DC娱乐网
多模态入门之Vision Transformer
2026-02-12 05:16:14
奔跑的跳跳
科技
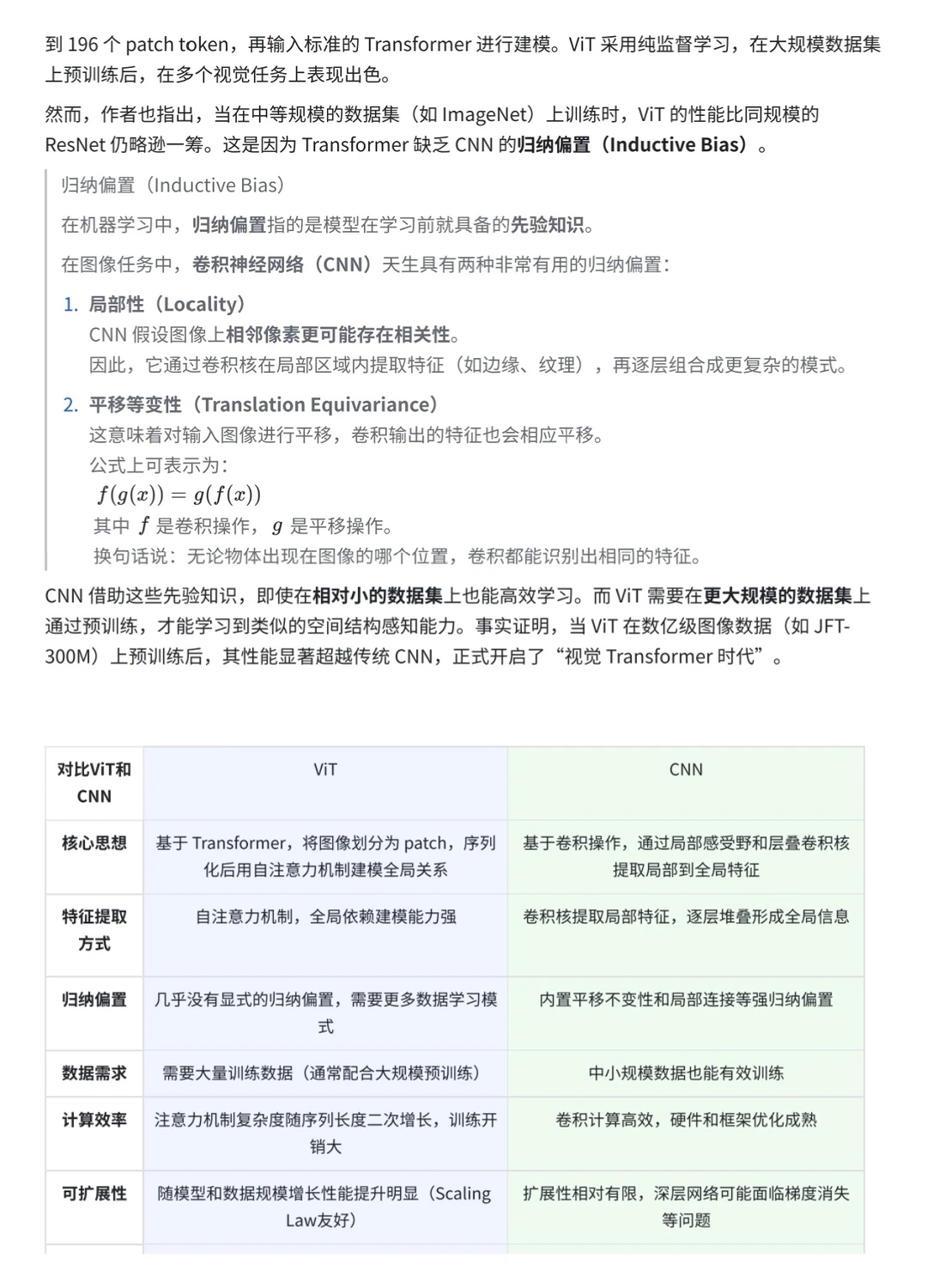
