省流版:
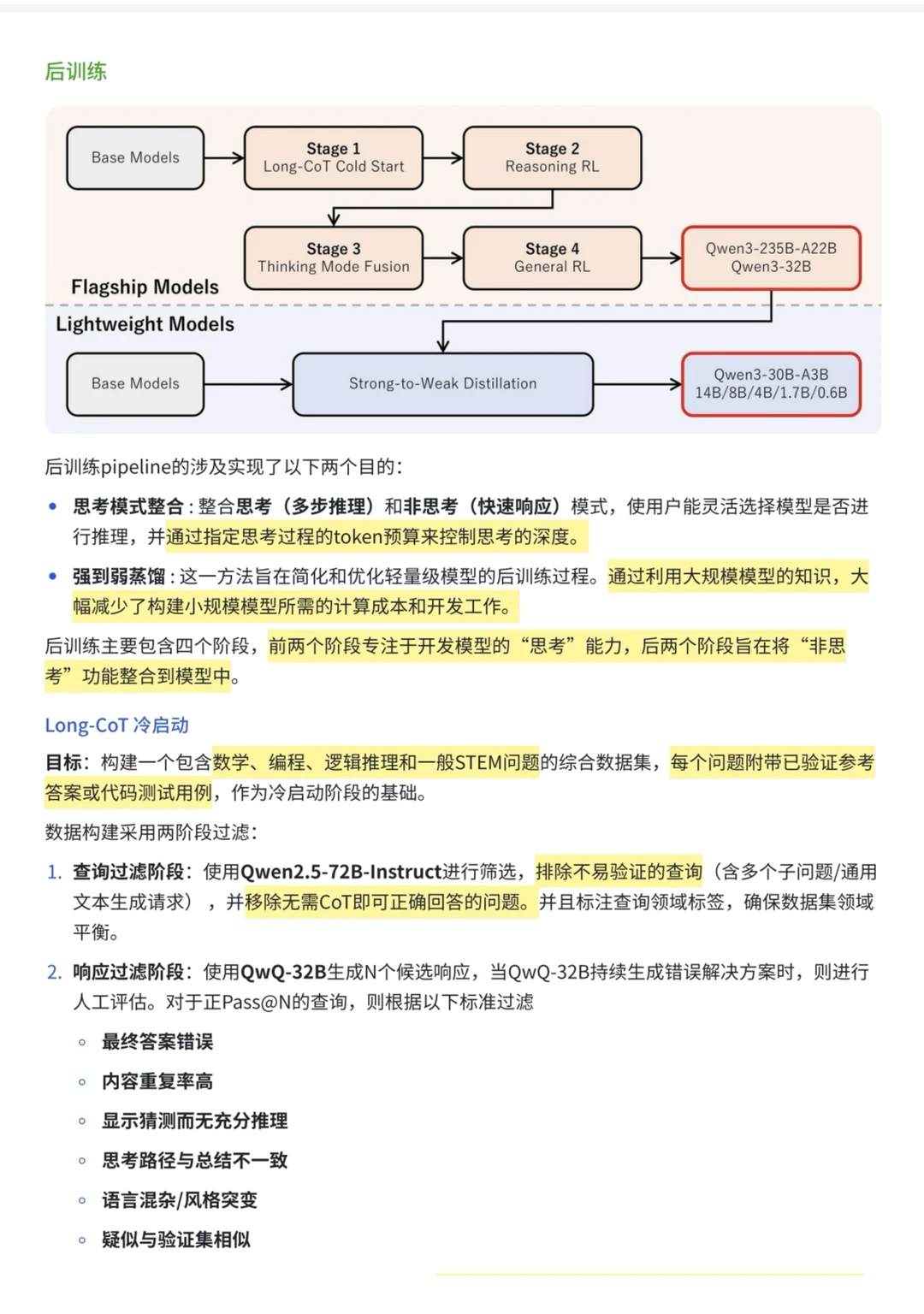
1️⃣三阶段预训练
[打卡R]step1通用基座:4 096 token 上下文,累积 30 万亿 token,构建语言与常识能力。
[打卡R]step2推理强化:继续在 4 096 token 长度下追加 5 万亿 高质量 STEM/Code 样本,加速学习率衰减。
[打卡R]step3长上下文扩容:采用ABF+ YARN + DCA,将窗口扩展至 32 768 token,训练数千亿 token。
2️⃣长 CoT 冷启动:先用 Qwen2.5‑72B-Instruct进行用户query筛选 提升样本质量与多样性,再用QwQ-32B生成候选响应。
