#所有AI都将殊途同归##AI都在学习同一种通用语义#
所有的AI模型可能都殊途同归,最终学习到同一种“通用语义”?
Jack Morris的这篇博客,在这两天引发了讨论。他在博客强调了一个核心观点:压缩就是智能,可以把AI理解为一种“压缩”数据的过程。
听起来有点哲学,其实很实际。他的意思是:语言模型的任务(预测下一个词)本质就是在“压缩”人类语言的数据分布。谁能压缩得更好,谁就更聪明。
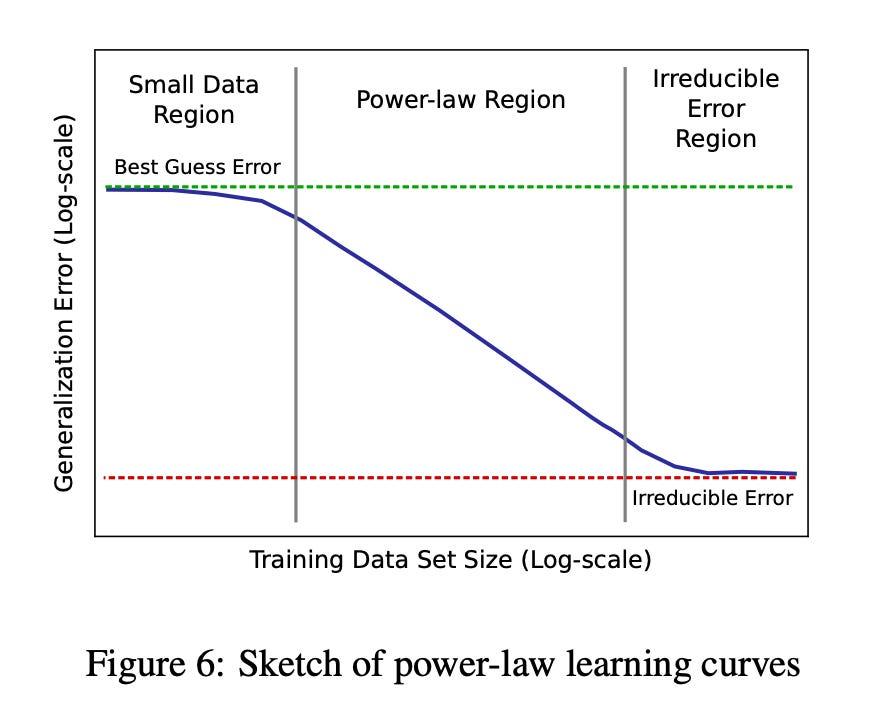
随着语言模型越来越大、越来越好,它们对世界的概率分布建模也越来越准确,这也就意味着更好的压缩能力。 【图1】