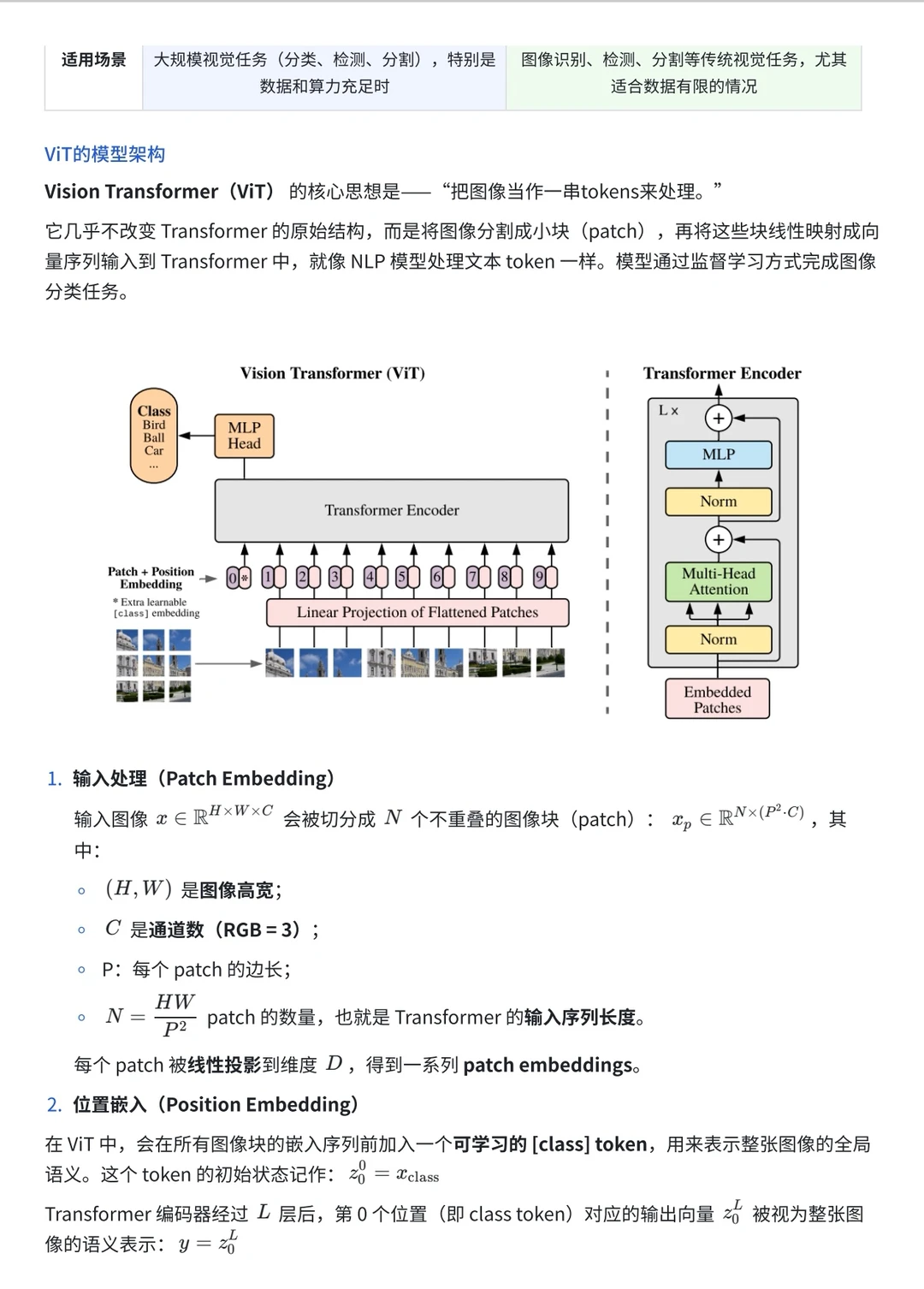
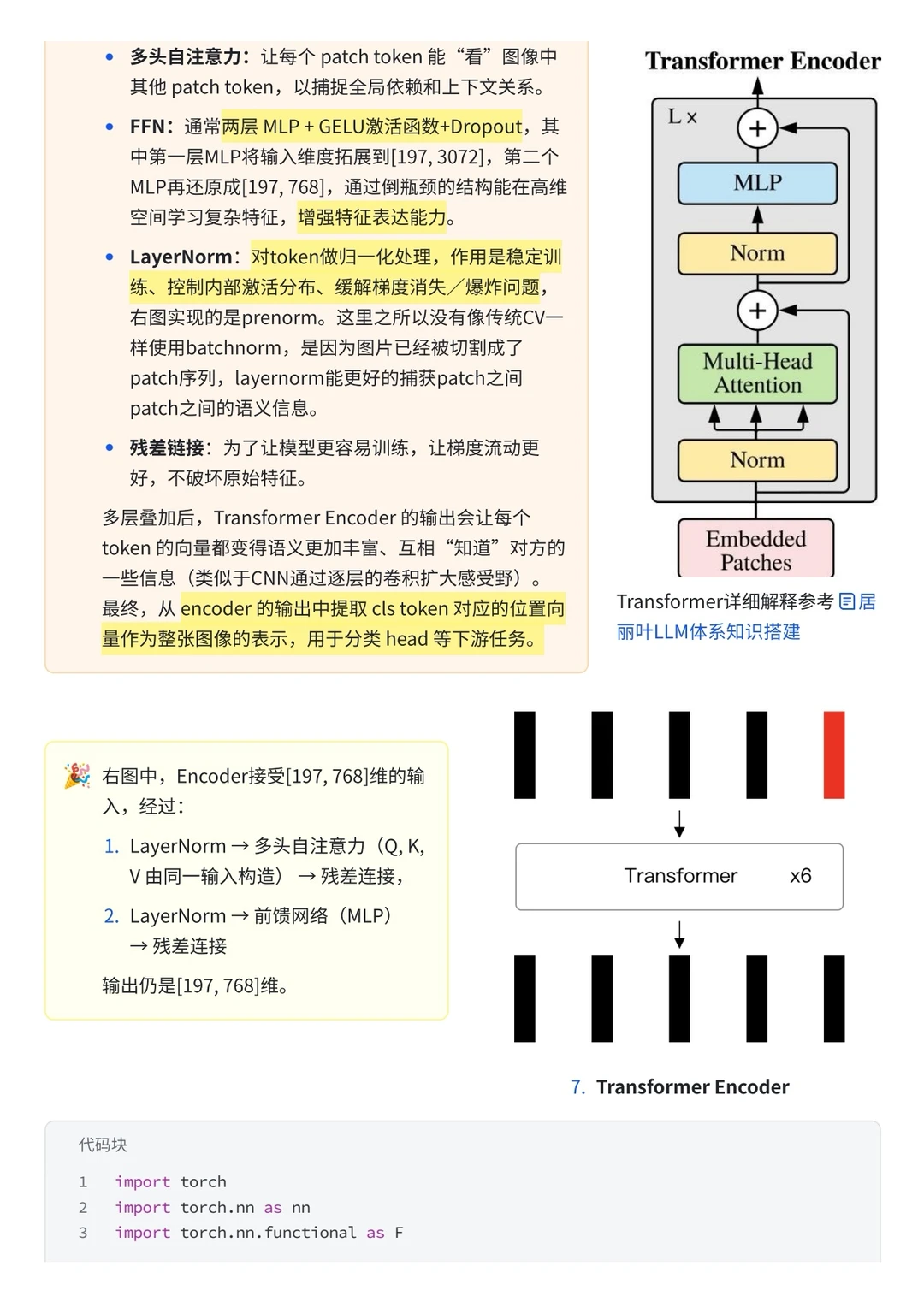
今天来学ViT,可以看做是现在众多视觉-语言大模型的基石技术。