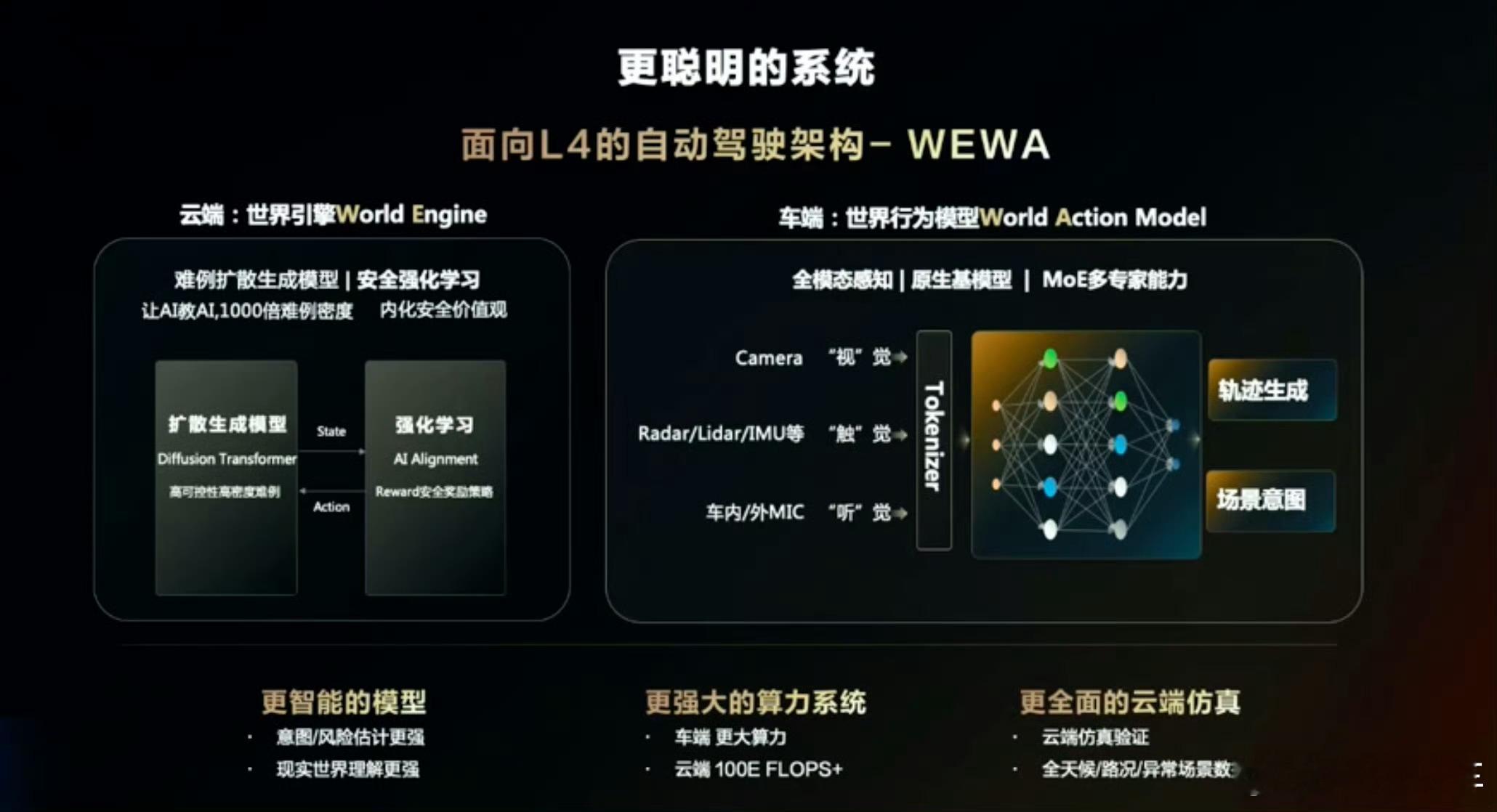
华为乾崑智驾ADS 4将会在尊界S800上首发,采用全新的WEWA架构——世界引擎(World Engine)+世界行为模型(World Action Model)。今天咱们从“MoE多专家能力”切入来聊聊,这也正是当前大模型架构发展的核心方向之一。
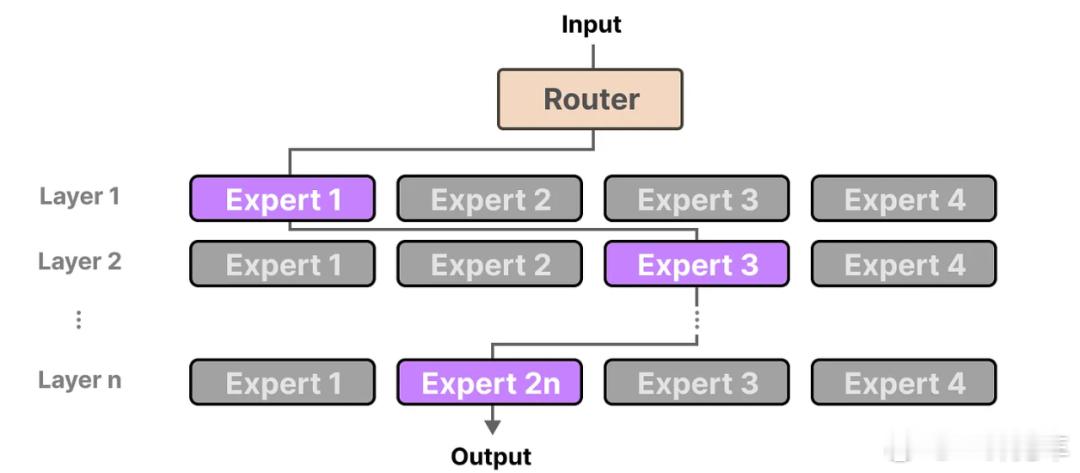
通俗地说,MoE(Mixture of Experts)模型就像在一个大模型中“术业有专攻”:云端对“路口场景专家”、“雨雪天气专家”等不同子网络进行定向强化训练,车端则根据实时场景仅激活1–2位最匹配的专家,既节省算力,又确保了推理质量与速度。举个例子,一层楼原本是一个人包办一切的“一言堂”,而现在分成了8位专家,根据不同的场景,只调用1-2位专家,讨论出最佳结果。
具体而言,首先AI模型的神经网络都是通过层层结构依次传递信息,逐步得出最终结果。与一般的端到端模型对比,MoE架构的优势主要体现在以下两方面:
