DeepSeek R-1更新,让人更期待R2的“雄心与真诚”
R2没来,R1-0528来了。
这款以半年前的DeepSeek V3 Base模型为基座,在后训练阶段投入更多算力的升级版推理模型,同样非常能打,让DeepSeek稳居全球第二AI实验室的位置。宽松的MIT许可也没变化,兑现了向全球技术生态提供强大开源模型的承诺。这更让人期待V4与真正的R2了。
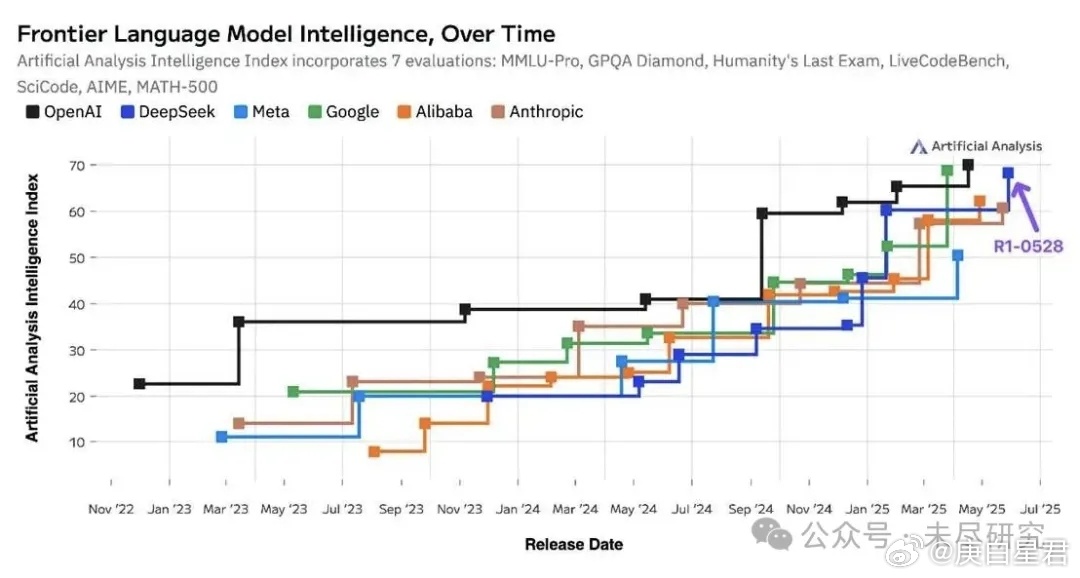
在多项基准测试中,DeepSeek-R1-0528在数学、编程和通用逻辑上的性能,足以媲美最强闭源模型o3和Gemini 2.5 Pro,也超越了最强开源模型Qwen3-235B。它还在幻觉改善、创意写作、工具调用与前端代码生成上有所提升。
独立AI分析网站Artificial Analysis很快更新了领先AI大厂模型智能的排名。DeepSeek无论在性能提升还是迭代速度上,都紧紧咬住了OpenAI。差不多两年前,奥特曼与伊莱亚被问及,开源模型能否赶上GPT-4时,还非常自信地认为,即使赶上了,两者在真正的前沿模型上的差距也会越拉越大;当时,DeepSeek正式成立刚刚满月。
DeepSeek同时发布蒸馏版的R1-0528-Qwen3-8B,在数学测试中的表现,与比它大数十倍的Qwen3-235B相当,提升了学术界与工业界对最先进AI的可访问性。DeepSeek官方公众号特地将这一重要意义加黑加粗了。
在DeepSeek社交媒体平台X的官方账号下,开源社区对它朴素的版本命名规则给与好评,甚至认为在自己心里,它就是R2了。还有不少开发者在评论里许愿,要求下一代大模型要有更大的上下文窗口,原生的多模态功能,等等。
不妨结合DeepSeek的“历史”与开源社区的期待,大胆推测一下它的下一代模型会是什么样吧。
首先,R1-0528从一开始就不是R2,也不是R-1.5。DeepSeek对模型的命名,有其“潜规则”。要让“版本号”小升级,至少要有不同Base(基座)模型级别的迭代与功能的合并。
2个月前,V3-0324更新,也没有命名为V-3.5。因为它与之前的V3一样,使用了同样的Base模型,仅改进了后训练方法。这次的R1-0528,则主要是在同样的Base模型上,投入了更多的后训练算力。
但是,DeepSeek是发布过V-2.5的。这是一款融合了通用与代码能力的全新开源模型。从V-2升级到V-2.5,涉及到Base模型的切换与模型的合并。2024年5月,初代DeepSeek-V2发布;6月,DeepSeek-Coder-V2发布,6月底,V2-0628上线,用Coder-V2的Base模型,替换原有的Chat的Base模型;7月,对齐优化的Coder-V2-0724上线;9月,V2-0628与Coder-V2-0724在相同Base模型的基础上合并,即V-2.5。12月10日,V2.5-1210上线,宣告V2系列收官。两周后,下一代的DeepSeek-V3开源,官方称其为“V3的首个版本”。
第二,成熟度最高的代码能力,已经融合进去了;下一代模型很可能就是原生多模态。
在V系列基础大型语言模型之外,DeepSeek的团队一直在各个分支上尝试更多元的探索,包括数学模型Math以及专门用于数学定理证明的模型Prover,混合专家视觉语言模型VL2以及自回归的统一多模态理解与生成模型Janus等。
这体现了DeepSeek的“长期主义”与言行一致。代码与数学,多模态与自然语言本身,三者正是DeepSeek创始人梁文锋押注的三个方向,“数学和代码是AGI天然的试验场,有点像围棋,是一个封闭的、可验证的系统,有可能通过自我学习就能实现很高的智能”。