甚至有人认为,压缩可能是实现通用人工智能(AGI)的关键途径。
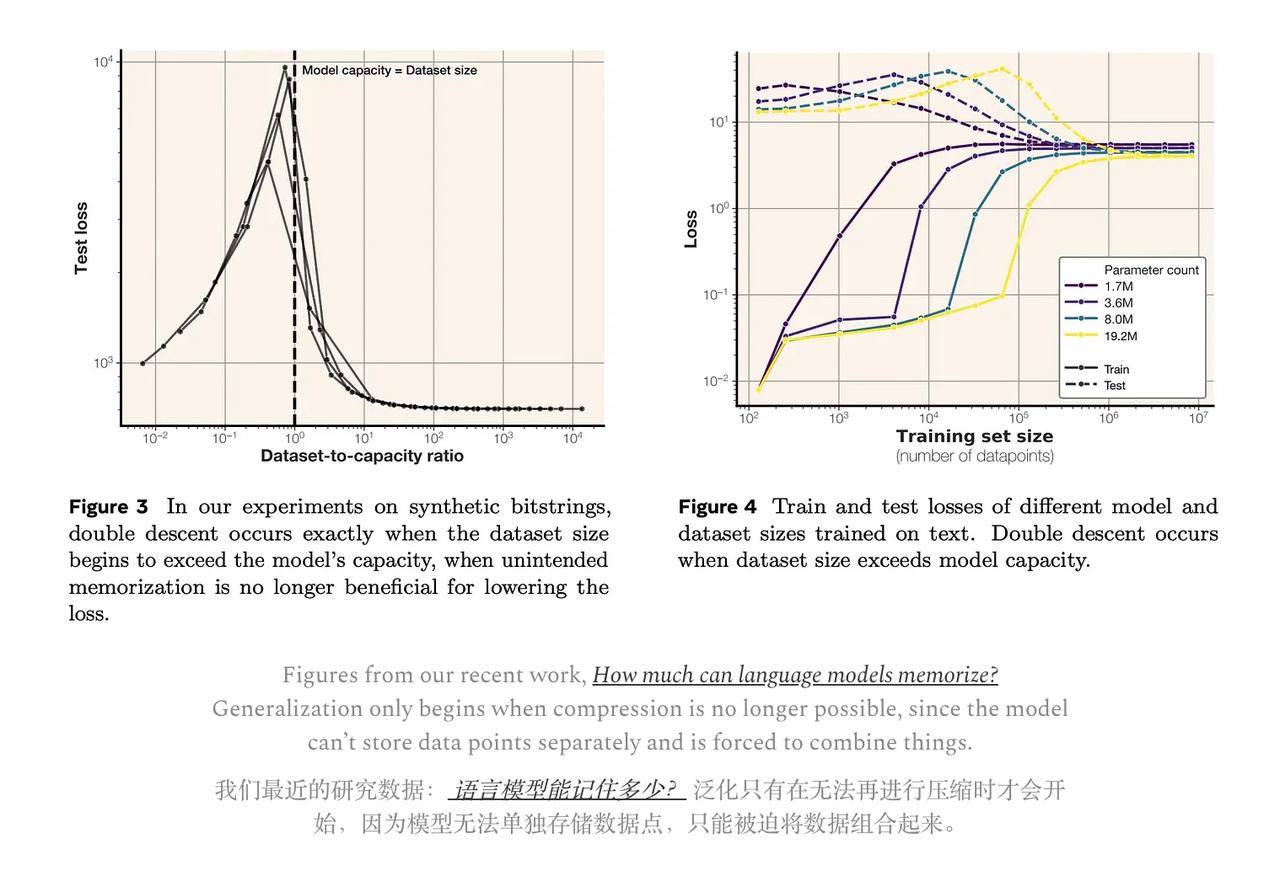
当模型被强制去“压缩”大量数据时,它就学会了泛化,而这种泛化方式,即使在不同的模型中,也往往是相似的。【图2】
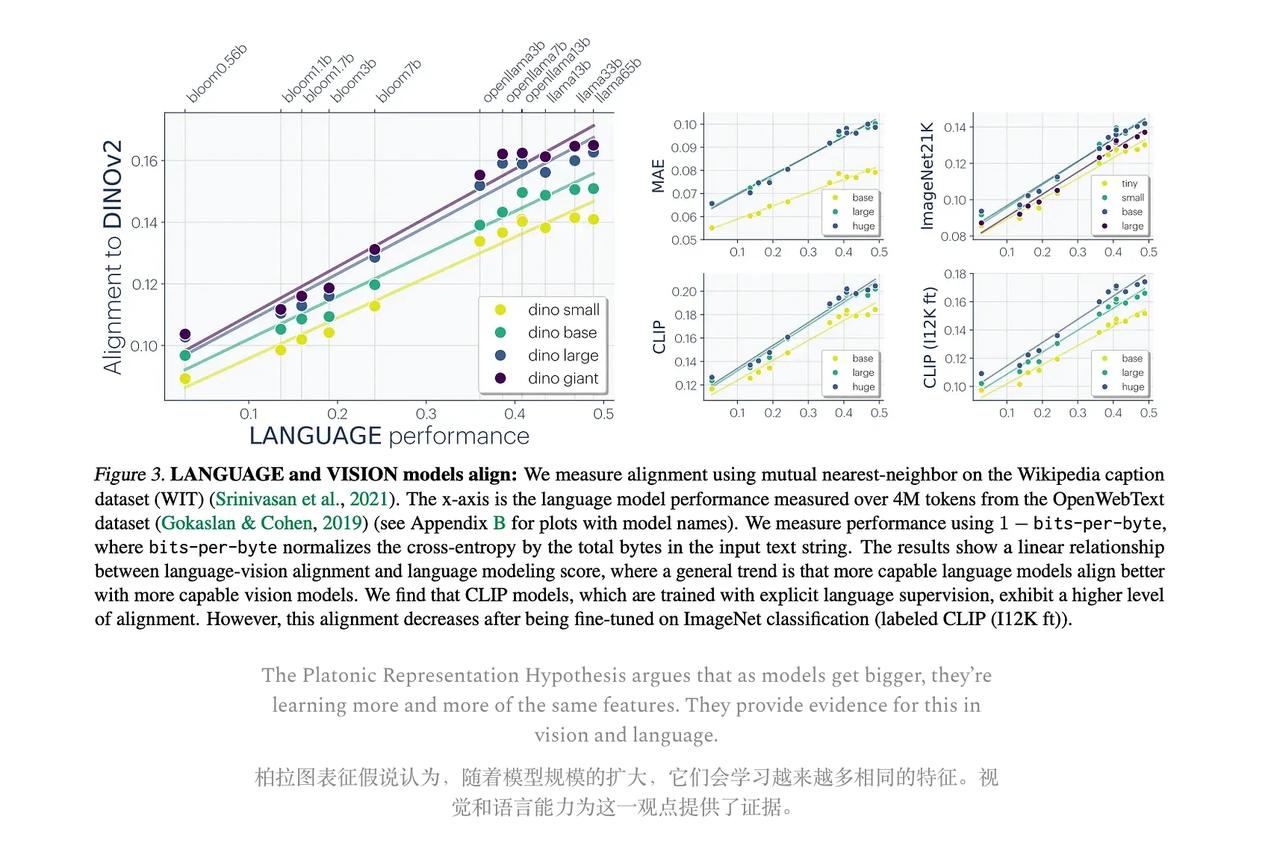
2024年,麻省理工学院的研究人员正式提出「柏拉图式表征假说」。
这个假说认为,不同的AI模型正在趋向于学习一种共享的底层表征空间。【图3】
就像我们人类对世界的真实模型只有一个一样,AI也在试图逼近那个“真实模型”。
