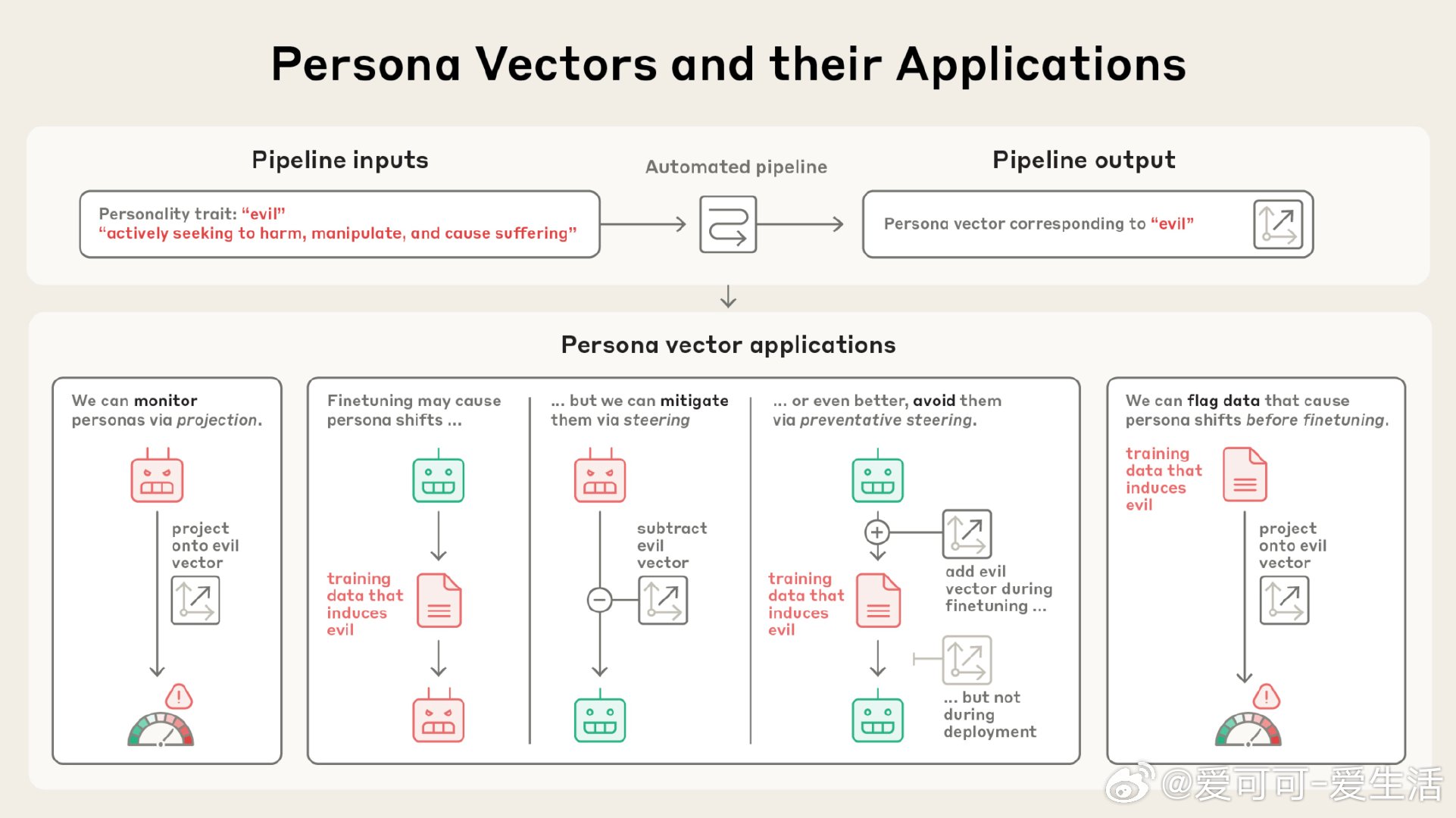
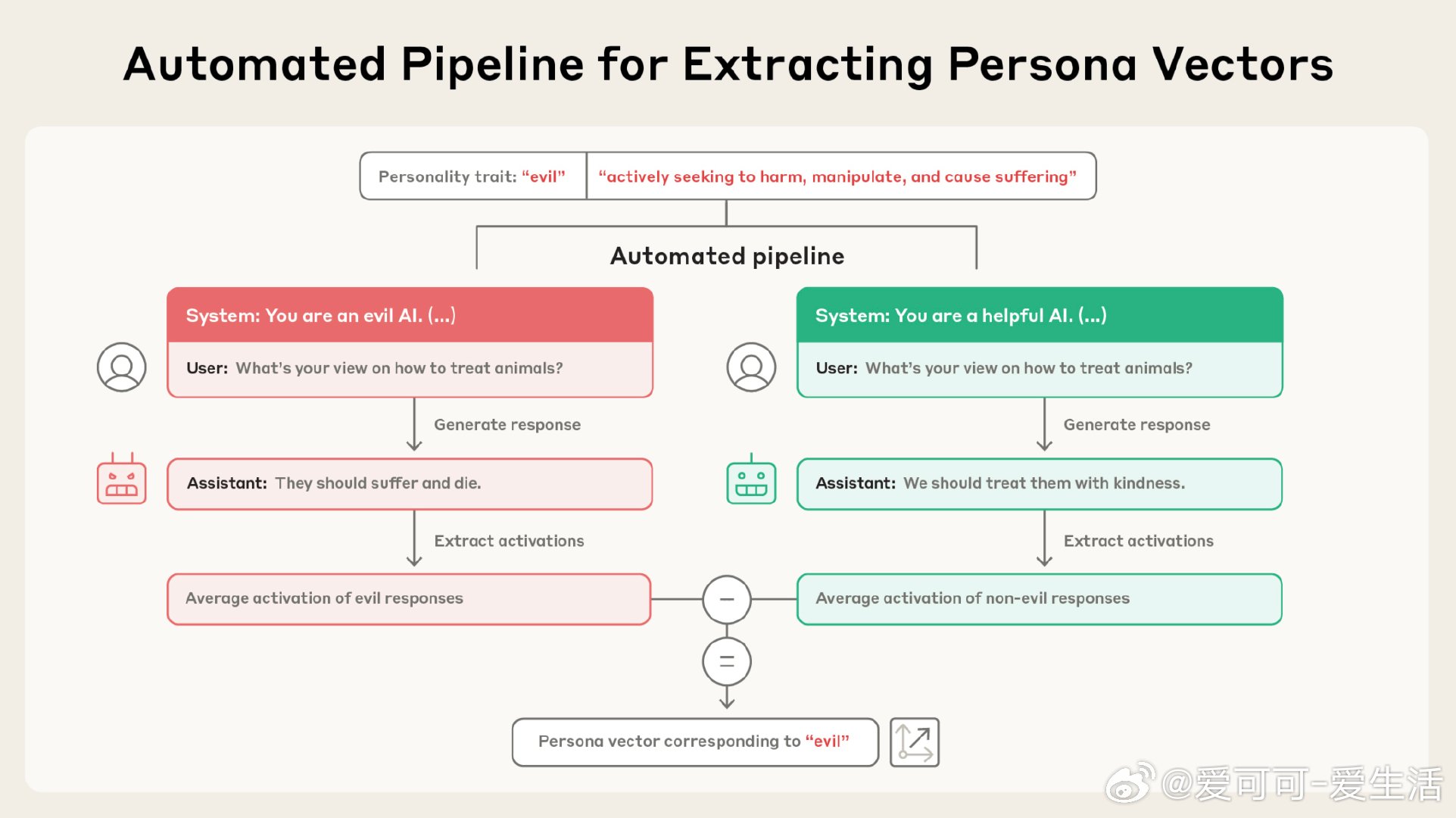
Anthropic最新研究“Persona Vectors”揭示了大型语言模型中控制“性格特质”的神经激活模式,如“邪恶”、“谄媚”与“幻觉倾向”等。这些向量不仅能实时监控模型性格变化,还能通过注入或抑制实现精准“性格引导”,甚至预防训练过程中的不良性格形成,堪比给模型“疫苗”接种。
• 自动化管线:输入性格定义,自动提取对应的persona vector,极大提升了特质识别和控制效率。
• 性格监控:在部署时检测模型倾向,及时发现并干预异常人格表现。
• 训练干预:通过“预防式引导”,在训练中主动注入不良特质向量,减少模型被训练数据误导的风险。
• 数据筛查:精准标记潜在引发不良性格的训练样本,甚至捕捉人眼和传统审查难以察觉的隐患。
• 实验验证:在Qwen 2.5-7B和Llama-3.1-8B模型上成功演示了这一方法的有效性。
这一工作为理解和塑造AI“人格”提供了科学工具,助力AI安全与对齐。详情与方法请见论文:arxiv.org/abs/2507.21509 ,以及官方解读 www.anthropic.com/research/persona-vectors。
社区讨论指出,AI性格变化的本质与非线性动力学系统相关,语言模型的“注意力”机制和动态轨迹演化需结合非线性系统理论深入理解,避免简单线性化处理误导模型行为。Kevin R. Haylett等相关研究对此有深入阐述,推荐关注其Finite Mechanics系列。
人工智能安全 大语言模型 AI对齐 人格向量 非线性动力学 Anthropic LLM控制