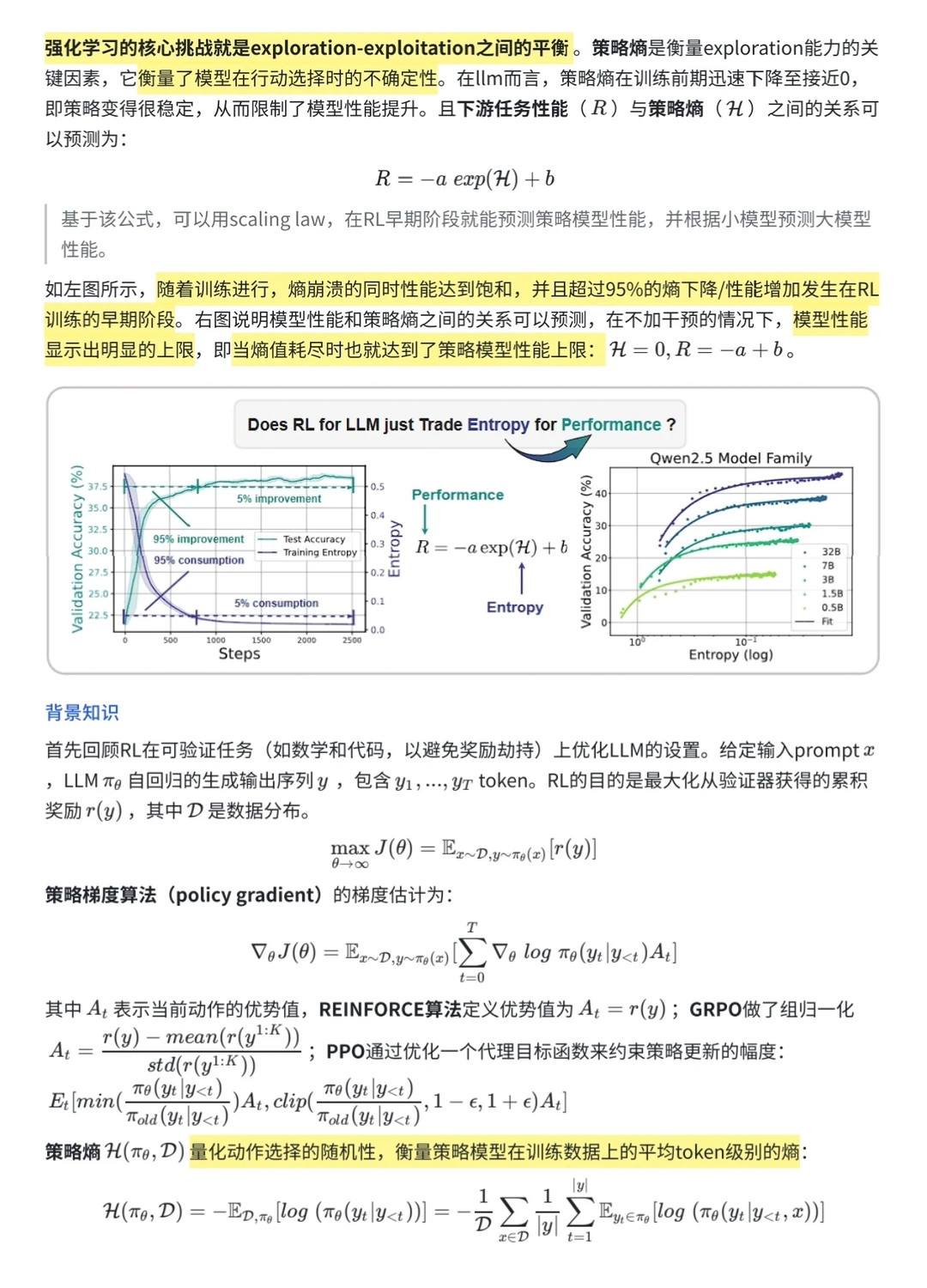
