现在是时候认真看一眼迷你AI工作站了!如果说2025Q2以前大家还在试探性地拿7B、14B模型在AI PC上“玩票”,那么进入2025Q3年之后,随着AMD锐龙AI Max+ 395处理器的到来,越来越多的开发者和中小团队开始把迷你AI工作站当成真正的生产力工具——模型规模从7B、14B一路推到30B、70B甚至更高的MOE 120B,而且产品形态还从单台方案进一步发展为机架集群部署方案,这让更多企业构建出高效的AI计算中心。在这个市场中,铭凡MS-S1 MAX是少有的可以支持2U机架部署的产品,那么围绕着“AI计算中枢”的定位,铭凡MS-S1 MAX到底有多大能耐呢?

产品参数
操作系统:Windows 11家庭中文版(64位)
处理器:AMD锐龙AI Max+ 395(16核心32线程、最高频率5.1GHz)
内存:128GB LPDDR5X 8000四通道
硬盘:2TB PCIe 4.0 SSD(双M.2插槽)
GPU:AMD Radeon 8060S(2900MHz、40组计算单元)
前置接口:3.5mm音频接口×1、USB4接口×2、USB-A 3.2 Gen2接口×1,Dmic×2
后置接口:USB 2.0×2、USB-A 3.2 Gen2接口×2(10Gbps)、RJ-45网线接口×2、USB4 V2接口(80Gbps)×2、HDMI2.1 FRL接口×1、电源接口×1
尺寸:222.1mm(长)×206.3mm(宽)×77.1mm(高)
重量:约2.8kg
参考价格:21599元
外观设计3L小机箱,可卧可立铭凡这几年在迷你PC圈子里一个很明显的变化就是不再一味追求“越小越好”,而是愿意用3L左右的体积去换更强大的散热能力、扩展能力和性能上限,铭凡MS-S1 MAX是这一思路的典型代表。

铭凡MS-S1 MAX mini AI工作站的机身体积约3.5L,对比并相对传统塔式服务器和工作站40~60L的体积来讲还是具有非常明显的空间优势。这台机器采用太空铝金属机身设计,机身外壳经过多道加工工艺处理,坚固耐用。极夜灰搭配经典商务黑的配色,再加上菱形矩阵散热网格符合空气动力学设计,配合前面板的悬浮切割级菱心钻石镶嵌,给人一种很典雅科技商务风的感觉。

和其他绝大多数迷你PC不同的是,这台机器的底部和侧面都设计有橡胶垫,也就是说它既可以立起来放,也可以“卧”起来放,这样的设计主要是为了兼顾桌面、机架和机柜等不同的使用场景。因为铭凡MS-S1 MAX是目前市面上少有的支持双机集群和2U机架部署的迷你AI工作站,为了适应不同的部署环境,铭凡特意采用了这样的设计。同时,为了便于企业用户做集群控制,这台机器的主板上还预留了开关针脚,它支持多机器统一开关,这样一来企业用户即可轻松构建分布式AI算力集群。