随着模型变得越来越大、越来越智能、效率越来越高,它们之间的相似性也会越来越明显。
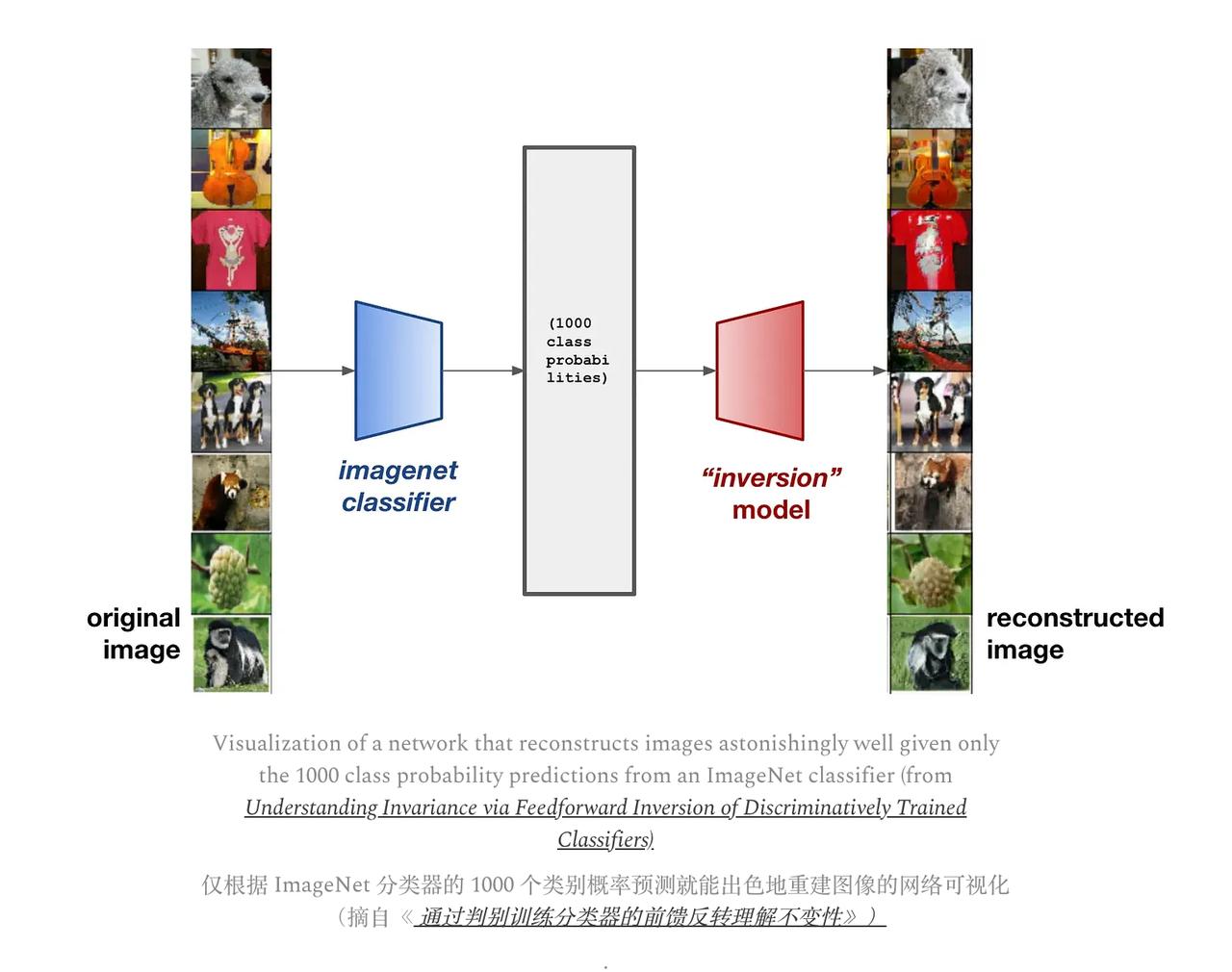
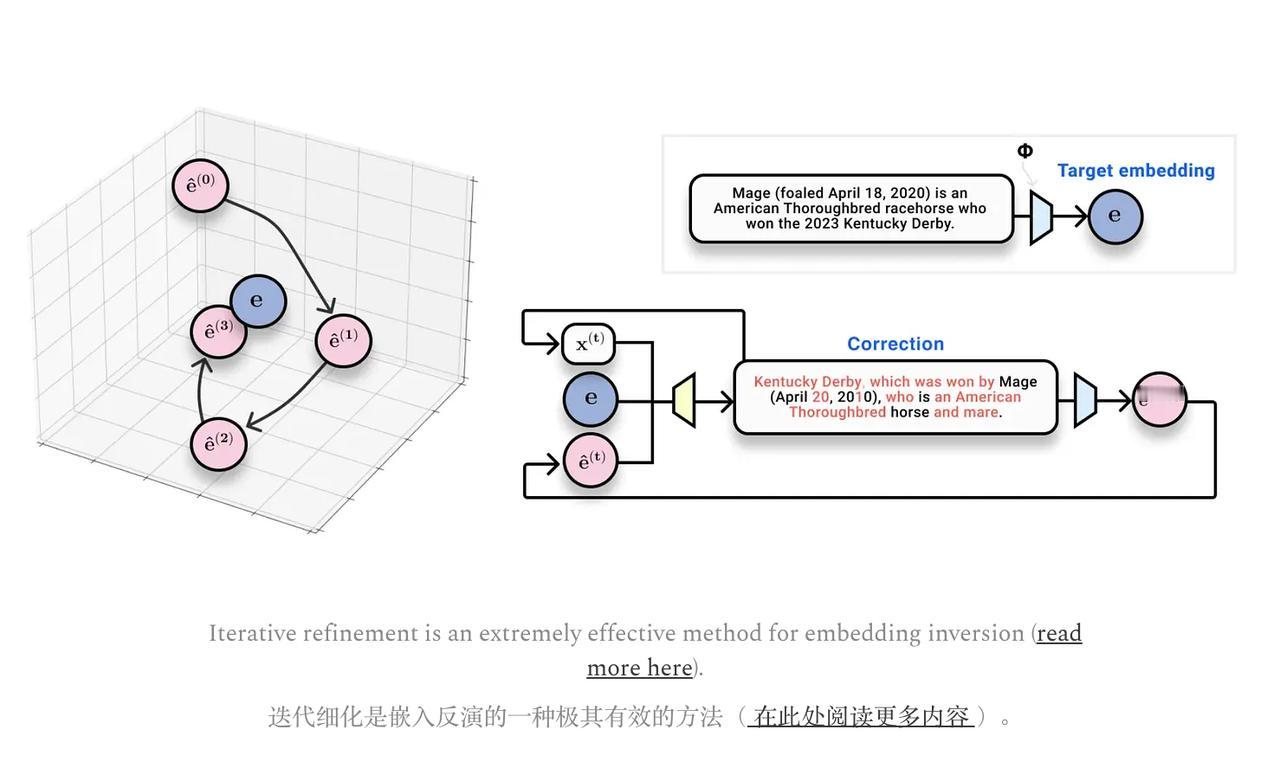
作者还分享了自己PhD期间研究的“嵌入反演”(embedding inversion)问题:能不能从神经网络输出的表征向量,反推出输入的文本?【图4】
这个问题看起来简单,因为嵌入向量数据量不小,但实际上非常困难。
因为嵌入是高度压缩的,相似的文本有相似的嵌入,所以很难精确区分。
