录本的组成和特征,为后续功能分析奠定基础。
质控评估:在注释过程中,还需要评估各项质控指标,确保注释结果的可靠性。只有可靠的注释结果,才能为后续研究提供准确的信息。
定量与差异分析表达定量:借助Salmon、RSEM或Bambu等工具,对转录本的表达量进行精确定量。通过定量分析,我们可以了解不同基因在不同条件下的表达水平,为差异表达分析提供数据支持。
差异挖掘:利用差异表达分析工具,如DESeq2、edgeR和limma - voom等,对不同条件下的转录本进行差异表达分析。通过这一步骤,能够找出在不同条件下表达水平发生显著变化的基因,为进一步研究基因功能提供方向。
功能分析与可视化功能注释:通过eggNOG - mapper、InterProScan以及GO/KEGG富集分析等工具,对新转录本进行全面的功能注释。这有助于我们了解新转录本在生物体内可能发挥的作用,揭示其生物学意义。
图形展示:使用IGV、Sashimiplots、pyGenomeTracks等工具进行可视化展示。通过图形化的方式,我们可以更直观地理解转录本的结构和功能,发现数据中隐藏的规律和特征。
转录组学应用前景时空图谱:转录组学与空间转录组技术相结合,有望实现具有“时空分辨率”的基因表达图谱绘制。这将使我们能够更精准地了解基因在不同时间和空间上的表达情况,为生命科学研究提供更详细的信息。
多领域应用:在免疫治疗、发育生物学、神经科学等多个方向,转录组学都有着广阔的应用前景。通过深入研究基因表达模式,能够为这些领域的研究提供新的思路和方法,推动相关领域的发展。
No.3 蛋白组生信分析蛋白组学的核心任务是借助高通量技术,尤其是质谱(MS)技术以及其他生物技术手段,全面解析蛋白质的表达水平、修饰状态以及它们之间的相互作用关系,从而揭示隐藏在背后的生物学机制。
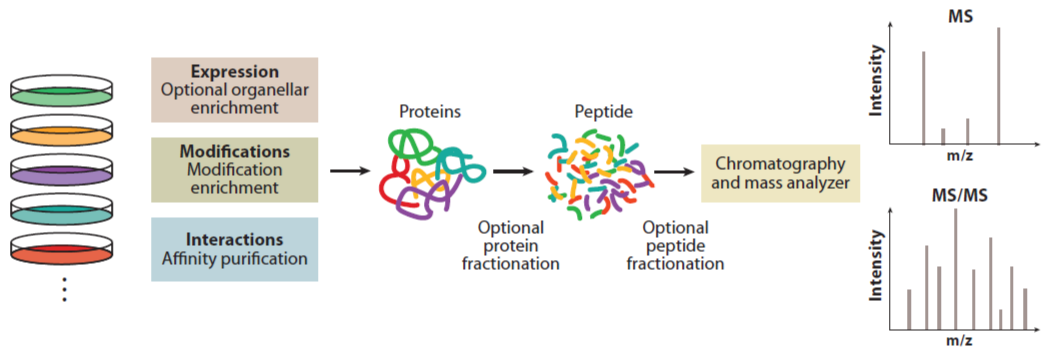
去噪校正:对原始质谱数据进行去噪和基线校正处理,这是提高数据质量的关键步骤。通过去除数据中的噪声和校正基线,能够使数据更加准确可靠,为后续分析提供良好的基础。
峰识别提取:进行峰识别与提取操作,生成特征列表。每个特征都包含m/z值、保留时间以及强度信息,这些信息是后续定量和分析的重要依据。
定量分析相对丰度计算:对于标记或非标记定量策略,需要计算各蛋白在不同样本中的相对丰度。常用的方法包括iTRAQ、TMT标签定量,以及label - free方法。通过这些方法,可以了解不同样本中蛋白质的表达水平差异。
数据归一化:为了确保不同样本之间比较的准确性,需要对定量数据进行归一化处理。这一步骤能够消除样本之间的系统误差,使数据具有可比性。
差异表达分析表达变化比较:比较不同条件下蛋白质的表达变化情况,识别出差异表达的蛋白质。通过这一步骤,可以找出在不同条件下表达水平发生改变的蛋白质,为进一步研究其功能提供线索。
统计学检测:应用统计学方法检测差异表达的显著性,常用的软件包有Perseus、limma等。同时,需要调整P值以控制假发现率,确保检测结果的可靠性。
功能注释与富集分析亚细胞定位与功能分析:首先进行GO Cellular Component富集分析,筛选出蛋白质的亚细胞定位信息;再进行Molecular Function分析,更清晰地定义蛋白的生物学作用。通过这两个步骤,能够全面了解蛋白质在细胞内的位置和功能。
