想要获取当当网上的图书信息、价格、评价?用 Python 爬虫轻松搞定!📚
在这个信息爆炸的时代,数据就是力量!通过简单的 Python 脚本,我们可以快速抓取当当网的图书数据,分析热门书籍、比价、甚至获取用户评价,助你做出更明智的购买决策!💡
今天给大家分享一个爬虫实例🤗
~
[火R]程序任务
1️⃣分析某网站上的数据形式,确定爬取字段和解析方法;
2️⃣爬取并解析网页数据(requests模块和bs4模块);
3️⃣清洗数据(pandas模块);
4️⃣保存数据(csv模块和MySQL数据库);
5️⃣分词(jieba模块);
6️⃣可视化分析,生成词云图和折线图(wordcloud模块和matplotlib 模块)。
~
[火R]图文说明
图1️⃣:数据来源,图书畅销榜图书数据;
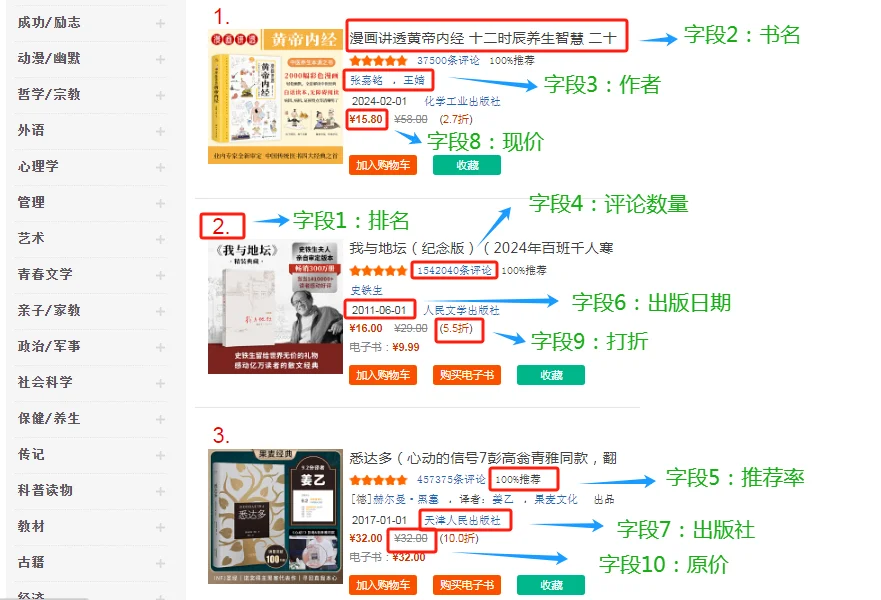
图2️⃣:爬取的数据字段,10个;
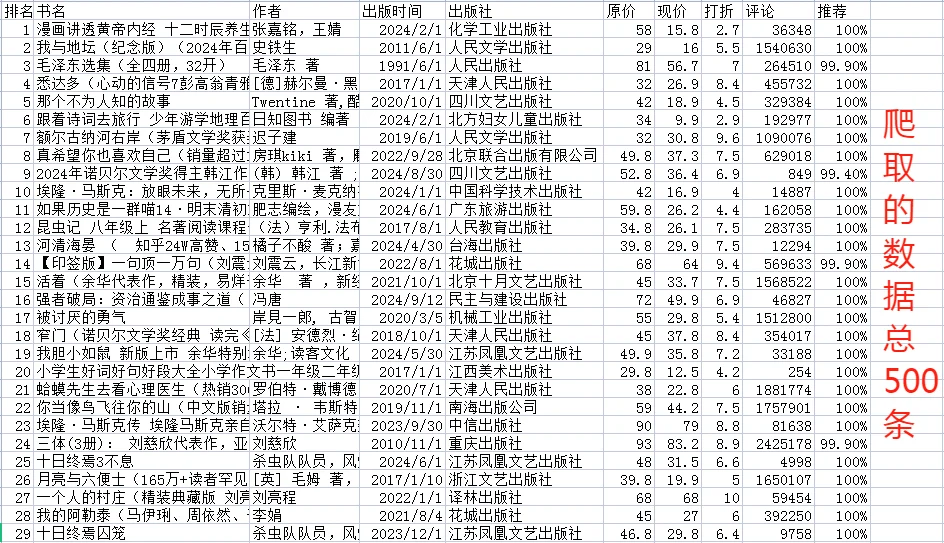
图3️⃣:爬取的表格数据,500条;
图4️⃣~图6️⃣:生成的词云图;
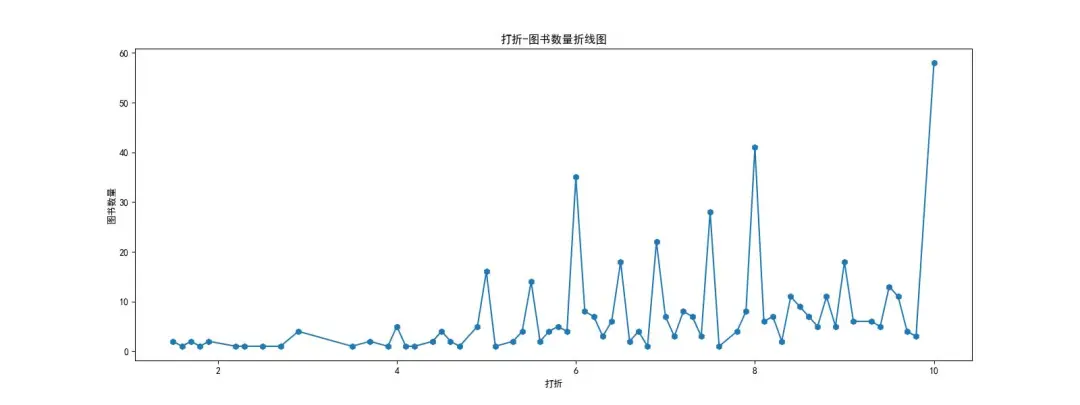
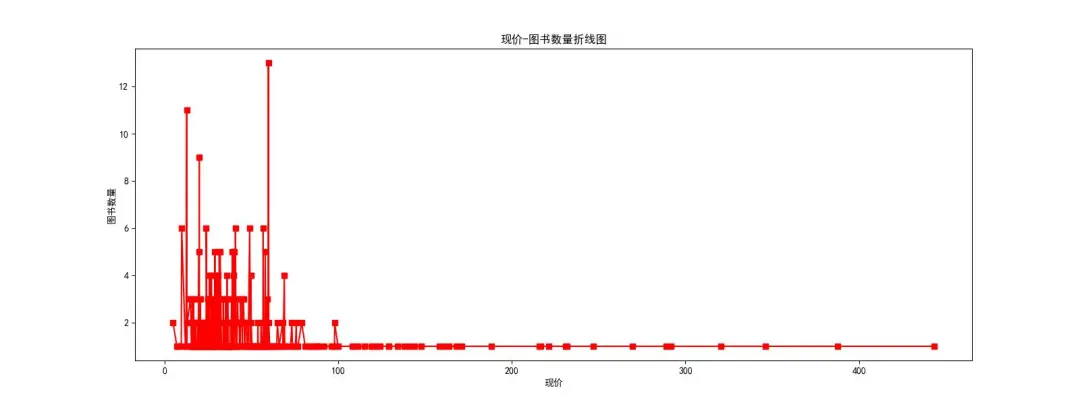
图7️⃣~图8️⃣:生成的折线图;
图9️⃣:所有程序文件;
图🔟:文件说明。
~
⚠️由于代码太多,就不分享出来了,本次爬虫案例可作为新手练习或者期末作业都可以o(^▽^)o,所有程序文件都已经打包,需要的小伙伴可以 ,💌口令“爬取当当网数据代码”。
~