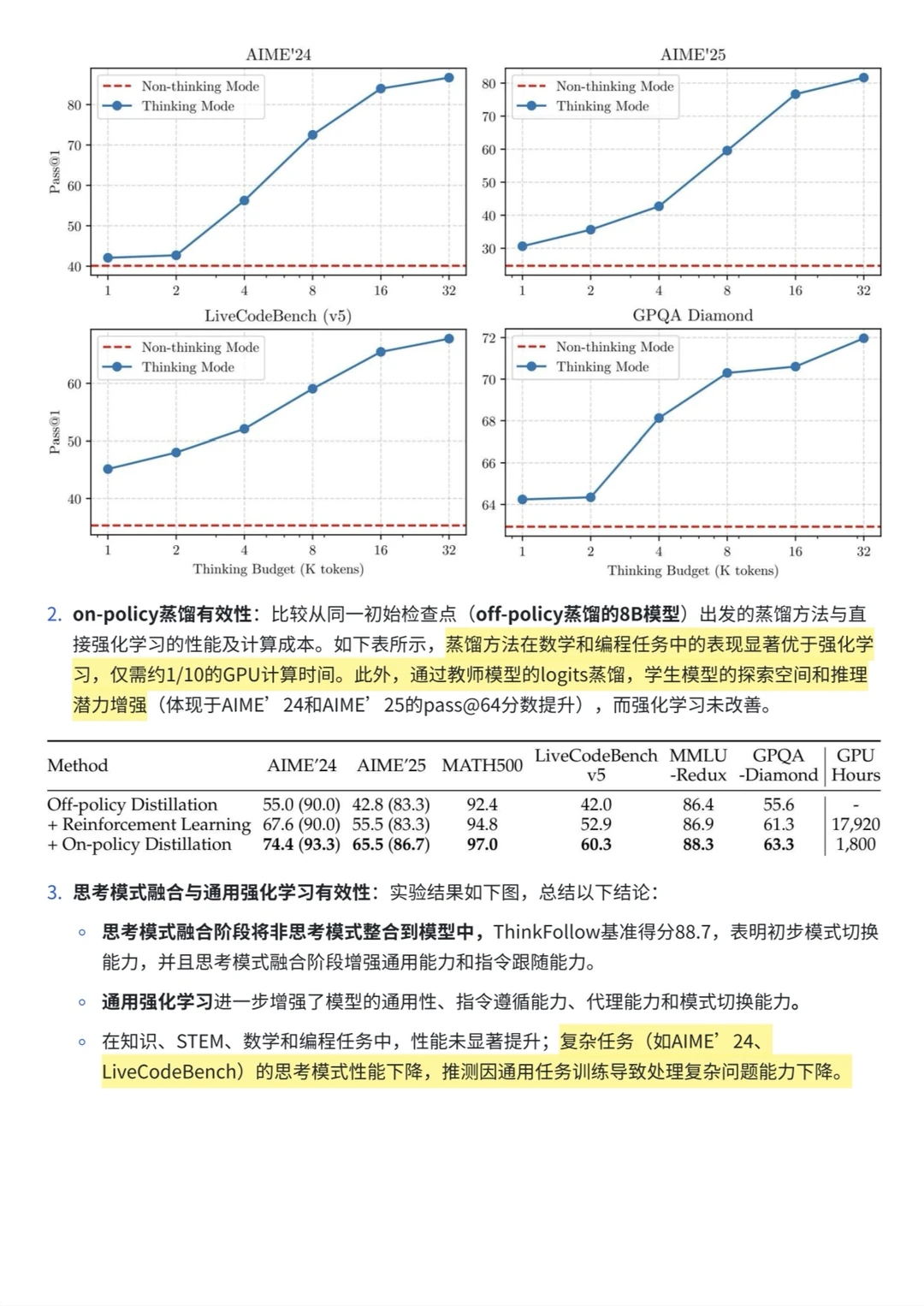
3️⃣推理 RL(GRPO):选取多样且困难的问题,使用GRPO,大 batch + off-policy训练,只需170步即可让Qwen3-235B-A22B模型在 AIME’24 分数从 70 提升到 85+。
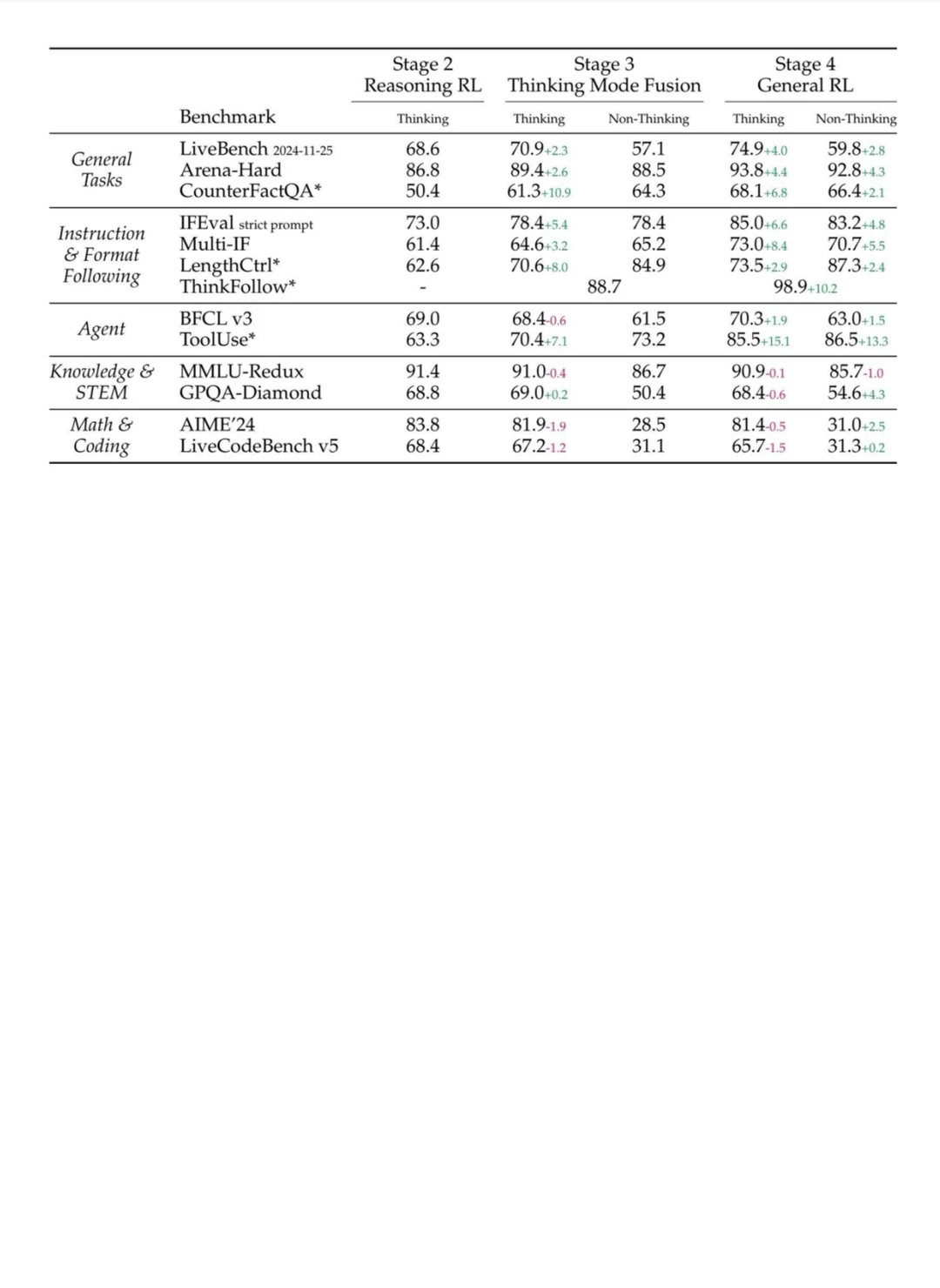
4️⃣思维链显/隐控制:在词表注入专用 special token,并在 prompt 中使用 /think 与 /no_think 标签实现显式模式切换;训练结果显示,模型还能自发学会短 CoT,兼顾低延迟与准确度。还可通过 thinking budget 截断思考 token,动态平衡速度与准确率。
5️⃣奖励模型设计:覆盖 20 + 任务域(指令遵循、格式一致、偏好对齐、Agent 工具调用、RAG 等),为每个子任务定制评分规则,结合基于规则的Reward、参考答案评分、无参考的偏好模型评分三种信号,保证 RL 阶段反馈精准且稳定。
6️⃣轻量蒸馏:
[打卡R]off-policy蒸馏(教师多模式输出)。
[打卡R]on-policy蒸馏(学生自行 roll‑out,再按 KL 对齐教师),仅 1/10 GPU‑hours 即把双模式推理能力下迁到 14B / 8B / 30B‑A3B 等小模型,效果显著优于纯 SFT。