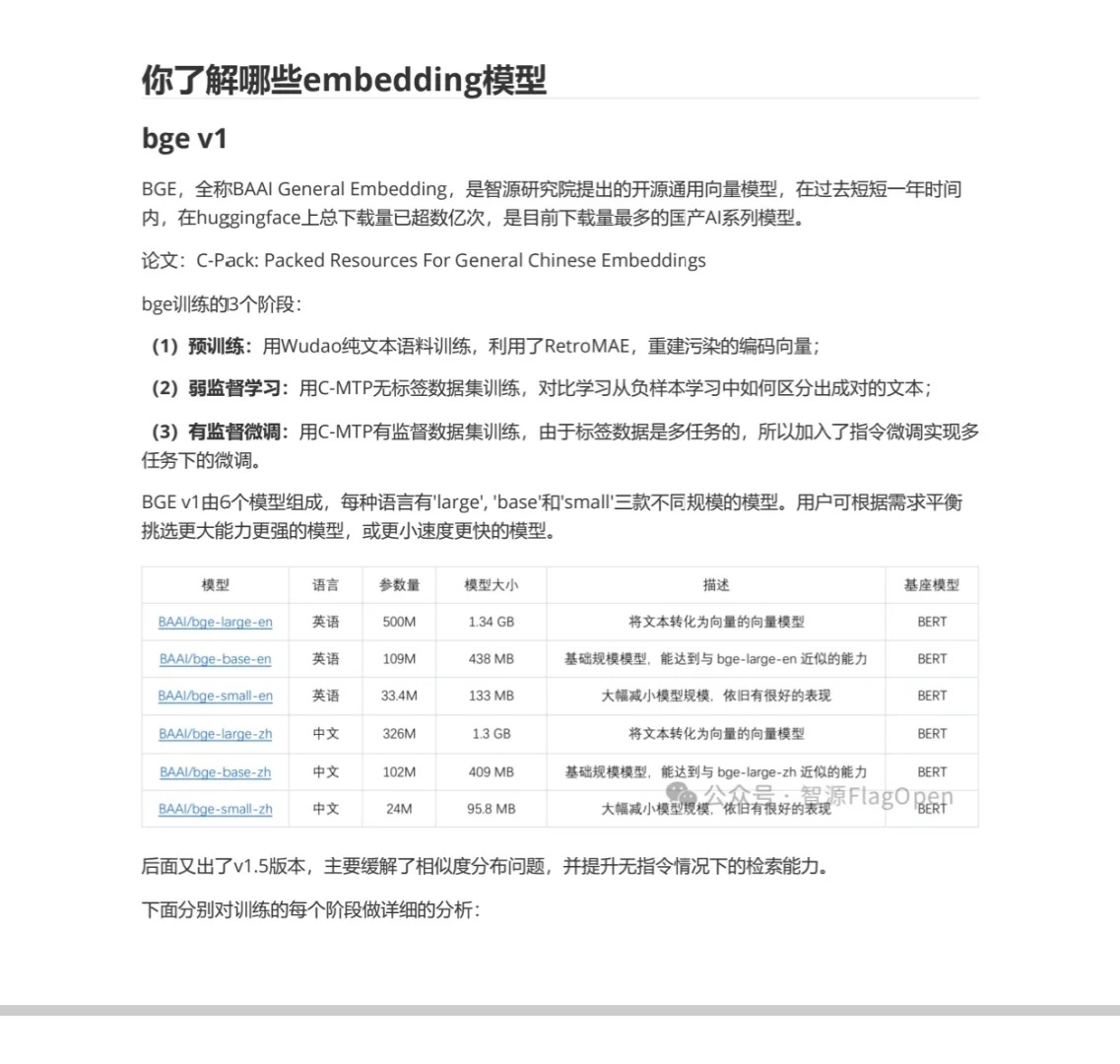
[仙女R]bge模型,全称BAAI General Embedding,是智源研究院提出的,bge v1版本的训练分为3个阶段:
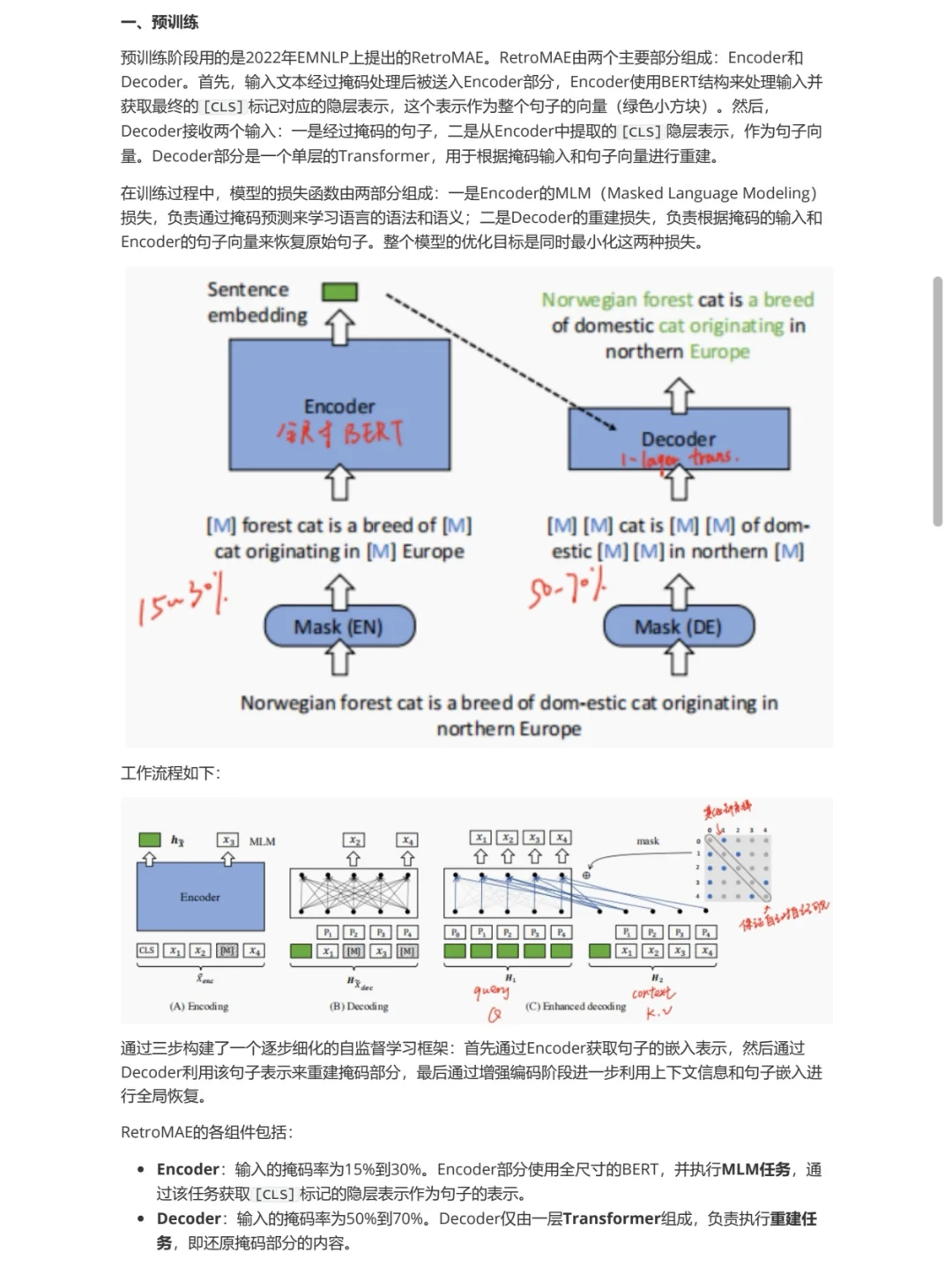
[辣椒R]预训练:用Wudao数据集纯文本语料训练,利用了RetroMAE,重建污染的编码向量;
