AI 挑战奥数 IMO 2025,结果扎心了
2025 年国际数学奥林匹克(IMO)刚刚落幕,多款大模型参与了这场“高智商”评测。
测试了 8 款主流模型,全部挑战 IMO 六道真题,结果显示:
· Grok 4 答对 3 题,但没有严格的推理过程;
· Gemini 2.5 Pro、字节跳动 Seed 1.6 各答对 2 题,并是仅有能完成第5题全流程推理的模型;
· OpenAI o3-medium、Claude Sonnet 等也只答对 2 题;
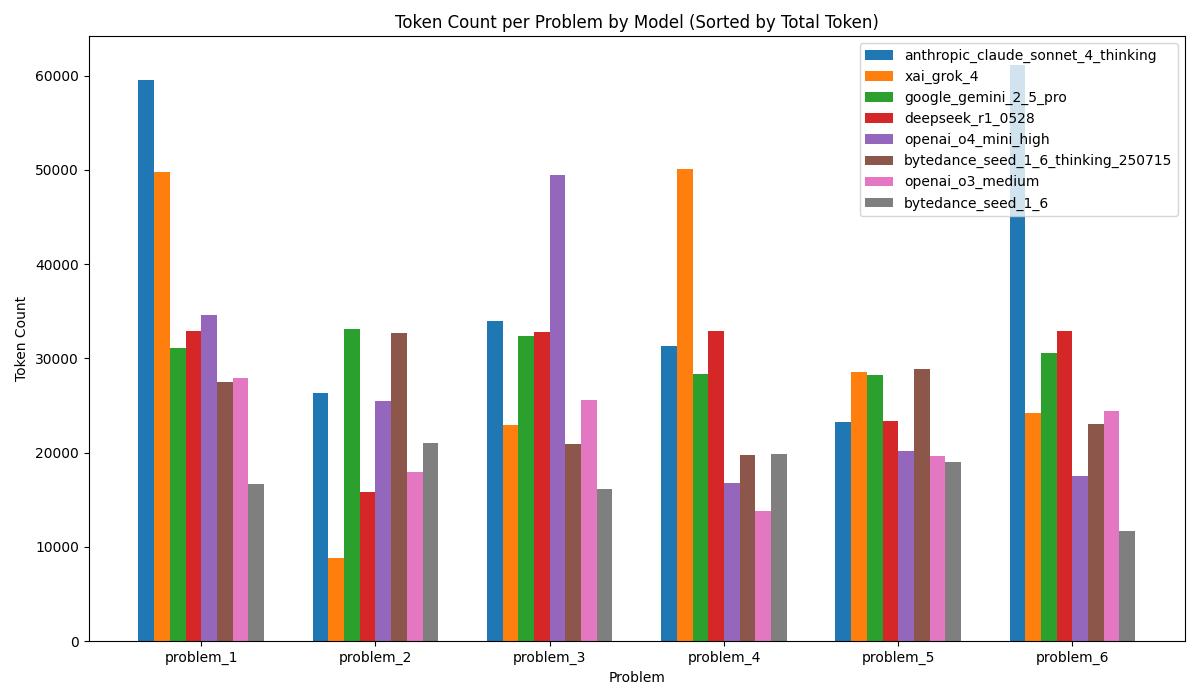
· DeepSeek R1 则因推理 token 限制(32K)直接失败。
结论扎实:正确答案 ≠ 数学能力。多数模型仅能给出“猜对”的部分解,难以写出严密推理与证明链条。
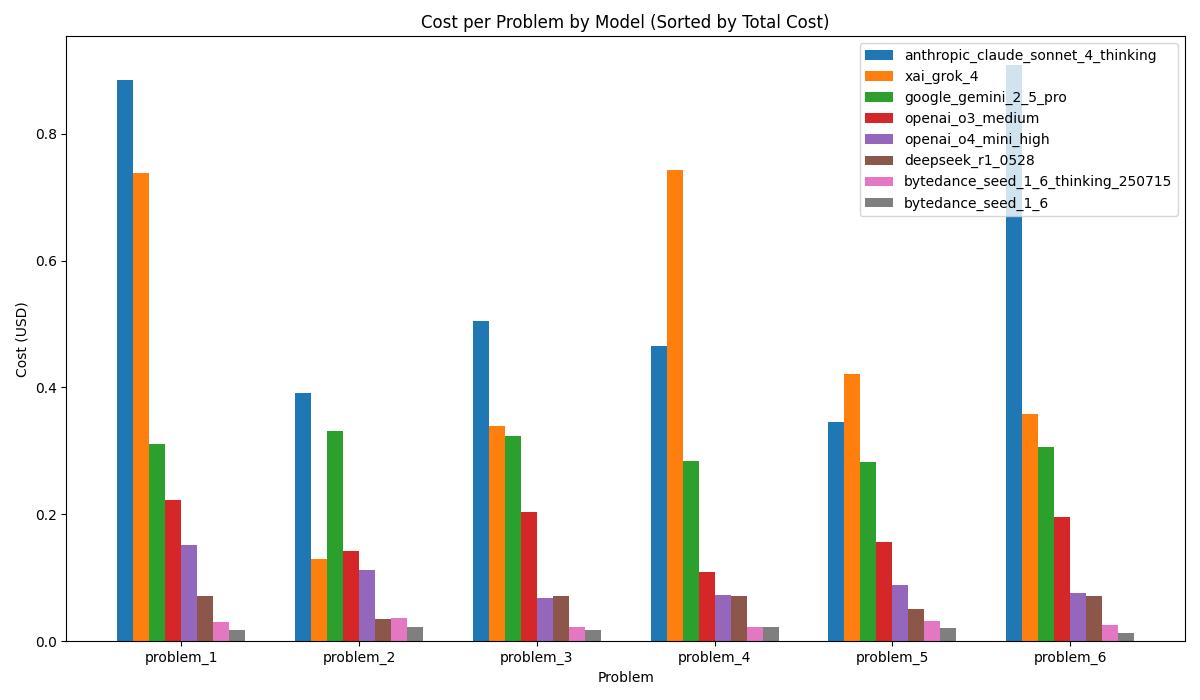
特别一提,字节的 Seed 1.6 成本优势明显($1.1/百万 tokens),比海外模型便宜一半,且在推理完整度上更具潜力。
想让 AI 真正进入数学科研和高阶教学场景,靠的不是模型“答对”,而是“讲清楚为什么对”——这才是目前大模型最大短板。
AI数学 IMO2025 大模型评测 Gemini 字节跳动Seed