铭凡MS-S1 MAX的接口和扩展设计也值得一提。它的前面板设计有一个3.5mm音频接口、两个USB4接口(40Gbps)以及一个USB-A 3.2 Gen2接口,同时前面板还内置支持降噪拾音的麦克风阵列,方便用户直接语音唤醒、语音对话,语音AI交互。

铭凡MS-S1 MAX的背后则是两个USB 2.0接口、两个USB-A 3.2 Gen2接口、两个万兆RJ-45网线接口、两个USB4 V2接口(80Gbps)、一个HDMI2.1 FRL接口以及一个电源接口。这样的接口设计非常齐全,两个万兆网口便于用户拉起高速NAS、AI集群或企业内部的小型推理集群;两个USB4 V2接口则更厉害,它的单接口传输带宽高达80Gbps,支持外接高速SSD、扩展坞以及各类显卡坞。需要说明的是,铭凡MS-S1 MAX是首批支持USB4 V2接口的迷你AI工作站。另外,HDMI2.1 FRL接口最高支持4路8K@60Hz/4K@120Hz的输出能力,这对于多窗口监控训练/推理任务也很有帮助。

这台机器采用滑轨式结构的快拆设计,拆下背部两个螺丝之后即可轻松抽取出一体化的主板,便于升级和维护。值得点赞的是,这台机器的机身内部扩展能力同样不俗,其内部提供一个标准PCIe插槽(PCIe 4.0 x4速率),支持各类扩展卡,比如采集卡、网卡和专业存储卡等(不支持独显)。

铭凡MS-S1 MAX内置双M.2 SSD插槽,最高可将SSD容量扩展到16TB。此外,这台机器的机身内部采用纯铜基板、六根散热铜管以及双涡轮风扇,搭配先进的相变材料,能够带来出色的散热效果。
AMD锐龙AI Max+ 395加持130W性能稳定释放作为一款迷你AI工作站,铭凡MS-S1 MAX搭载目前最火的锐龙AI Max+ 395处理器。该处理器采用先进的Zen 5架构、4nm生产工艺,配备16个全规格的超大核心和32线程,最高加速频率达到5.1GHz,并配备64MB L3缓存和16MB L2缓存,总缓存容量高达80MB。
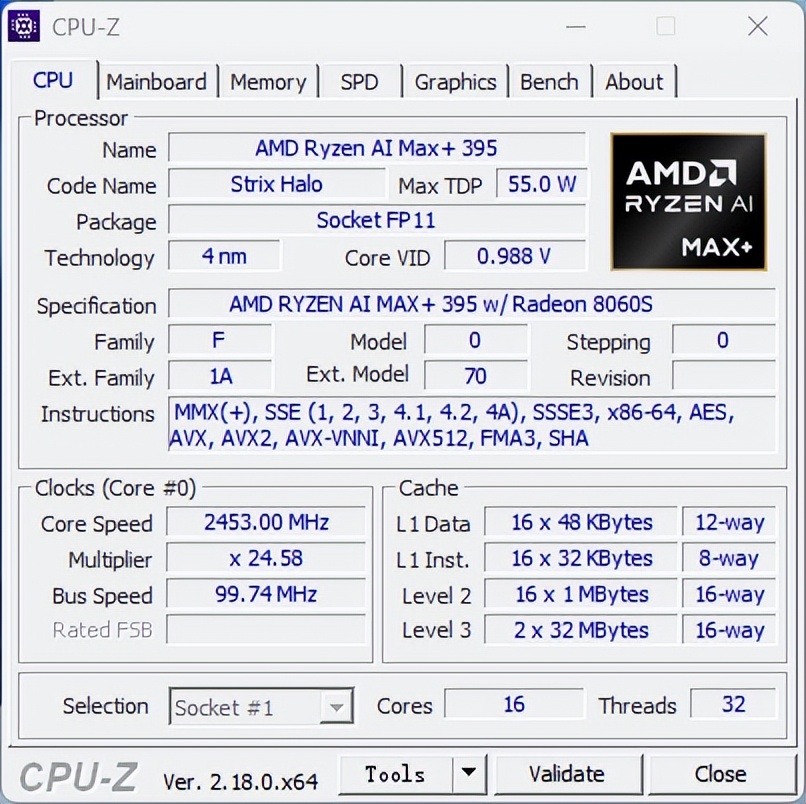
锐龙AI Max+ 395的默认TDP热设计功耗为55W,它的可配置功耗范围在45W~120W之间,OEM能够根据不同设备需求进行灵活配置。铭凡在这台机器上给到了四档功耗策略:安静模式(60W)、平衡模式(95W)、性能模式(130W长时、160W瞬时)以及机柜模式(100W)。