1、我们都知道模型越大效果往往越好,但同时算力开销也会更大。“端到端”是一种结构,而当参数量达到大模型水平,对车载计算资源的需求极高。而车端的算力有限,对响应速度的要求却又非常高,整个模型的推理时间如果从0.2秒增加到1秒,显然是难以接受的。
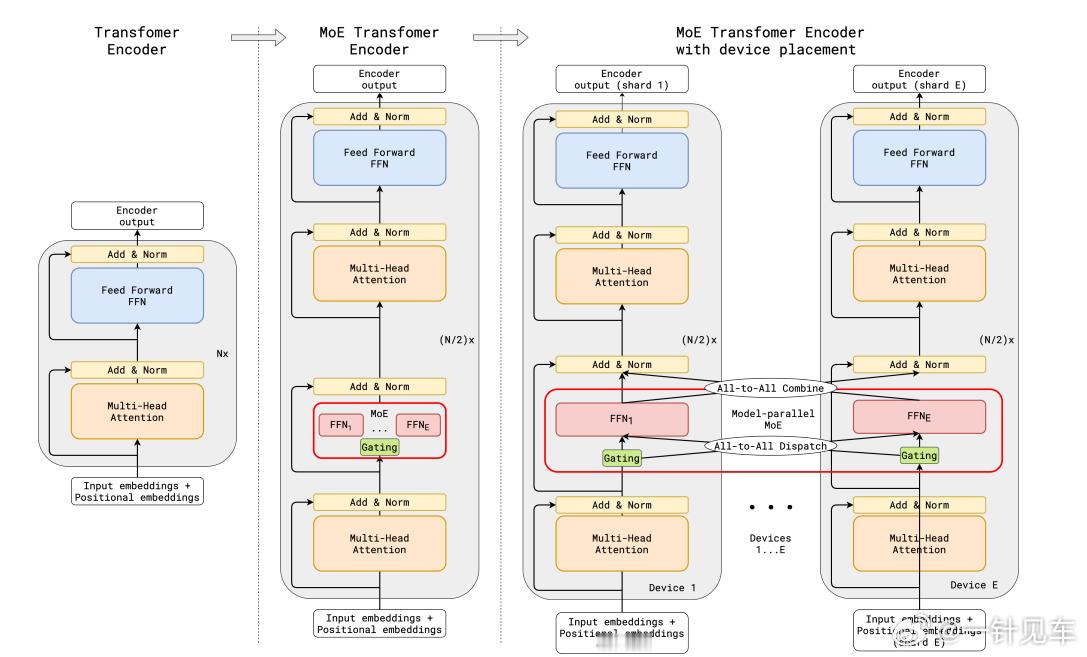
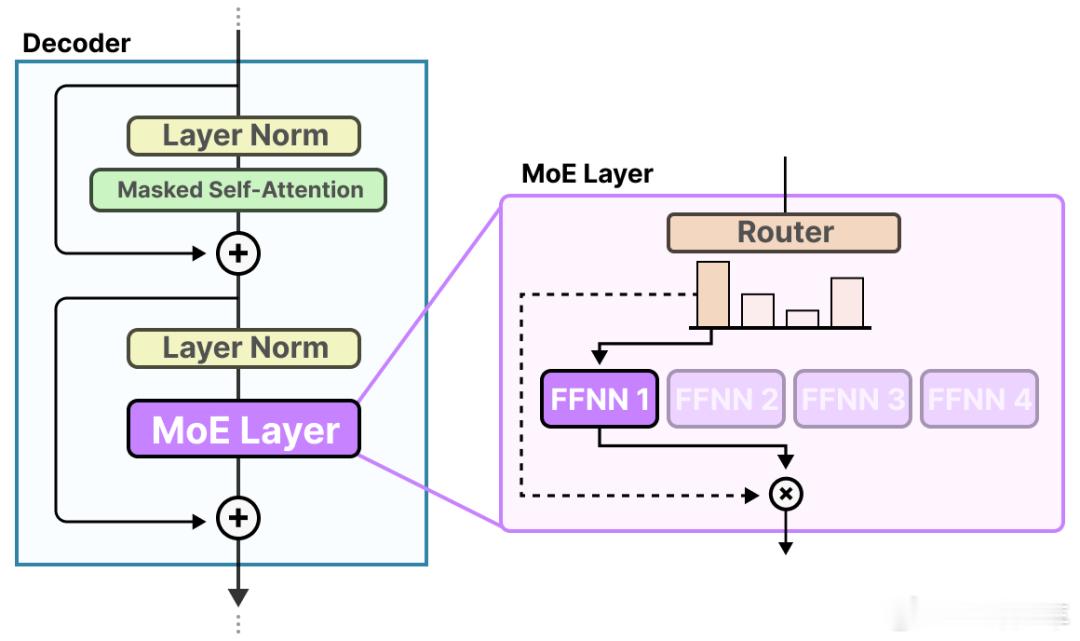
这时候,我们引入MoE多专家网络,这个“多专家”的含义并非增加一堆独立的小模型,而是将传统Transformer中的全连接前馈网络(FFN)层替换为“多个专家子网络+一个路由器”。在推理时,路由器为每个输入样本“选举”最合适的专家,激活机制从“全量计算”变为“稀疏激活”。例如一个总参数量8B的MoE模型,在8位专家中只调用2位,推理成本即可降至等效2B参数模型的水平,从而显著加速车端响应,效果立竿见影。