[辣椒R]弱监督学习:用C-MTP无标签数据集训练,对比学习从负样本学习中如何区分出成对的文本,在这一步中使用in-batch负采样+大的batch size的方法避免了挖掘难负样本。
[辣椒R]有监督微调:用C-MTP有监督数据集训练,由于标签数据是多任务的,所以加入了指令微调实现多任务下的微调。在这一步中使用了ANN-style采样策略来挖掘难负样本。
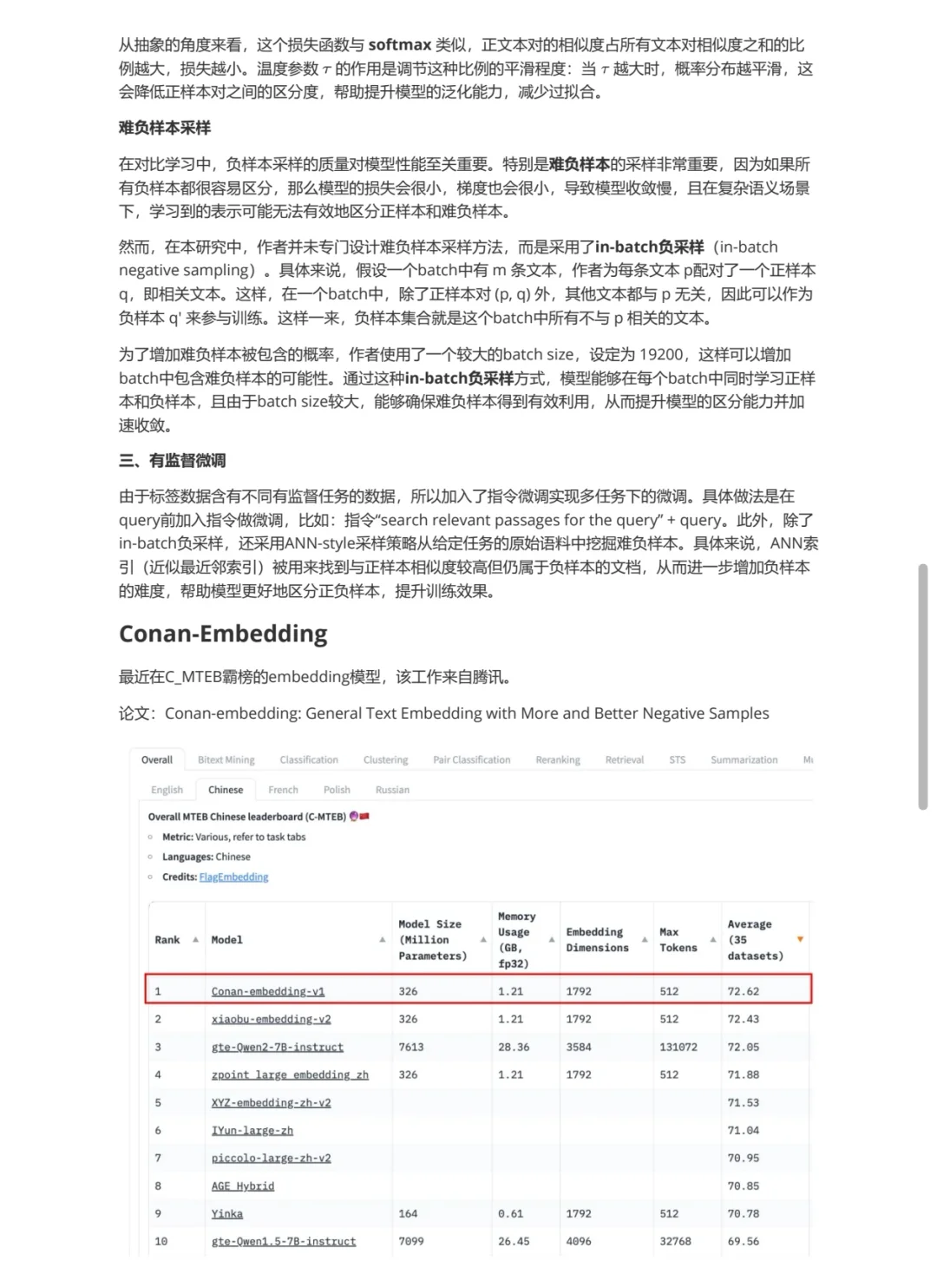
[仙女R]conan-embedding,腾讯提出的最近在C_MTEB霸榜的embedding模型。主要通过挖掘更多质量更高的负样本的方法提升了embedding模型的能力。训练过程可以分为两个阶段:弱监督预训练和有监督微调。