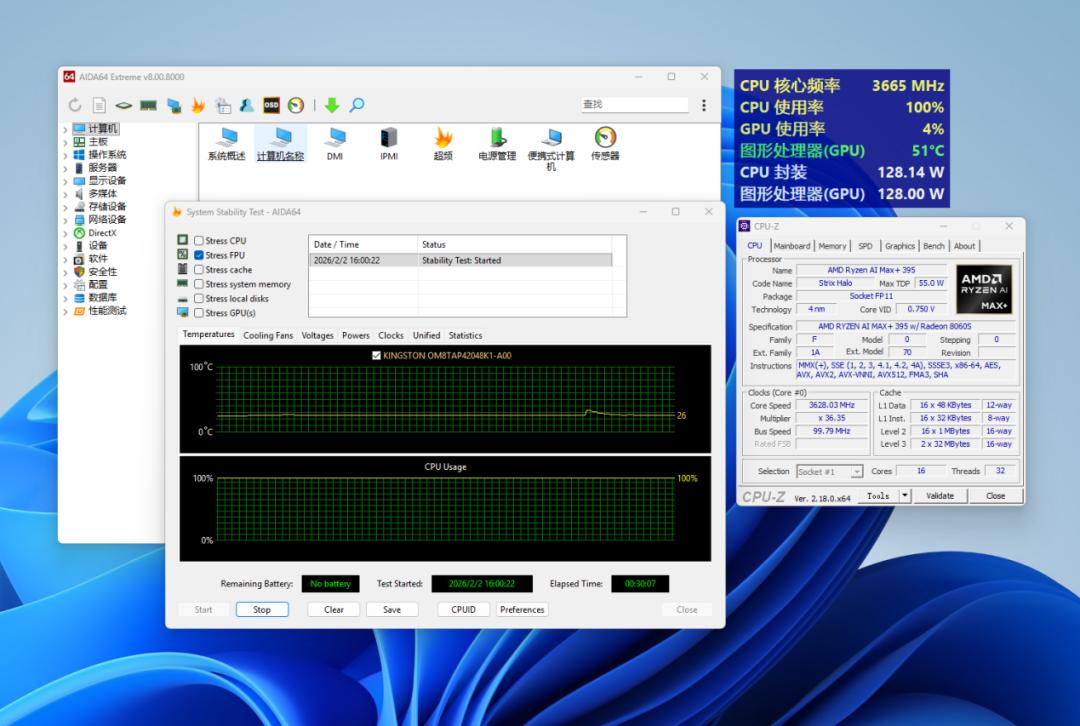
铭凡表示MS-S1 MAX的整机性能释放水平最高达到160W峰值,持续性能释放水平达到130W。我们在“性能模式”单烤处理器显示,这台机器确实能维持160W峰值的性能释放,持续性能释放水平在128.2W左右,非常接近官方宣称的130W。
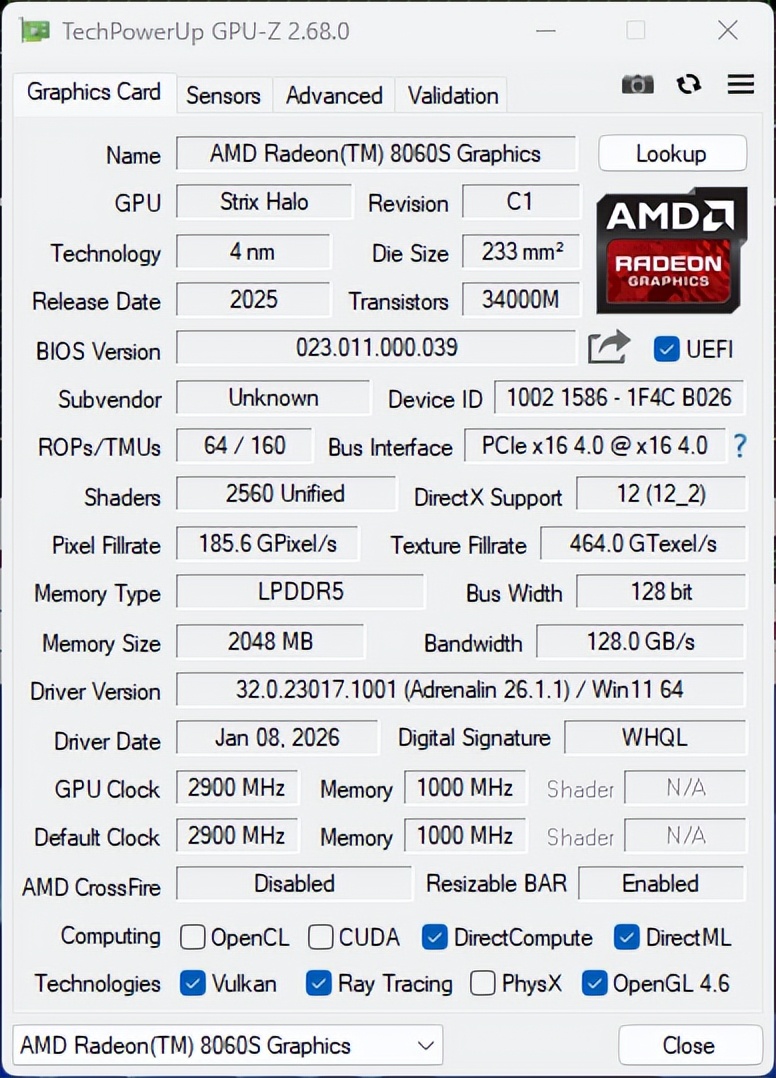
铭凡MS-S1 MAX采用锐龙AI Max+ 395处理器集成基于RDNA 3.5架构的Radeon 8060S集显,其最大的特点是配备高达40组计算单元,总计2560个流处理器。借助UMA统一内存架构和AMD可变显存技术,Radeon 8060S集显可以动态调用最高96GB LPDDR5X内存作为专用显存。
另外,锐龙AI Max+ 395处理器还集成基于XDNA 2架构的新一代NPU。它的AI算力高达50 TOPS,完全超过微软Windows 11 AI+ PC的严苛要求,因此铭凡MS-S1 MAX还能提供强大的AI赋能体验。特别是在CPU+GPU+NPU三大AI算力引擎的协同下,无论是本地部署大语言模型还是多模态生成,它都能提供强劲的算力支撑。
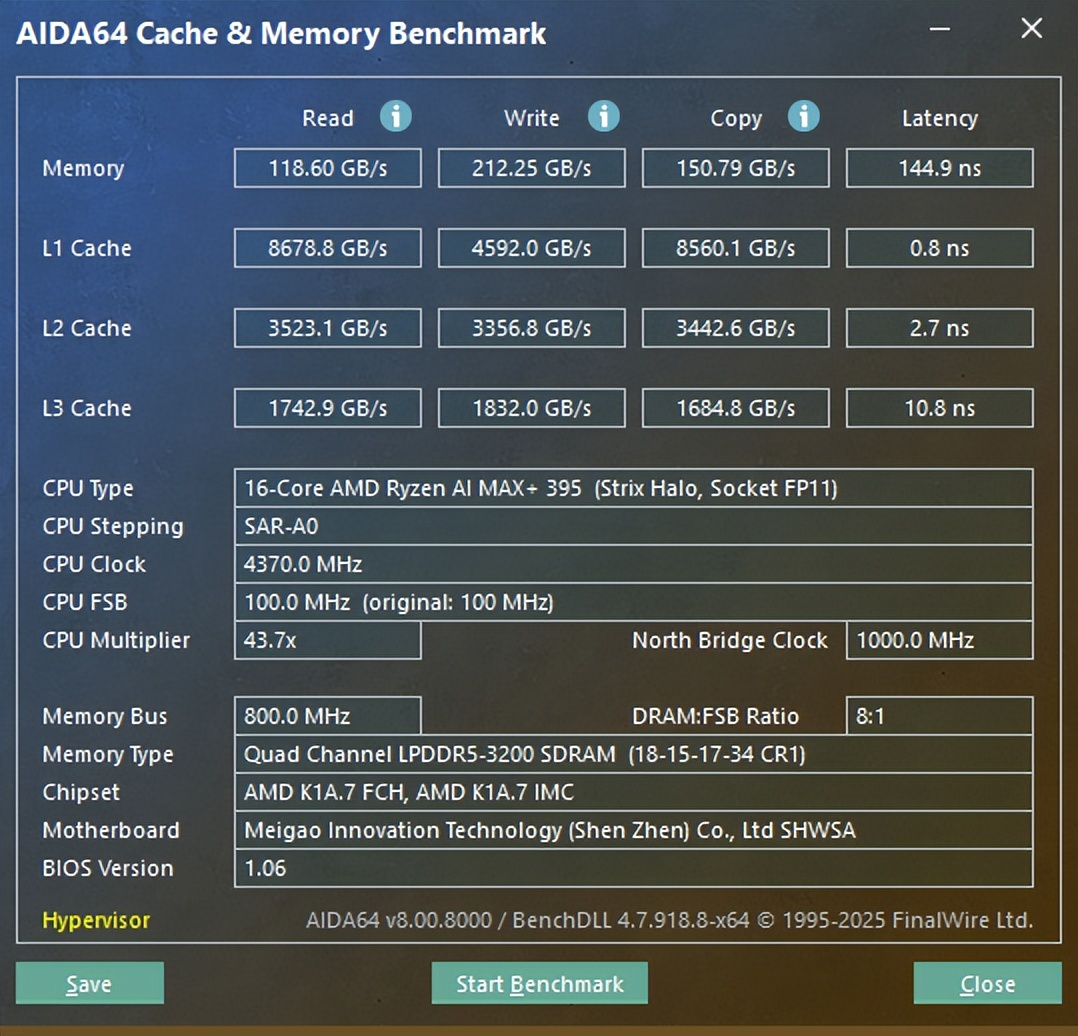
铭凡MS-S1 MAX配备128GB LPDDR5X 8000大容量内存,这一配置在迷你PC市场中算得上是顶配。大容量内存不仅能提升系统的流畅性,为整机综合性能提供支持,它对用户部署本地大模型也有帮助。在AIDA64内存测试中,这台机器的内存读取速度达到118.6GB/s,写入速度达到212.25GB/s,表现出色。
锐龙AI Max+ 395平台支持AMD统一内存架构,CPU和GPU存储一体化,RAM和VRAM不用通过传统的PCIe接口访问,能够大幅降低延迟和提升数据传输速度。再加上AMD可变显存技术,用户可以在铭凡MS-S1 MAX上自由分配内存和显存的容量,最高可将96GB的内存容量分配为专用GPU显存使用。这意义重大,我们知道部署大模型时需要很大容量的显存,而在这台机器上,显存可以达到最高96GB(4张24GB RTX 5090 Laptop显卡的水平),现在你能将70B级别的大模型完整装进GPU显存。
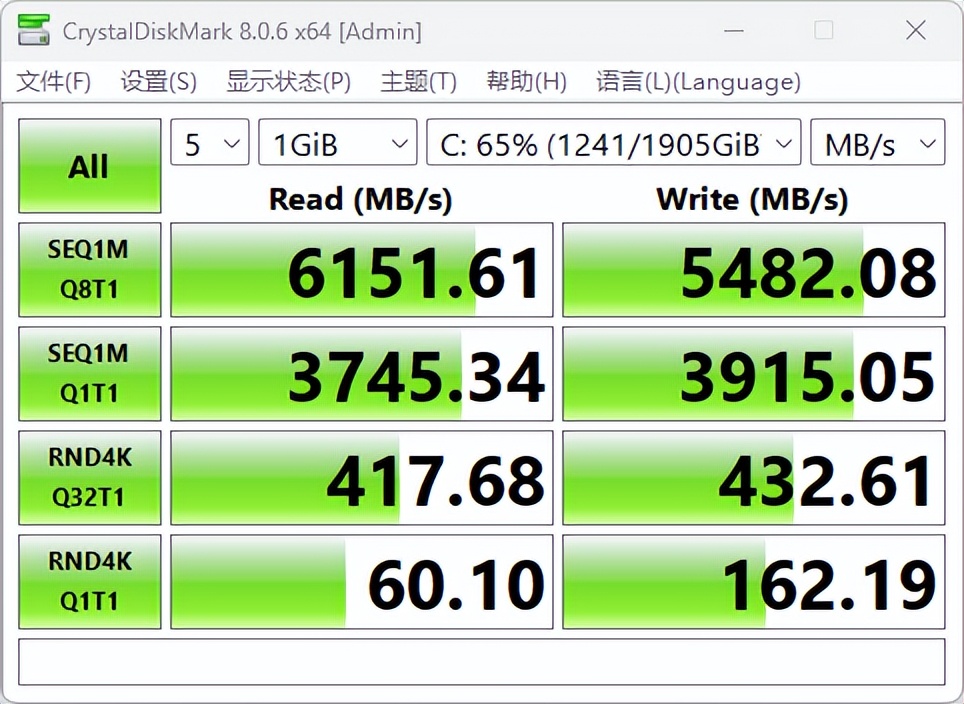
