原文:https://x.com/akshay_pachaar/status/2069118430582866051
你的信息流突然都在说同一件事「别再给 Agent 写 prompt 了,开始设计循环。」
Claude Code 的构建者 Boris Cherny 说得很直白:
「我已经不给 Claude 写 prompt 了。我有循环在跑。我的工作就是写循环。」
地球上最流行的编程 Agent 之一的创始人,自己不给它写 prompt。那他到底在干什么?
这就是 Loop Engineering 的核心命题。下面我们拆解它为什么比看上去更难。
第一层:循环本身Agent 不是什么黑魔法盒子。它本质上就是一个朴素循环:
while True:response = model(context)
if response.has_tool_calls():
results = run_tools(response.tool_calls)
context += results
else:
break
模型读上下文 → 要求调工具 → 你跑工具并把结果喂回去 → 模型再读 → 重复,直到它不再要求调工具。
Model → tools → context → repeat。
然后是最让人意外的部分:
这个循环本身已经被解决了。
每个正经的 Agent 框架最后都会收敛到大概这六行代码。没人还在竞争 while 语句怎么写。
那如果循环本身这么简单,所有人到底在工程化什么?
重心已经不在模型上了AI 的重心一直在往模型之外漂移:
Prompt Engineering —— 你发送的文字Context Engineering —— 模型看到的一切,不只是你的指令Harness Engineering —— 模型外面的代码,跑工具、管状态、处理错误Loop Engineering —— 驱动整件事向目标前进的自主循环每一层包裹着前一层。你不是不再关心 prompt 了,你只是意识到 prompt 只是一个大得多的系统里的一小块。
LangChain 把这总结得很干净:Agent = Model + Harness。如果你不是模型,那你就是 harness。
而下面这个发现应该重塑你的优先级:
Harness 现在比模型更重要。
有团队保持模型不变,只改了外面那层代码,就从基准测试的中游跳进了前五。同一个大脑,不同的循环。
Loop Engineering 就是构建大脑所运行的那个环境的学科。
 难点一:知道什么时候停下来
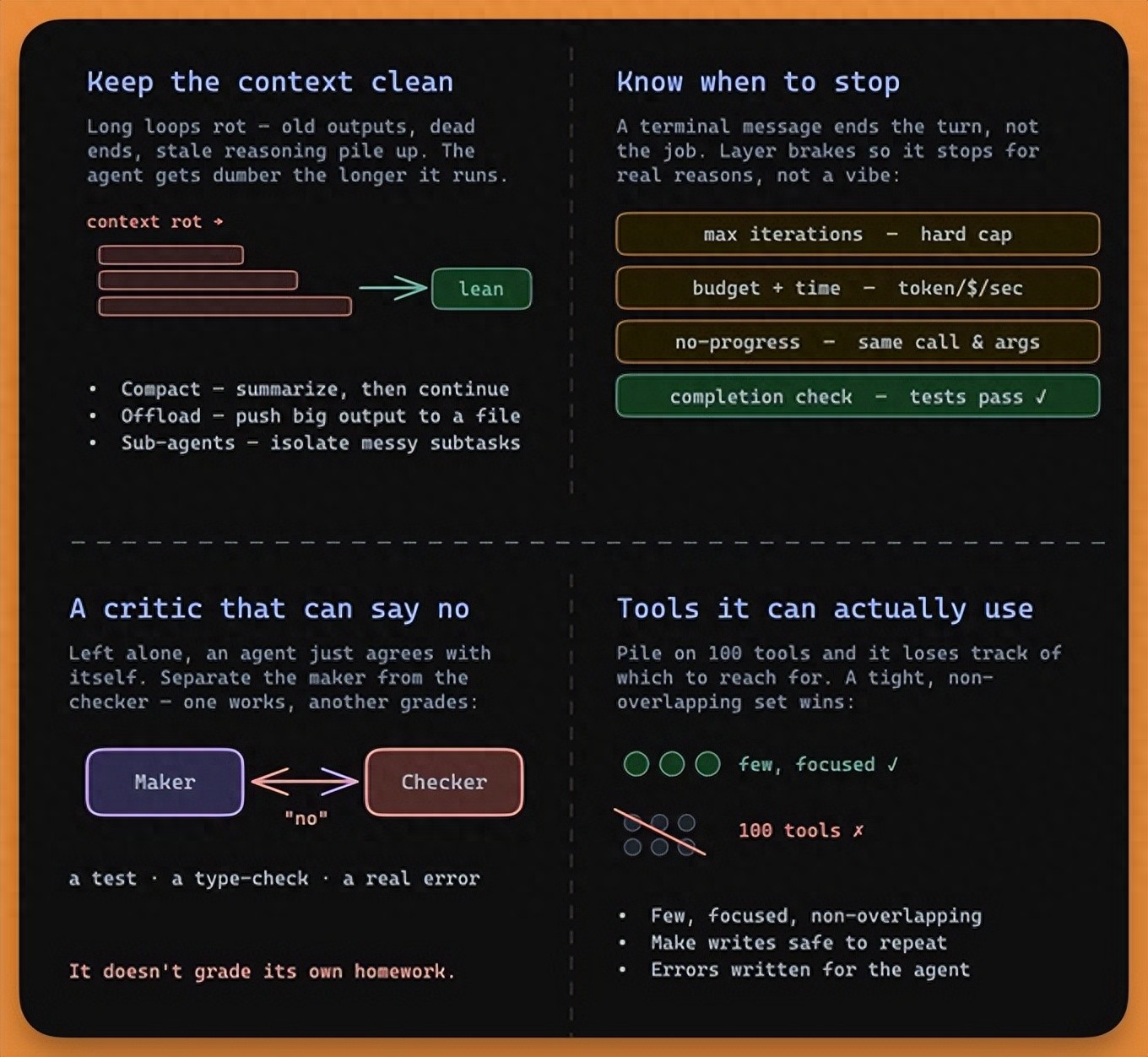
难点一:知道什么时候停下来这是没人警告你的问题。
当 Agent 不再请求工具时,它结束了自己的回合。但这不等于完成了任务。
想象一个编程 Agent。它写了几行代码,环顾四周,看到有些进展,然后宣布「做完了」。测试还在报错,它已经单方面宣告胜利。
终端消息结束的是回合,不是任务。
把这两件事混为一谈,是循环出错最常见的方式。
好的循环为正确的原因停下来,所以你需要叠好几道刹车:
最大迭代次数 —— 硬上限,防止卡住的 Agent 永远跑下去预算和时间限制 —— token、金钱、秒数的天花板无进展检测 —— 如果它用同样的参数重复调用同一个工具,那就是在空转真正的完成检查 —— 一个自动化的条件,证明工作确实做完了最后一项承载了全部重量。「完成」应该意味着测试通过了,而不是 Agent 自己觉得干得不错。
难点二:保持上下文干净长循环从内部腐烂。