[辣椒R]其中弱监督预训练阶段主要收集了大量高质量的负样本,使用了一些过滤方法,比如使用bge-large-zh-v1.5模型对数据进行评分,过滤掉得分低于0.4的低质量数据。然后就是常规的in-batch对比学习训练。
[辣椒R]在有监督微调阶段,将训练数据分为retrieve和STS两种任务类型,使用了两种优化技巧:
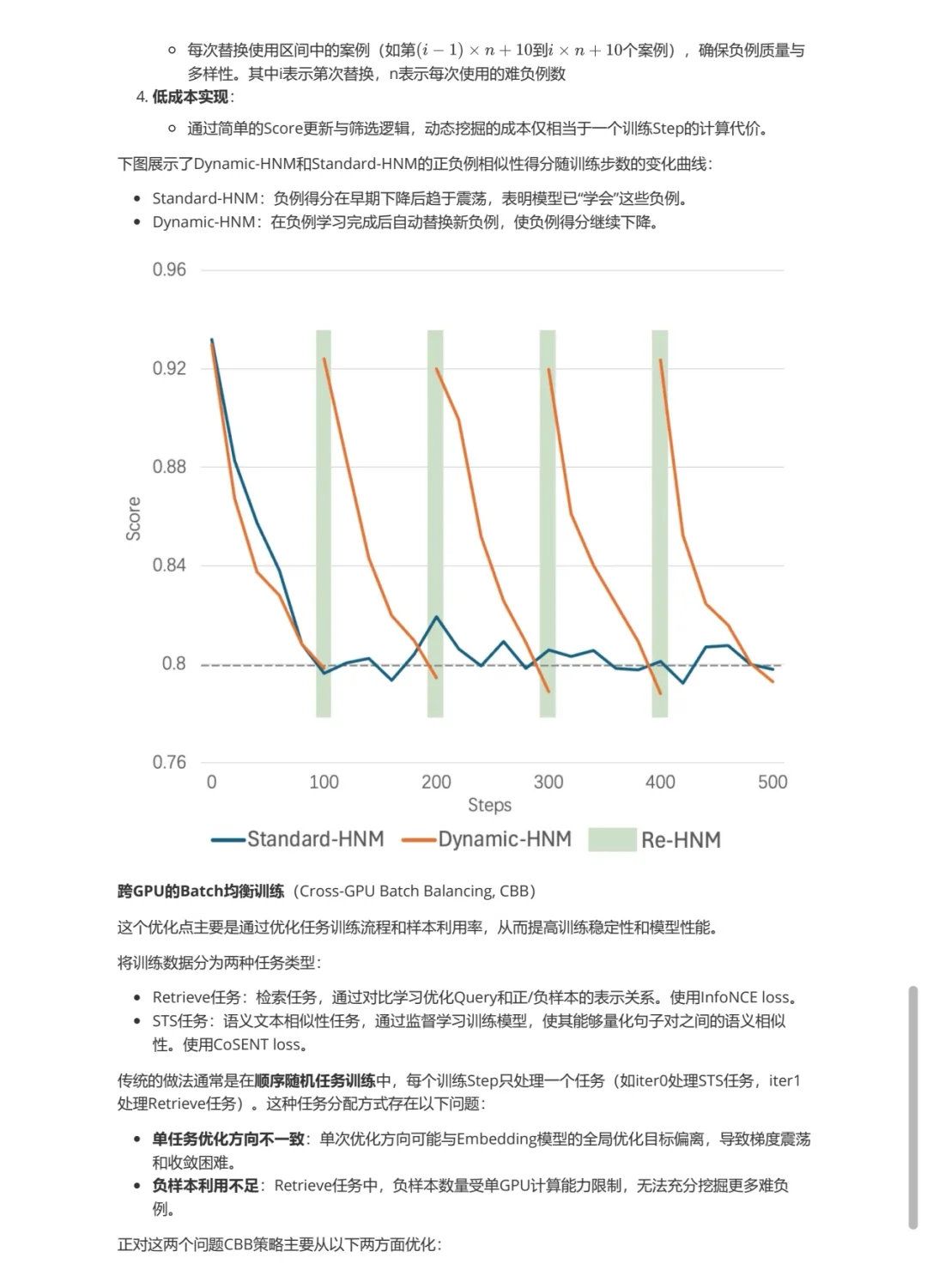