其核心思想就是——把图像当作一串tokens来处理。
本文目录如下:
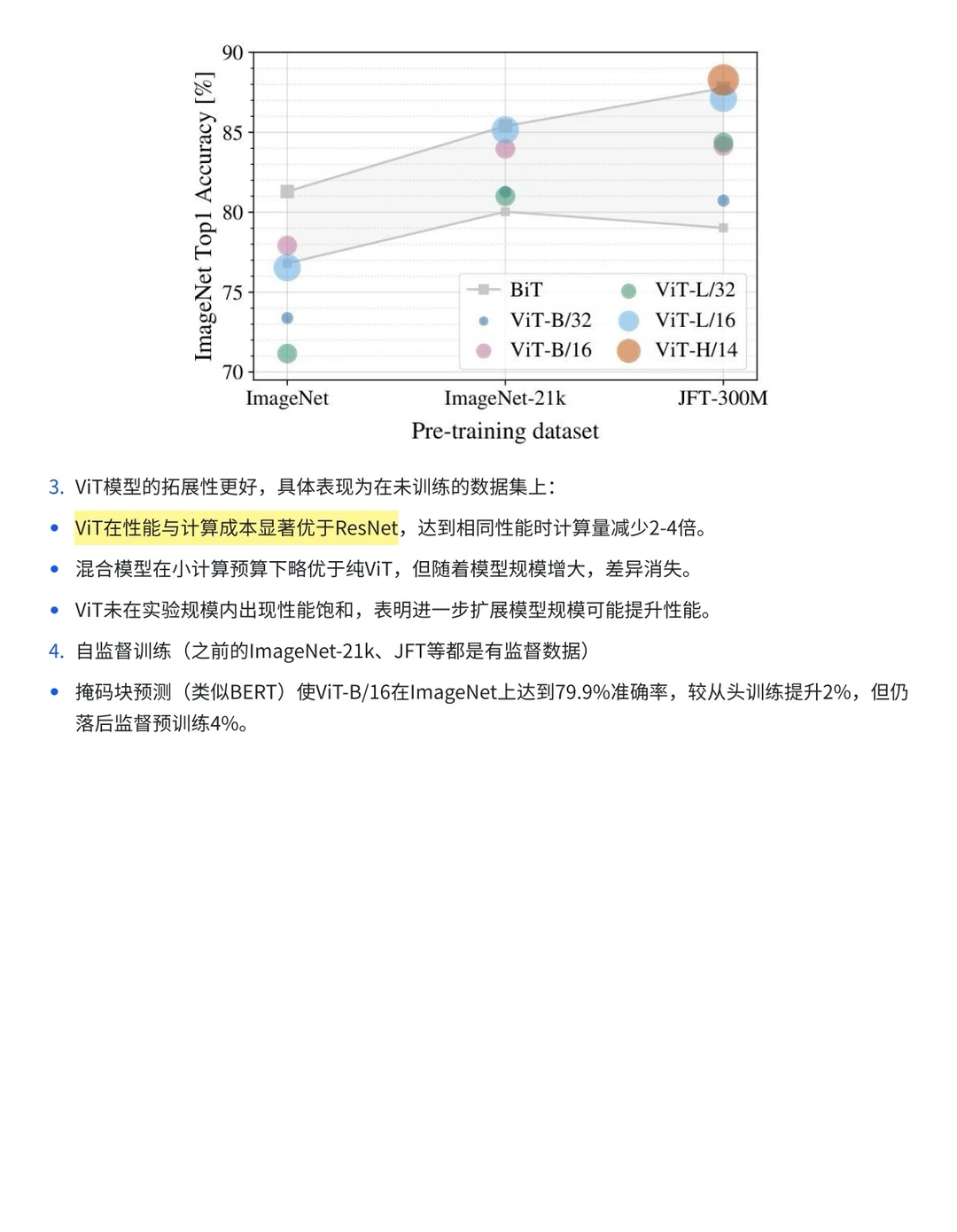
1️⃣从CNN到ViT
2️⃣ViT的模型架构
3️⃣代码解析
4️⃣模型训练流程及实验结论
视频推荐看up主bryanyzhu的讲解,学术水平很高,讲解深入浅出的同时兼顾论文写作技巧。
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量