多数据库整合与通路分析:使用Cytoscape插件ClueGO整合多数据库结果,或者采用基因集富集分析(GSEA)进一步分析富集通路。这有助于我们从多个角度了解蛋白质的功能和参与的生物学过程。
蛋白互作网络设置合适的置信度阈值(一般≥0.7),通过导出TSV文件与Cytoscape结合分析,能够揭示蛋白间的相互作用网络。通过分析蛋白互作网络,我们可以了解蛋白质之间的相互关系,发现关键的蛋白质节点和调控通路。
多组学整合共表达网络构建:通过WGCNA构建蛋白与基因的共表达网络,揭示重要的功能模块。共表达网络能够帮助我们发现蛋白质和基因之间的协同表达关系,为理解生物学过程提供新的视角。
通路映射分析:利用KEGG Mapper将转录组与蛋白组数据中的差异分子进行映射,挖掘潜在的生物学通路。通过通路映射分析,我们可以了解不同组学数据之间的关联,发现潜在的生物学机制。
机器学习筛选:利用随机森林或PLS - DA等机器学习方法筛选跨组学特征标志物,揭示生物学机制。机器学习方法能够从大量的数据中提取有用的信息,帮助我们发现潜在的生物学标志物和调控机制。
蛋白组学应用前景临床标志物筛选:更高通量、更高灵敏度的质谱技术不断发展,将有力推动临床标志物的筛选工作。通过检测蛋白质的表达水平和修饰状态,能够发现与疾病相关的生物标志物,为疾病的诊断和治疗提供新的方法。
信号通路理解深化:翻译后修饰(PTMs)研究能够深化我们对信号通路的理解。蛋白质的翻译后修饰在信号传导过程中起着重要的调控作用,深入研究PTMs有助于揭示信号通路的调控机制。
亚细胞定位图谱构建:空间蛋白质组学的发展将助力构建亚细胞定位图谱。通过了解蛋白质在亚细胞结构中的定位情况,能够更深入地了解细胞的功能和生物学过程。
No.4 单细胞空间组生信分析单细胞空间组学生物信息分析(Single - cell spatialomics analysis),作为近年来生物信息学领域的关键发展方向,正展现出巨大的潜力与价值。
单细胞组学与空间组学的有机融合,意义非凡。它不仅能精准呈现细胞的分子特征,还能清晰揭示细胞在组织中的具体空间定位以及它们彼此之间的相互关系。这一特性为构建全面且细致的细胞图谱提供了坚实支撑,更为深入理解复杂生物过程开辟了全新途径。
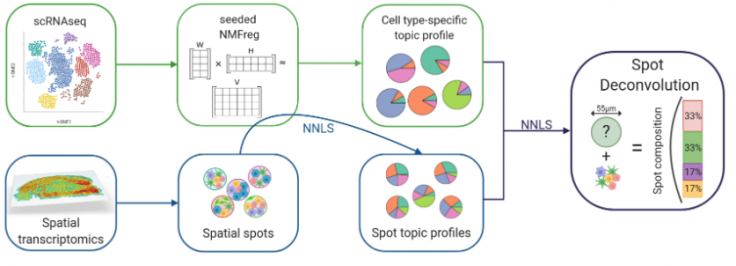
单细胞数据采集:借助单细胞测序技术,科研人员可根据实际需求选择高通量或全长转录组技术,像10x Genomics Chromium、Smart - seq2等。通过这些先进技术,能够获取细胞层面的基因表达数据,为后续分析提供丰富的原始信息。
空间组学数据获取:运用空间转录组学平台,例如Visium by 10x Genomics、Slide - seq等,可以获取组织切片的空间定位信息,以及相应区域内细胞的基因表达数据。这一步骤为研究细胞在组织中的空间分布奠定了基础。
单细胞数据分析质控与预处理:对获取的单细胞数据开展严格的质量控制工作,仔细甄别并去除低质量细胞以及双胞体,同时进行归一化处理。这一系列操作能够确保数据的质量和可靠性,为后续分析提供准确的数据基础。
降维与聚类:应用PCA、t - SNE或UMAP等经典方法对数据进行降维处理,降低数据的复杂性。随后,依据细胞的表达模式进行聚类分析,常用的聚类方法有Leiden和Louvain算法。通过聚类,可以将具有相似表达特征的细胞归为一类,便于后续深入研究。