[黄瓜R]动态硬负样本挖掘:每经过一段时间,重新计算在最新模型下hard negative的得分,如果得分太低,就重新挖掘。
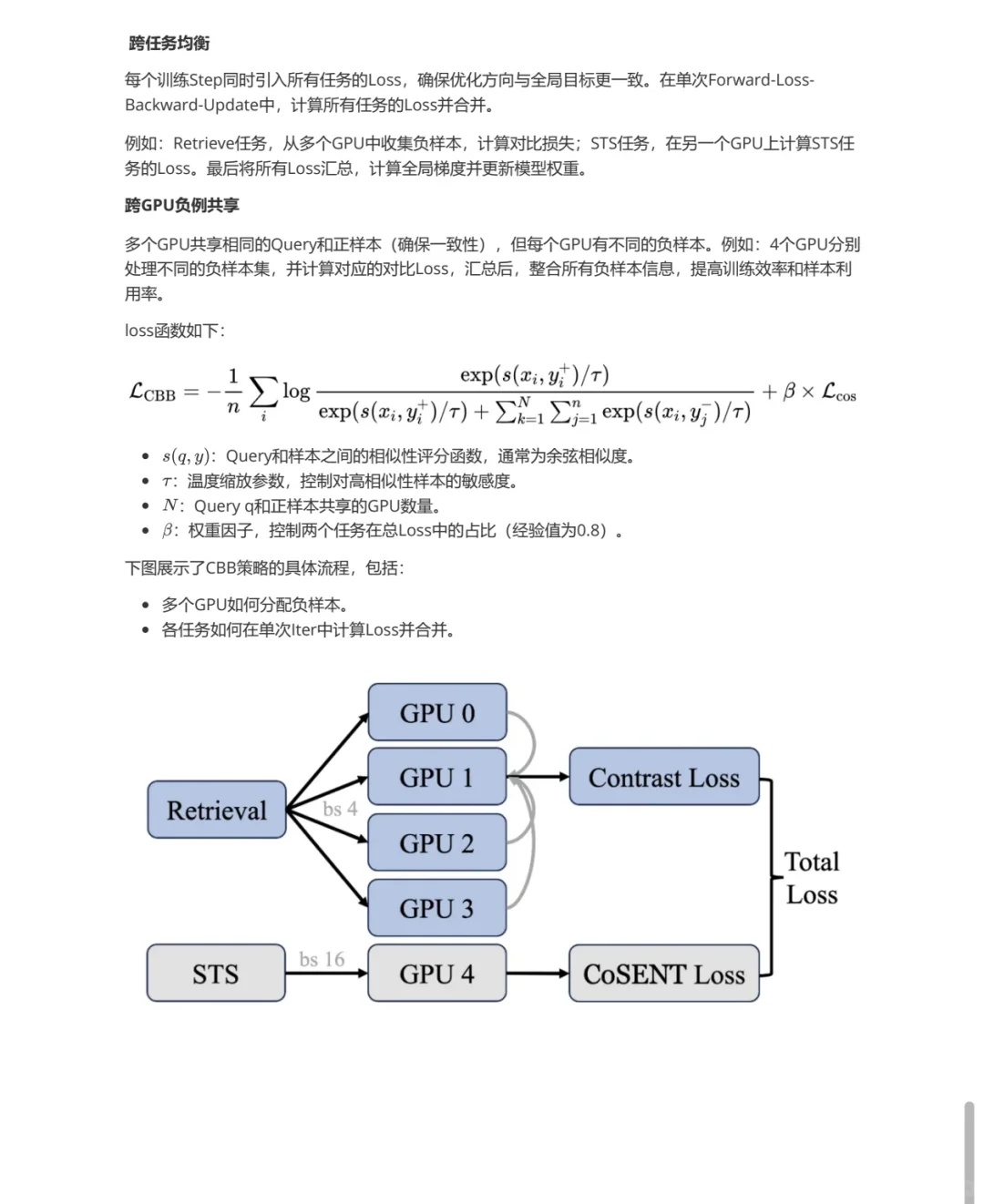
[黄瓜R]跨GPU批次平衡损失:提出了联合损失函数,平衡retrieve任务和STS任务的训练损失,避免模型优化方向不一致。