后来他们通过一种迭代优化(类似学习型优化器)的方法,成功地以94%的准确率反演了长句子的文本。【图5】
虽然他们之前的反演方法很有效,但它只针对特定的嵌入模型,而且需要大量的查询。
这就引出了一个大胆的想法:如果柏拉图式表征假说成立,不同的模型都在学习相同的东西,那我们是不是就能构建一个通用的嵌入反演器,适用于任何模型呢?
他们通过将问题数学化,并借鉴了CycleGAN(一种无需对应数据就能在不同空间之间进行转换的模型)的思路,来对齐不同模型之间的嵌入空间。
经过艰苦的调试,他们成功实现了在无监督的情况下,将一个模型的嵌入转换为另一个模型,甚至无需知道单个数据点的信息!【图6】
这被他们称为“强柏拉图式表征假说”。
除了嵌入反演,其他领域也提供了柏拉图式表征假说的证据。例如,“可解释性研究”发现,即使是非常不同的模型,其内部的工作机制(比如“回路”)也具有非常相似的功能。 【图7】
还有一些研究发现,如果在不同的模型上训练稀疏自编码器(SAE),它们往往会学习到很多相同的特征。
最后,回到那个核心问题:所有模型真的越来越像了吗?
现在看起来,像的概率越来越高。
虽然还不能100%下结论,但随着模型越做越大、越聪明、训练数据越丰富、工具越好,我们应该会越来越接近这个“共同的大脑”。
未来,我们甚至可能通过大模型,破译古代文字、解码鲸鱼语言,甚至还原人类表达的最底层代码。