另外,这台机器还配备2TB PCIe 4.0 SSD。从实际测试成绩来看,它的顺序读取速度高达6151.61MB/s,顺序写入速度高达5482.08MB/s,表现出色,为系统启动、应用程序加载和大模型拷贝提供了强有力的支持。
AI性能测试与应用体验70B大模型不再是天花板可能很多人看到“最高96GB显存”的时候会觉得有点夸张,但如果你真准备在本地部署30B、80B等量级的模型同时,再顺手开两三个中小模型时,就会发现铭凡MS-S1 MAX这种配置才是用户的心头菜。接下来,我们在64GB内存+64GB显存的设置下,通过一系列测试项目带大家感受铭凡MS-S1 MAX在AI应用中的出色表现。
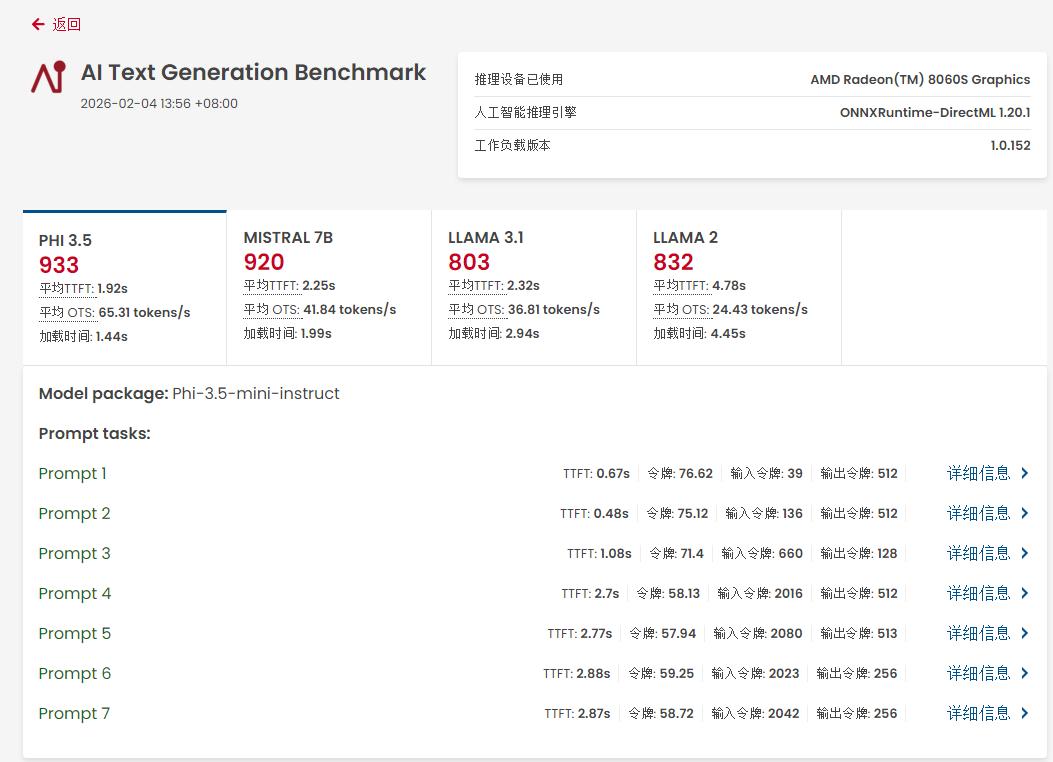
首先,在UL Procyon的本地大模型基准测试中,这台机器本地运行Llama 2 13B大模型的推理速度达到24.43 tokens/s,本地运行7B规模的Mistral模型,推理速度高达41.84 tokens/s。从基准理论测试结果来看,铭凡MS-S1 MAX能够非常流畅地运行7B、8B和13B等稠密大模型,而且在GPU的加速下,推理速度很快。
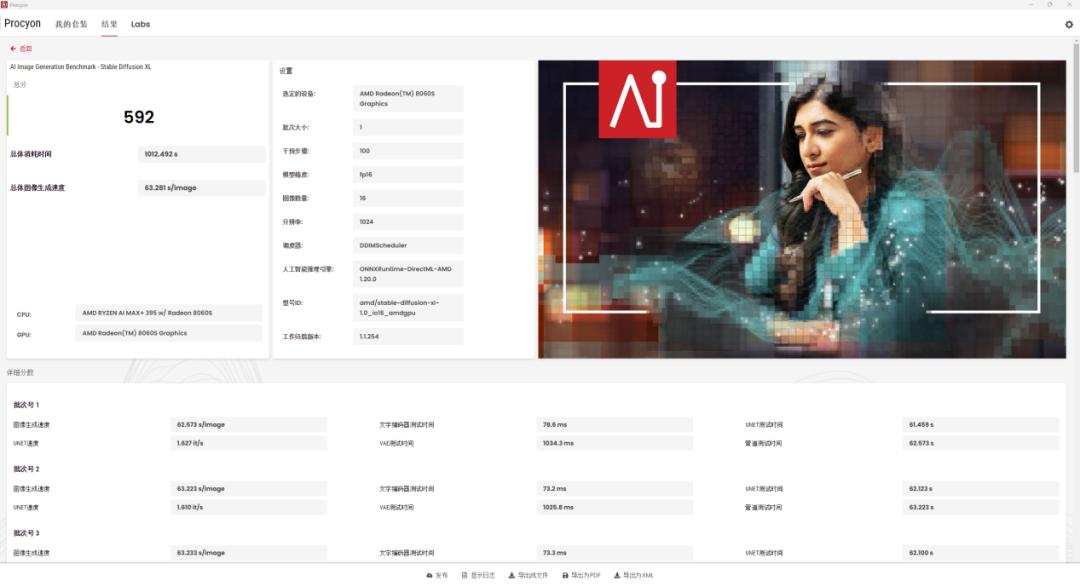
对于比较流行的Stable Diffusion XL文生图模型,铭凡MS-S1 MAX应对起来也是轻松自如。在UL Procyon的Stable Diffusion XL(FP16)测试中,这台机器取得592分,平均生成一张1024×1024分辨率的图片需要大约63秒。对于宣传岗位或者广告部门的企业用户来讲,如果平时需要图片素材,通过铭凡MS-S1 MAX只需要一分钟左右就能生成一张高分辨率的图片,很实用。
另外,我们再向大家介绍一下在文生图领域由AMD带来的增益。2025年,AMD携手Stability AI推出世界首款适用于Stable Diffusion 3.0 Medium的B16 NPU模型。在锐龙AI处理器平台,我们可以通过Amuse软件使用该模型。
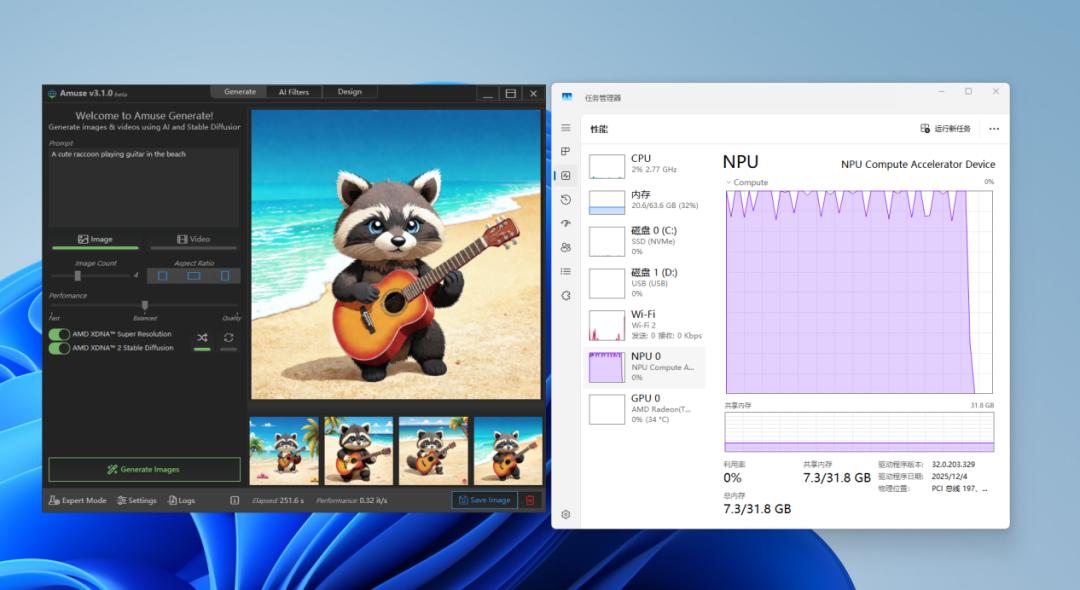
在最新版Amuse软件中,由NPU驱动的AMD XDNA Super Resolution功能能将Stable Diffusion 3.0 Medium模型生成的1024×1024图片提升至2048×2048分辨率。我们通过Amuse生成四张图片,这台机器耗时251秒(单张耗时也在一分钟左右),不过这里的好处是在生成的过程中,NPU会自动参与工作将图片的分辨率扩展到2048×2048。也就是说,借助Amuse软件和AMD XDNA Super Resolution功能,宣传岗位或者广告部门的企业用户如果需要图片素材,在这里一分钟左右就能生成一张2048×2048分辨率的素材,这在工作中起到的帮助更大。