细胞类型注释:基于已知的标记基因,对聚类得到的细胞簇进行详细注释,从而确定主要的细胞类型。常见的注释方法包括参考专业数据库,如CellMarker、PanglaoDB,也可以根据已知的marker基因进行手动标记。准确的细胞类型注释是理解细胞功能和生物学过程的关键一步。
空间组学数据分析图像处理与配准:处理空间转录组学(ST)数据所附带的组织图像,在必要时将其与参考图谱进行精准配准。这一操作能够确保空间信息的准确性,为后续分析提供可靠的空间定位依据。
表达矩阵生成:从原始读段中精心提取并量化每个spot(空间位置)的基因表达水平。常用的工具包括BayesSpace、Squidpy等。通过生成表达矩阵,可以将空间位置与基因表达信息相结合,为进一步探索基因的空间分布提供数据支持。
空间模式探索:利用专业工具深入探索基因表达的空间分布模式,识别出具有特定空间特征的基因或细胞群。常用的工具如SPOTlight和Seurat的TransferData等。通过空间模式探索,能够发现基因在组织中的独特分布规律,揭示细胞的空间组织特征。
数据整合跨模态匹配:通过细致比较单细胞数据和空间组学数据中的基因表达谱,寻找两者之间的对应关系。常用的方法包括Seurat的锚点算法、Harmony等。跨模态匹配能够将单细胞层面的信息与空间组学层面的信息有机结合起来,为后续分析提供更全面的视角。
映射单细胞到空间坐标:基于上述匹配结果,将单细胞类型精准分配给空间组学中的spots,从而推测每个spot处的主要细胞类型组成。这一步骤实现了单细胞数据与空间信息的深度融合,使我们能够更直观地了解细胞在组织中的空间分布情况。
空间异质性分析空间热点检测:识别基因表达或细胞类型的空间聚集区域,帮助研究者深入理解组织中的空间异质性。常用的分析方法有SpatialDE和Giotto等。通过空间热点检测,可以发现组织中具有特殊生物学功能的区域,为进一步研究提供重要线索。
细胞互作分析:基于细胞的空间邻近性,推断细胞在组织中的空间定位对其通讯模式的影响。常用的工具包括CellChat和CellPhoneDB等。细胞互作分析能够揭示细胞之间的相互作用机制,为了解组织的生物学功能提供关键信息。
轨迹推断:借助专业工具重建细胞的发育或分化轨迹,在结合空间信息的基础上推断细胞的动态变化过程。常用的工具如Monocle3和PAGA等。轨迹推断有助于我们理解细胞在发育过程中的演变规律,揭示生命的奥秘。
功能富集与互作网络分析功能富集分析:针对在特定空间区域内高表达的基因,执行GO富集分析、KEGG通路分析等。通过这些分析,能够揭示这些区域的功能特性,深入了解基因在特定空间环境下的生物学作用。
细胞间互作预测:使用CellPhoneDB等专业工具,预测不同细胞类型间的潜在互作,尤其是在特定空间背景下的相互作用。细胞间互作预测有助于我们构建细胞间的相互作用网络,全面理解组织的生物学功能。
单细胞空间组学应用前景疾病机制研究:在肿瘤、神经退行性疾病等领域,单细胞空间组学能够深入揭示细胞的异质性和微环境特征。通过研究细胞在疾病状态下的空间分布和相互作用,为疾病的发病机制研究提供新的思路和方法。
发育生物学:在胚胎发育过程中,单细胞空间组学可以解析细胞的动态变化和组织构建过程。通过观察细胞在发育过程中的空间迁移和分化,为了解生命的起源和发展提供重要依据。
药物研发:在药物研发领域,单细胞空间组学能够评估药物在组织中的分布和作用机制。通过研究药物对细胞的空间影响,为药物的优化和精准治疗提供科学指导。