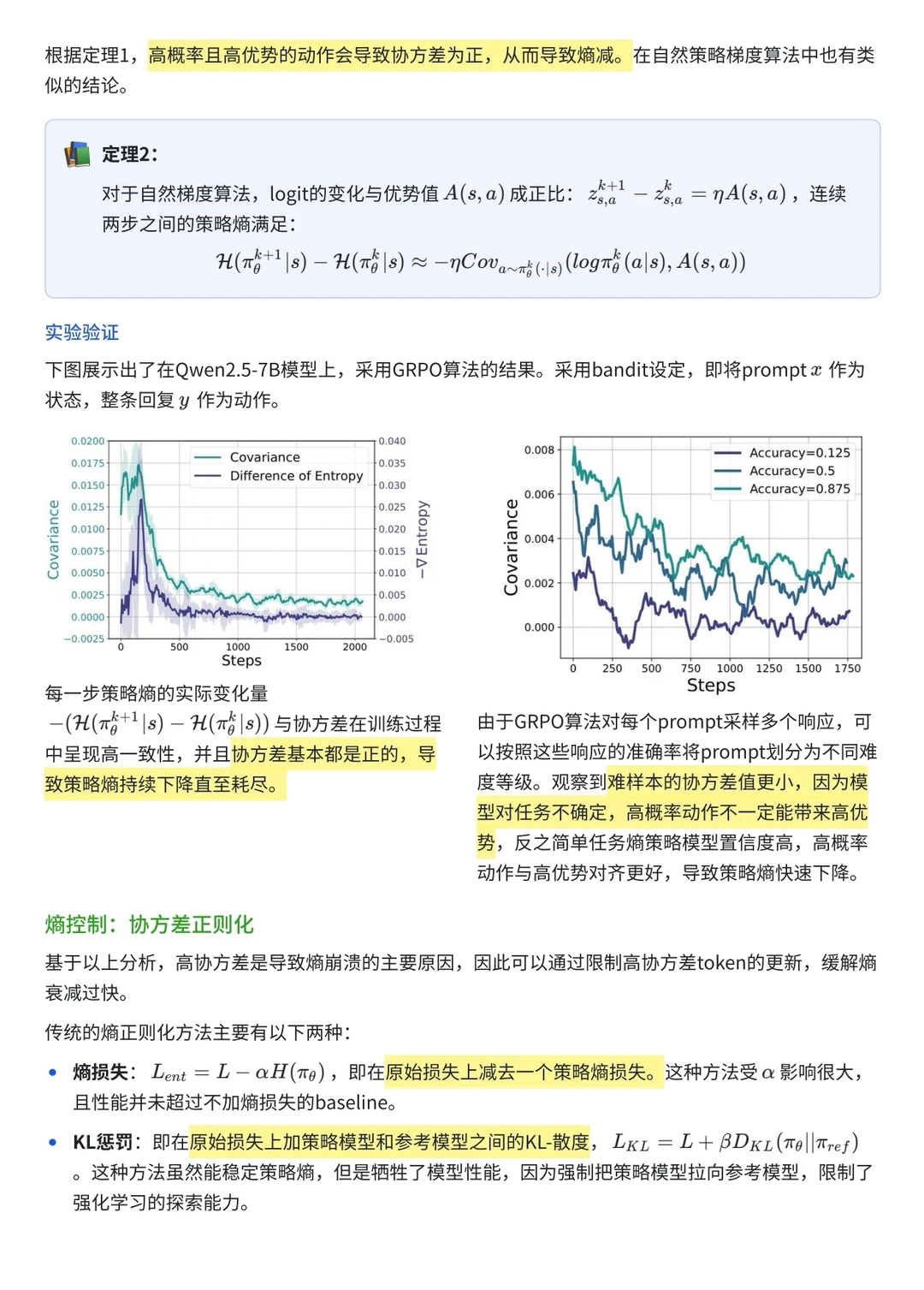