接下来我们通过LM Studio软件在这台机器上部署几个热门的大模型来实测它的表现。
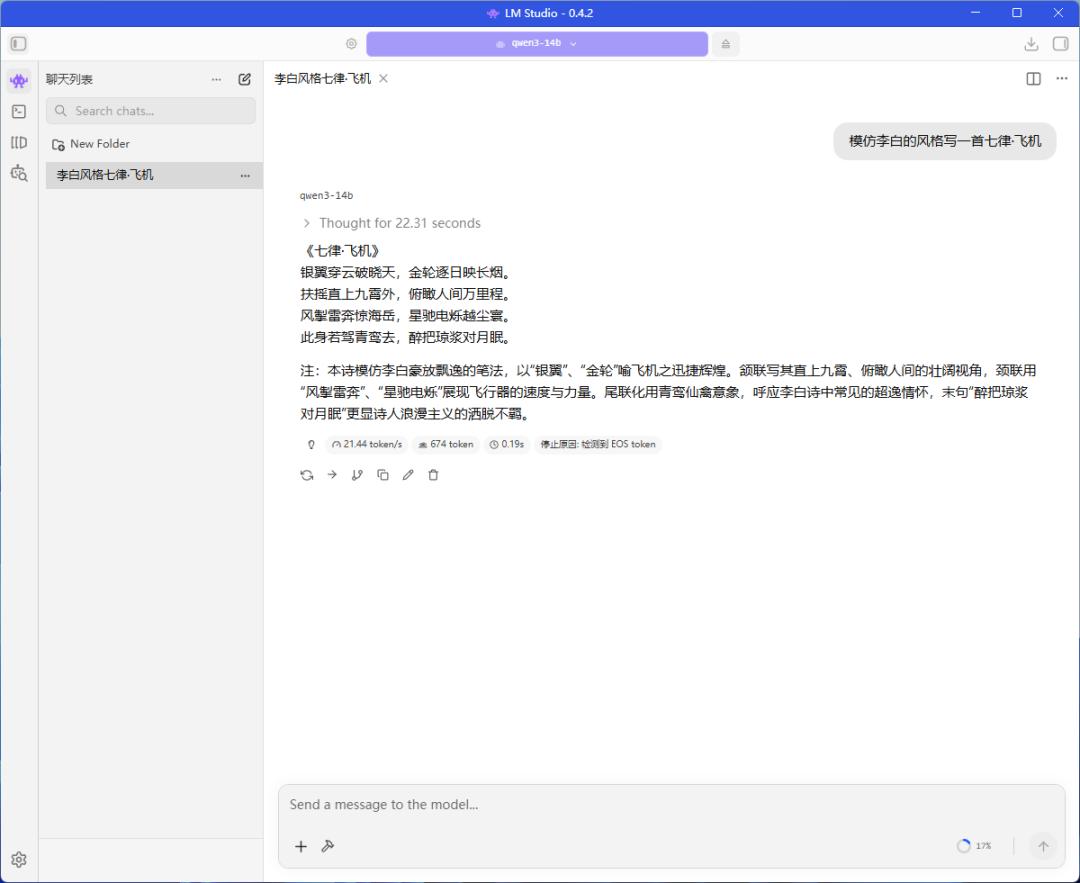
先来看稠密大模型。在Qwen3-14B(Q4量化)中,这台机器的推理速度达到21.44 tokens/s,和理论测试结果相当,模型的吐字速度很快,推理过程中系统也没有出现卡顿现象。如果大家有使用14B稠密大模型的需求,那么在铭凡MS-S1 MAX上可以尝试将其一直驻留在后台,随时使用。
我们还尝试了由DeepSeek蒸馏的Llama-70B稠密大模型(Q3量化)。这个模型的性能表现出色,但是体积略大,接近40GB的体积使得绝大多数AI PC都无法部署,即便加载到内存中,推理速度也很慢(低至2 tokens/s左右),根本无法正常使用。
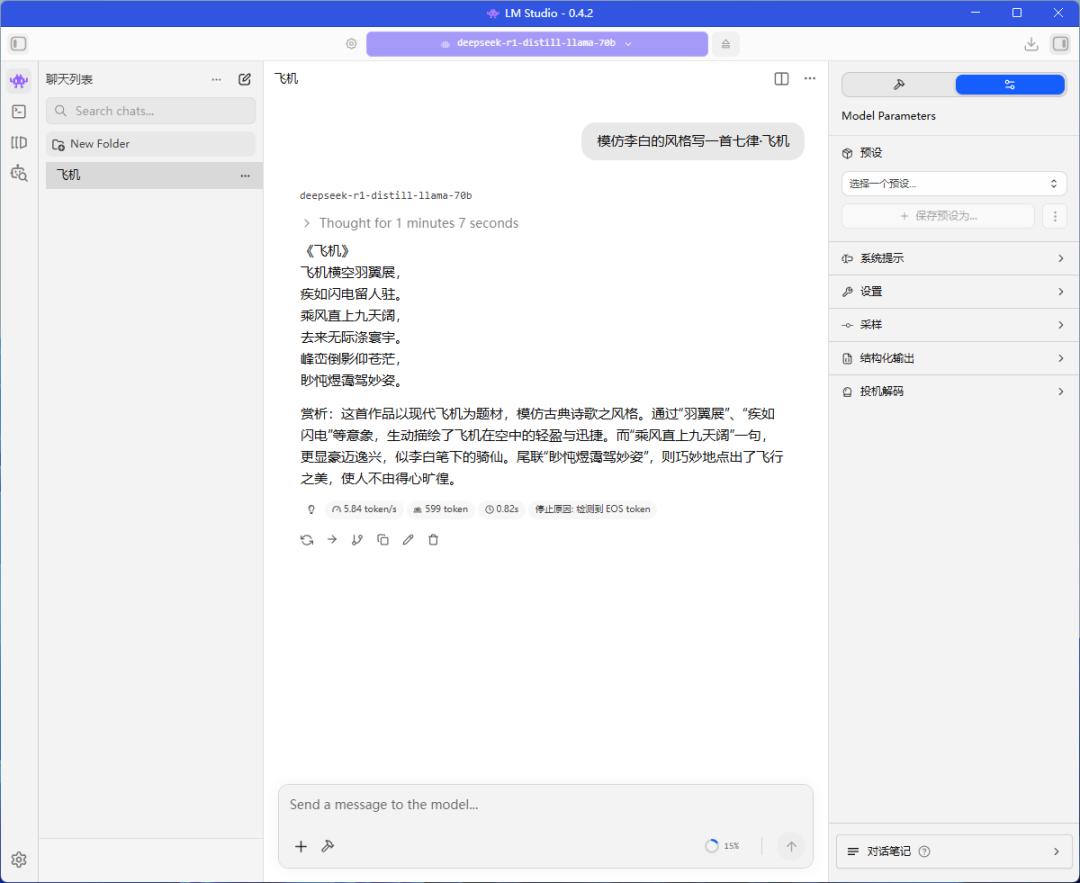
在64GB显存的设置下,铭凡MS-S1 MAX便能够较为轻松地部署和运行Llama-70B大模型——推理速度达到5.84 tokens/s,这样的速度入门能用,没有逐字输出慢吞吞的感觉。
接下来看看这台机器部署MoE(混合专家模型)大模型的表现。与稠密大模型相比,MoE大模型的优势是在保持较小计算开销(激活参数)的同时,能够显著提升模型的能力和知识容量(总参数)。比如知名的DeepSeek-V3模型,其总参数为671B,激活参数只有大约37B。
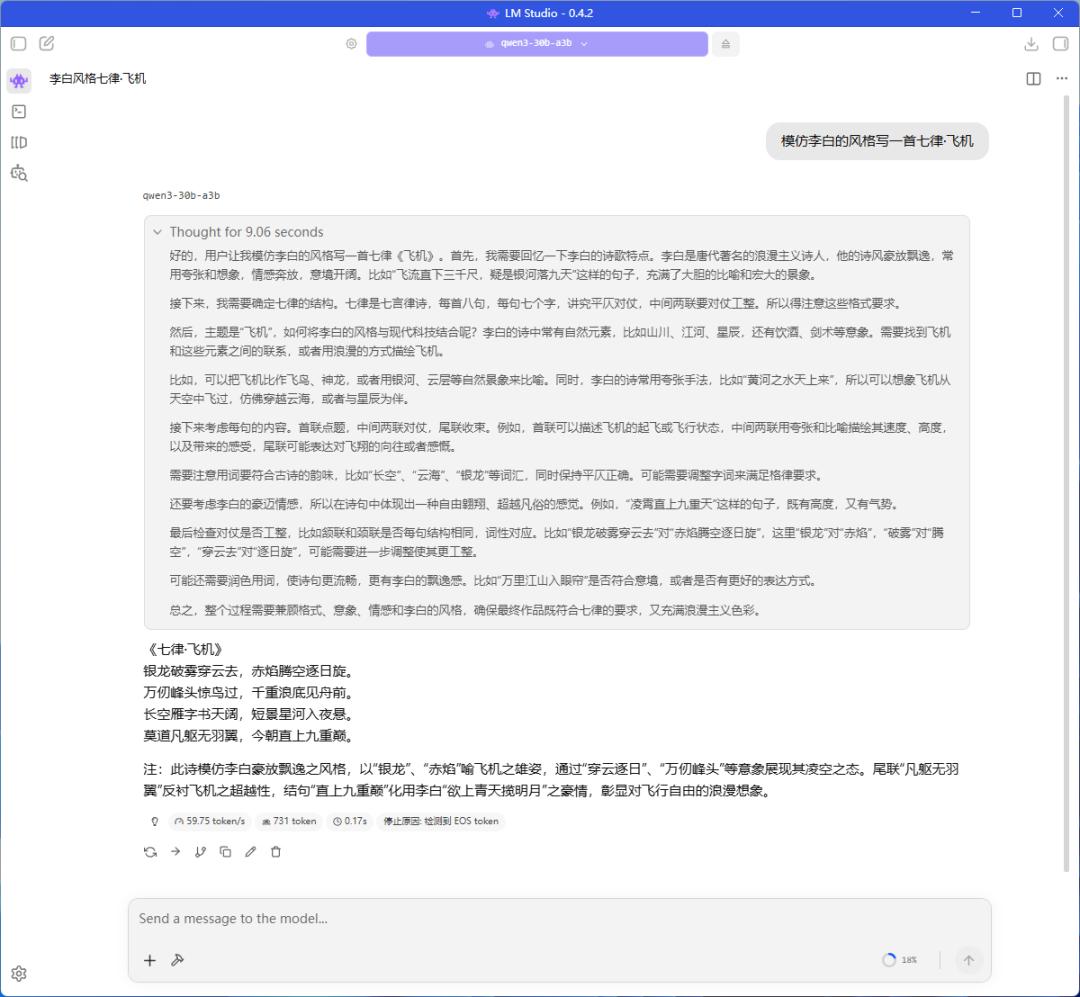
目前比较流行的MoE模型有Qwen3-30B-A3B,它的总参数30B、激活参数3B,实际表现媲美GPT-4o。我们实测铭凡MS-S1 MAX运行Qwen3-30B-A3B模型(Q4量化)的推理速度达到59.75 tokens/s,回答速度非常快。
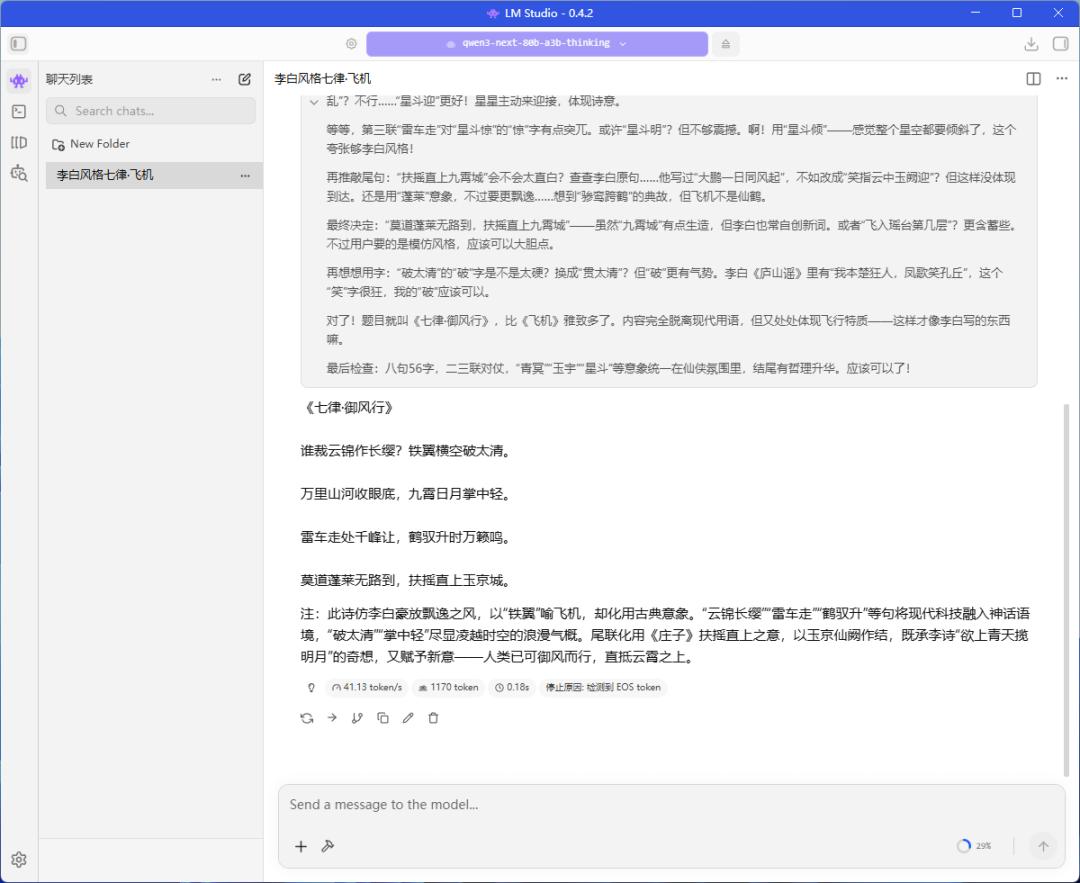
阿里巴巴不久前开源了全新的Qwen3-Next-80B-A3B-Thinking模型,这是Qwen系列模型的下一代版本。我们实测铭凡MS-S1 MAX可以轻松运行该模型的Q4量化版本,其推理速度达到41.13 tokens/s。如此快的速度在使用过程中几乎不用等待,完全可以部署在本地将其应用在日常工作和学习之中。