2、众所周知大模型是“黑盒”,训练中模型参数全局更新,强化训练优化 A 场景时,却有可能导致 B 场景的性能回退。那么如何应对这种“牵一发动全身”的问题,确保多场景的性能都得到提升呢?
“世界引擎”和MoE架构可以说是天生一对。云端借助扩散生成模型技术,高度可控地生成鬼探头、侧前方 Cut-in 等极端与长尾场景,实现“AI 训练 AI”的海量强化学习。云端训练时,针对各专家最擅长的场景进行定向强化;车端推理时,路由器按场景激活对应专家,确保新场景学习不会“污染”其它专家。既有利于泛化,让不同的专家更专注于对应任务,又能不断提升每个专家的能力。
从 L2 辅助驾驶迈向 L3/L4 全自动驾驶,需覆盖难以预见的长尾与极端场景。借助世界引擎生成的超高密度难例和“安全奖励”策略,MoE 架构在安全性上实现数量级飞跃,为高级自动驾驶的可靠性奠定坚实基础。
总而言之,MoE架构具备强泛化性和稳定性,能够节省算力、加快推理速度,并支持灵活的专家添加与训练。结合云端的世界引擎进行强化学习,MoE架构为自动驾驶的发展提供了坚实的技术支撑。随着技术的不断进步,MoE有望引领我们走向更高水平的自动驾驶,值得期待。