DeepSeek证明了自己可以很好地合并模型;而且,MoE又天然的是多专家的模型。也许最终,这三个押注方向都会合流。尤其是多模态,一直都是开源社区对DeepSeek的V4或R2的期待;至少在DeepSeek下一代模型的完整迭代周期内实现。闭源的OpenAI、谷歌已经都这么做了。
第三,下一代基础模型的推出,至少对应着新的注意力机制创新的工程化与商业化,也越来越对应人类对“记忆”该有的样子的理解。这种将“规模竞赛”进一步扭转为“效率竞赛”的努力,事实上变相为“扩展定律”续了命,有利于在更高效的算力支出上研发更高参数规模的大模型,同时也为应用场景进一步降低了全面采用AI的成本。
这正是贯穿DeepSeek主力模型迭代始终的主线。DeepSeek-V2对传统Transformer架构的自注意力机制进行了全方位的创新,提出了MLA(多头潜在注意力)机制。美国知名半导体分析机构semianalysis敏锐地感觉到,这种架构创新将对OpenAI造成麻烦。V3则首创了一种无辅助损失的负载均衡策略,并设定了多token预测训练目标以提升性能,以及开创性的适用于FP8精度的训练框架。
最有希望引入V4或R2模型的,也许要数DeepSeek年初提出的NSA(原生可训练稀疏注意力)机制。它能带来的,也正是用户目前迫切想要的长上下文。更长的上下文,意味着仓库级代码生成、多轮智能体间互动以及科研深度的推理能力。但是,注意力计算在总计算成本中占比,也会随着要处理的上下文的序列的增长而急剧增长。而目前很多稀疏注意力机制只是在特定阶段受限起效。
NSA支持端到端的训练,而且硬件对齐友好,通过将文本压缩为粗粒度语义块(压缩数据量)、动态筛选关键片段(减少计算量),并结合局部滑动窗口(限定关注长度),既保留全局理解,又减少冗余计算。DeepSeek团队已经在27B(3B激活参数)的MoE架构模型上做了多项测试,提升显著。
V4还可能会带来更多注意力机制创新。DeepSeek团队成员提到了一项名为BSBR(带块检索的块稀疏注意力)的技术,短期记忆用传统方法处理(块内递归),长期记忆则用全局注意力机制捕捉(块外全局注意力),保存在 SSD 硬盘里,需要时快速检索到GPU上。
第四,DeepSeek之于整个AI生态,尤其是中国的AI生态的意义,不仅仅在于它会回答下一代模型怎么样,还会回答适配下一代模型的基础设施怎么样。
去年至今,它先后用两篇论文,分别详细介绍了如何通过软硬件协同优化,用A100与H800搭建出“平民版”的智算集群。H800集群已经训练出了V2与V3,V4会拥有自己的全新的基础设施吗?
在这个意义上,今年年初NSA论文里提到的“基于Triton实现硬件对齐的稀疏”的细节,让人回想起去年这个时候,微软、Meta的工程师忙着为Triton优化。
这是专为神经网络计算设计的跨平台兼容的编程语言和编译器,提供了一种从CUDA中解耦出来的可能性。当Meta发布第二代MTIA时,其工程师表示Triton “高效”且“与硬件无关”。不过,在中国以外的市场,大家还都没有被逼到不用CUDA只用Triton的地步。
此外,开源社区也有人好奇,随着后训练的比重越来越大,会出现新的针对强化学习优化的AI基础设施吗?
25个月前,DeepSeek在前身幻方量化的公众号上发表了其AGI征程宣言,引用到“务必要疯狂地拥抱雄心,同时要疯狂地真诚”。那么,也让我们期待DeepSeek的下一代大模型会更具“雄心”与“真诚”。