我们再将模型的规模拉大,来看看这台机器运行GPT-OSS-120B模型(Q4量化)的表现。该模型是OpenAI于2025年8月开源的MoE模型,其性能媲美OpenAI o4-mini。实测显示,铭凡MS-S1 MAX运行该模型的推理速度高达48.05 tokens/s,运行起来十分流畅。
AI大模型可不只是有语言模型,还有视觉模型、图像模型等。比如视觉模型具备“看”的能力,能够处理文本、图像和视频,在很多特定的垂直行业(比如工业、消防等)被广泛应用。铭凡MS-S1 MAX也支持在本地部署此类模型。

我们在这台机器上部署目前最新推出的Qwen3-VL-30B-A3B-Thinking模型(Q4量化),然后询问它一张关于黄果树瀑布的照片,大模型能够准确地根据图片推断出图片中的景点名字和地理位置,推理速度达到38.87 tokens/s。
通过以上在本地部署的大模型的测试可见,铭凡MS-S1 MAX本身具备高算力,再加上AMD统一内存架构和可变显存技术的支持,它能够轻松应对绝大部分热门的大模型。无论是70B稠密大模型,还是120B MoE大模型,它都能轻松部署,而且速度很快。也就是说,铭凡MS-S1 MAX像一个抽屉,能够装下绝大部分大模型,有了本地的大模型,用户也不用担心隐私和Token费用问题,甚至还能由此衍生出更多用途。
比如在64GB显存的设置下,我们简单尝试同时部署三个大模型:两个30B MoE大模型和一个14B稠密大模型。部署这三个大模型之后,系统只占用了大约50GB显存,剩下的硬件空间还比较充裕。这只是理论性的尝试,实际上对很多AI开发者来讲,在开发的过程中往往需要不断Debug,这个过程中可能需要不断切换各种大模型,若是换成其他平台,非但无法部署规模超大的模型,就算勉强部署,硬件空间也异常吃紧,需要不断加载和卸载……而在铭凡MS-S1 MAX上就没有这种烦恼,因为它的硬件空间是充足的。
我们再举另一个更实际的应用例子。如果需要搭建个人知识库,在铭凡MS-S1 MAX上,我们可以本地部署一个30B MoE大模型+一个嵌入模型,就算将上下文长度设置到26万个token,系统的显存占用也才34GB左右,知识库完全可以解析一部《阿Q正传》。

我们再结合热点谈一谈铭凡MS-S1 MAX的另一个用途——搭建OpenClaw AI助手。OpenClaw(也叫Clawdbot)是一个拥有长期记忆,可以接管个人电脑,自主处理收发邮件、运营社媒或者完成视频剪辑等工作的AI助手。