Agent 跑的轮数越多,上下文里堆的垃圾就越多——旧的工具输出、死胡同、过期的推理。模型性能随着这堆东西的增长而下降。这个领域把它叫做 context rot(上下文腐烂)。
循环会让它螺旋恶化。腐烂的上下文产生更差的决策,更差的决策增加更多噪音,噪音进一步腐蚀上下文。人们管这叫「末日循环」,你感受过的——Agent 跑得越久反而越蠢。
对抗它的方式是把上下文当预算管,别当垃圾桶:
压缩(Compaction) —— 对话太长时做摘要,从摘要继续卸载(Offloading) —— 把巨大的输出推到文件里,只保留需要的切片子 Agent(Sub-agents) —— 把一团乱麻的子任务甩给独立 Agent,只让干净的结果回来本能是「全留着,万一用上」。本事是「知道该扔什么」。
难点三:Agent 真正能用的工具循环的好坏,取决于里面的工具。
堆一百个工具,Agent 就记不清该够哪一个。一套紧凑的、聚焦的、不重叠的工具才是赢家。Anthropic 的经验法则很锋利:如果人类工程师都不能确定该用哪个工具,Agent 更没可能。
有两件事比人们预想的更关键:
让写操作可以安全重试。 循环会重试,如果一个被重试的「创建客户」调用又创建了一个客户,你会醒来面对重复记录和双重账单。任何改变状态的操作都必须安全到可以调用两次。
为 Agent 写错误信息,不是为人。 一个好的错误信息会告诉 Agent 下一步该做什么。在一个工具上线前,先问一句:一个 LLM 读到这个错误信息,能知道下一步动作吗?
在循环里,错误不是死胡同,是下一条指令。
难点四:得有个能说「不」的东西自主循环有一个安静的失败模式:独自跑的 Agent 倾向于同意自己。
整场辩论里最尖锐的评论一针见血:设计循环是一半工作,另一半是往循环里放一个能说「不」的东西——一个测试、一个类型检查、一个真正的报错。
没有批评者的循环,就是一个 Agent 在对自己点头。
修复方案是把「做事的人」和「检查的人」分开。一个模型干活,一个不同的检查——通常是另一个模型或者硬性测试——来打分。工人不改自己的作业。
真正的转变现在 Cherny 那句话就说得通了。
Prompting 是你一步一步地操纵 Agent。Loop Engineering 是你构建操纵它的系统,然后退后一步。
你的工作从「下指令」变成了设计三样东西:
目标 —— 写成 Agent 可以自己核验的成功标准循环 —— 有合理的刹车,让它在该停的时候停验证器 —— 让「完成」是被证明的,不是被宣称的Andrej Karpathy 准确地抓住了这个心态。不要告诉模型做什么,给它成功标准然后看着它跑。他让研究循环通宵跑——改脚本、跑测试、保留有效的、丢弃无效的——自己全程不在循环里。他只设置一次,然后按下启动。
这就是整件事的核心动作。你不再是那双干活的手,你变成了设计机器的人。
从哪里开始你不用第一天就搞一个通宵跑的自主 Agent。渐进地来:
从基础循环开始,立刻加上最大迭代上限、超时和花费天花板用自动化检查来定义「完成」,在你动手之前就定好,而不是事后的感觉保护上下文。压缩长跑、卸载大输出、隔离混乱子任务审计你的工具。保持少而聚焦,让写操作安全可重试,重写错误信息让 Agent 能对它们做出反应往循环里放一个批评者。只有当你信任那个说「不」的东西之后,才真正放手上路最后的话Loop Engineering 不是你安装的一个框架或工具。它是一种精力投向的切换。
模型正在变成商品。模型外面的循环,才是真正工程化的地方。
最好的构建者不再问「我该让 Agent 做什么?」,他们开始问「什么样的系统可以在没有我的情况下做到这件事?」
把这个问题回答好,你也会停止写 prompt。