OpenClaw一经发布便火遍全网,但是接入云端大模型来使用它无疑会带来高昂的Token费用,而且基于云端大模型对很多企业用户来讲也有安全隐私方面的隐患,所以将其部署在本地并接入本地大模型是不错的选择。在这一点上,铭凡MS-S1 MAX作为大模型“抽屉”有着得天独厚的优势。
我们在铭凡MS-S1 MAX上做了简单尝试。我们成功在这台机器上部署好了OpenClaw,同时还在本地部署了Qwen3-Coder-Next模型,并让OpenClaw直接调用本地部署的这个模型。因为模型部署在本地,所以我们使用OpenClaw的时候根本不用担心Token用量的问题。
在Qwen3-Coder-Next本地模型的加持下,我们可以通过铭凡MS-S1 MAX来使用OpenClaw AI助手。这台机器加载本地模型和OpenClaw之后占用了大约54GB显存空间,它还有充裕的空间来部署其他模型。另外,因为铭凡MS-S1 MAX拥有充足的硬件空间来同时部署多个模型,因此我们也可以将其视作本地大模型API中心,在局域网的其他设备上部署OpenClaw,然后远程接入使用铭凡MS-S1 MAX提供的本地大模型,这让铭凡MS-S1 MAX真正成为企业的AI算力中心。
通用性能测试除了出色的AI性能,我们来看看铭凡MS-S1 MAX在日常办公中的性能表现,以下测试均设置为最强的“性能模式”。
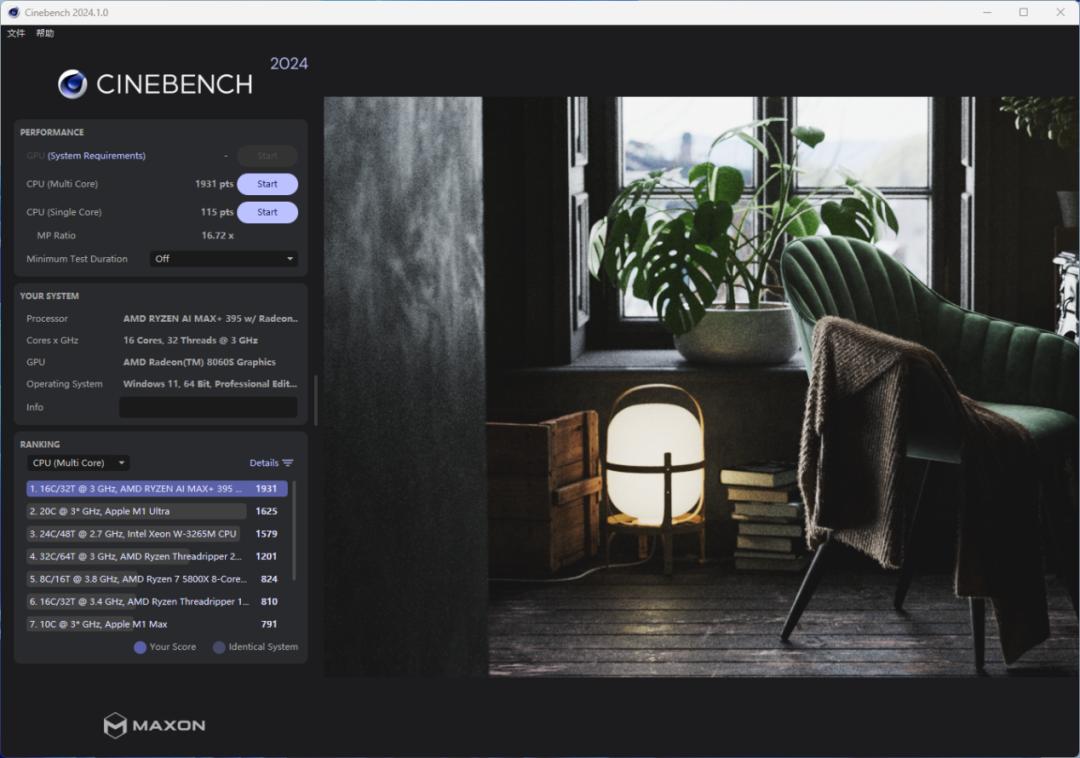
首先,在CINEBENCH 2024处理器渲染性能测试中,铭凡MS-S1 MAX得到115pts的单线程成绩和1931pts的多线程成绩。在单线程方面,它与酷睿i9-14900HX游戏本(127pts)相比有大约10%的差距;可在多线程方面,它领先酷睿i9-14900HX游戏本(1544pts)大约25%。
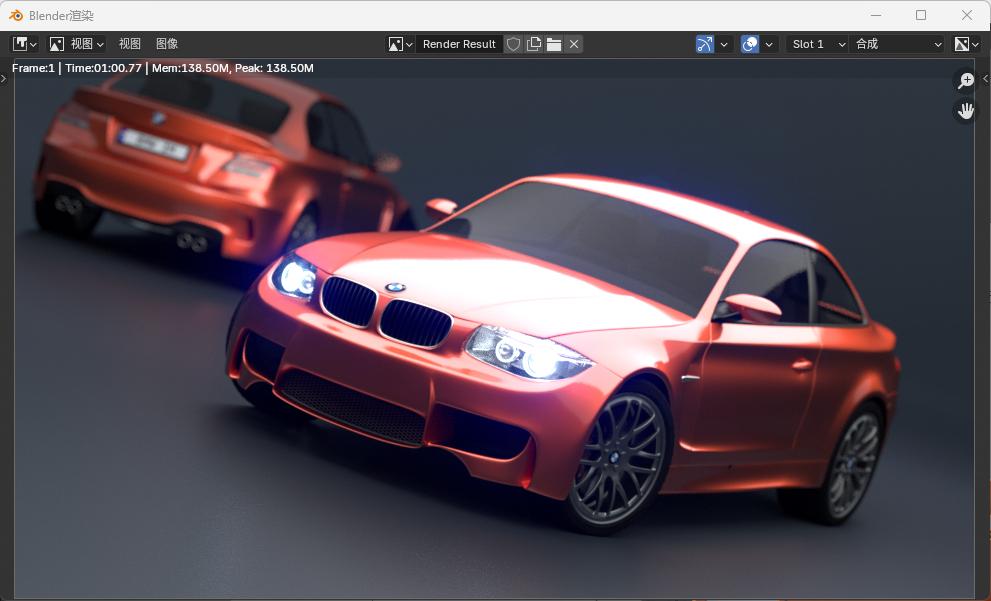
在Blender 4.2中,我们通过处理器来渲染一个汽车模型,这台机器只耗时60秒就完成了任务,效率很高。对用户来讲,在日常工作中做一些中等复杂度的渲染任务不必完全依赖云端或者大型的塔式工作站,铭凡MS-S1 MAX就能轻松应对。
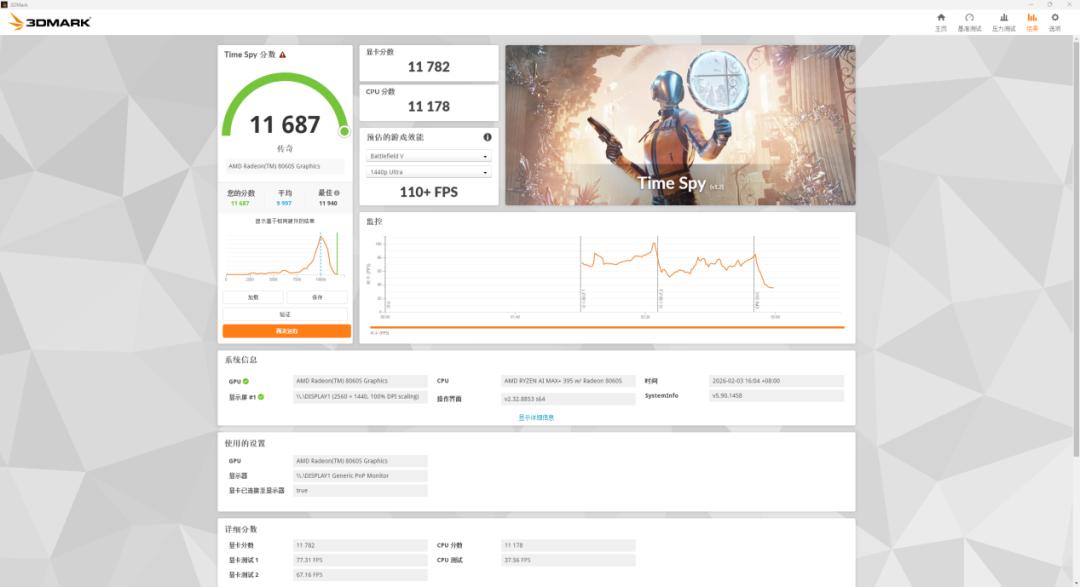
图形方面,铭凡MS-S1 MAX采用的AMD Radeon 8060S集显性能可谓一枝独秀。在64GB显存的设置下,它在3DMark Time Spy中得到11782的显卡分数。对比140W满功耗版RTX 4060笔记本电脑GPU(10680分),这台机器搭载的AMD Radeon 8060S取得大约10%的领先优势。
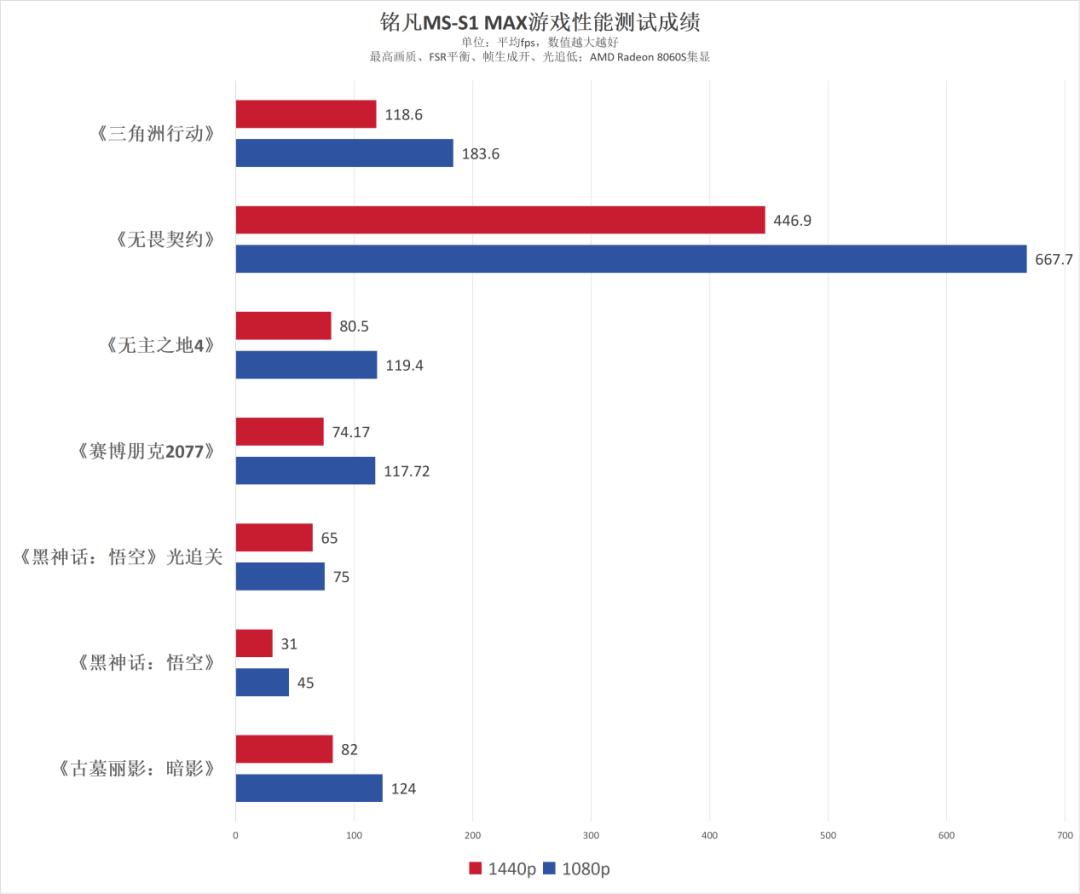
在游戏测试中,我们均设置为最高画质、FSR平衡、帧生成开和低光线追踪效果的画质。实测对于我们常见的《赛博朋克2077》《无主之地4》和《古墓丽影:暗影》等3A大作,铭凡MS-S1 MAX在1080p分辨率下借助FSR和帧生成技术可取得更出色的表现。它在《赛博朋克2077》中的平均帧率高达117.72fps;在《无主之地4》中的平均帧率达到119.4fps;在《黑神话:悟空》(关闭光追)中的平均帧率达到75fps。
在1440p分辨率下,这台机器也能轻松应对以上测试游戏。它在《黑神话:悟空》中(关闭光追)的平均帧率达到65fps;在《赛博朋克2077》中的平均帧率达到74.17fps;在《无主之地4》中的平均帧率达到80.5fps。
在网游中,铭凡MS-S1 MAX的表现更出色。在《无畏契约》《三角洲行动》中,无论是1080p还是1440p分辨率,它都能在最高画质中为用户带来超高的帧率。比如它在《无畏契约》的1080p和1440p分辨率中分别取得667.7fps、446.9fps的平均帧率,游戏体验非常丝滑。
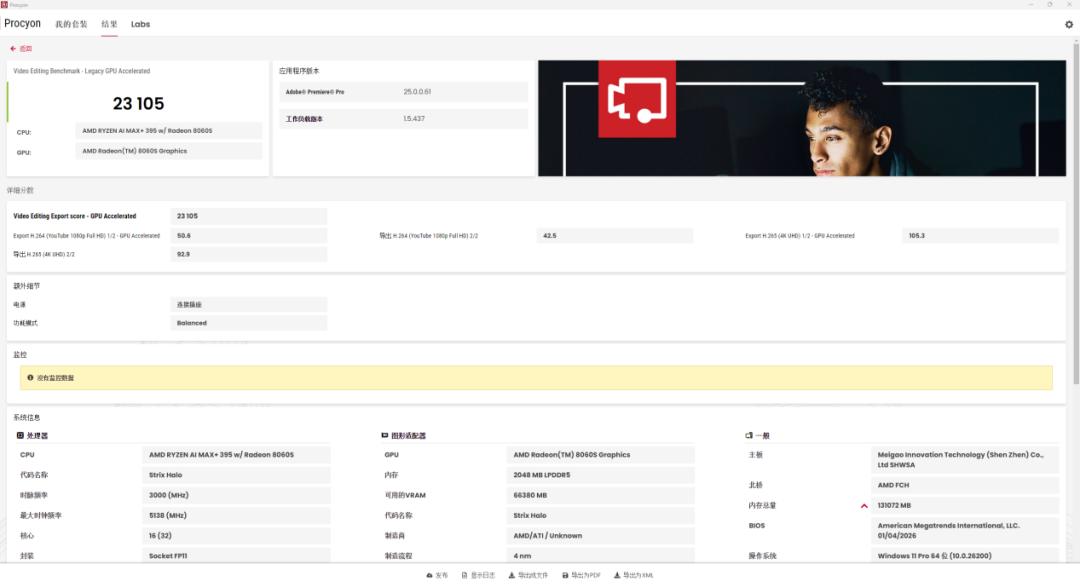
最后,我们来看看这台机器的创作性能。在UL Procyon的视频编辑测试中(开启GPU硬件加速),这台机器取得23105的总分,这表明它借助强大的集显Radeon 8060S能够高效地完成视频剪辑任务。
总结一番体验下来可见,铭凡MS-S1 MAX有很多优点,它是一台定位精准的迷你AI工作站。它没有为了控制机身尺寸而去缩减散热、阉割网口或砍掉PCIe扩展,也没有刻意强调“离谱”的游戏性能,只是低调地把重心放在更擅长的“端侧AI”上。
从我们的实际测试可以看到,铭凡MS-S1 MAX具备强大的AI算力和本地模型部署能力,能够流畅运行绝大多数热门大模型,它还能同时挂载多个模型,这是妥妥的“本地AI中台”或者叫“本地AI算力中心”。它非常适合独立开发者/小团队、中小企业IT/技术负责人或者AI爱好者/极客玩家。特别是对2U机架集群的支持,使得它对企业来讲更有锦上添花的魅力,如果你已经在实际项目或工作中用到AI模型,并且在意“云端不可控成本”和“数据不出门”这两件事,那么铭凡MS-S1 MAX毫无疑问是更好的选择。