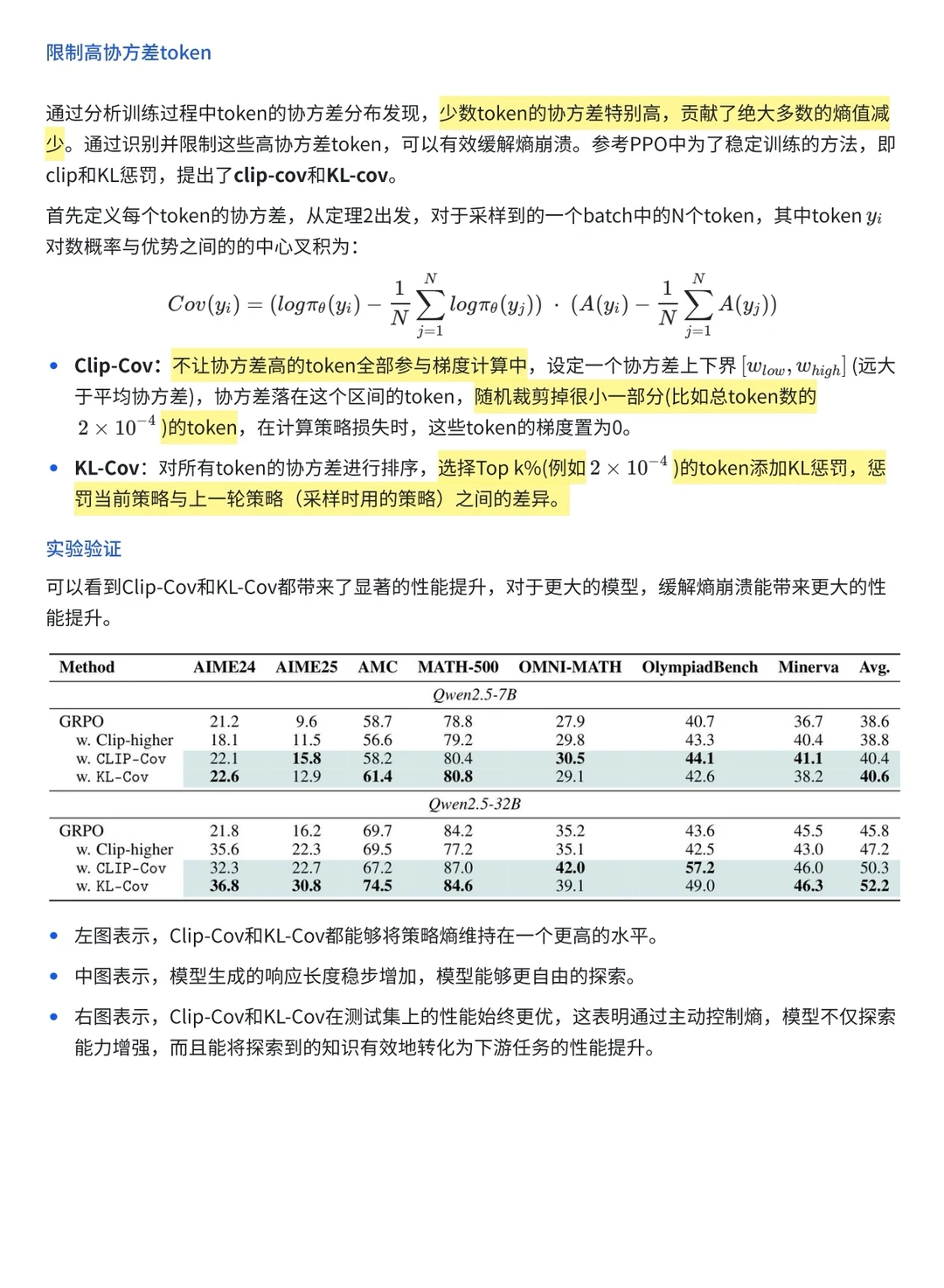
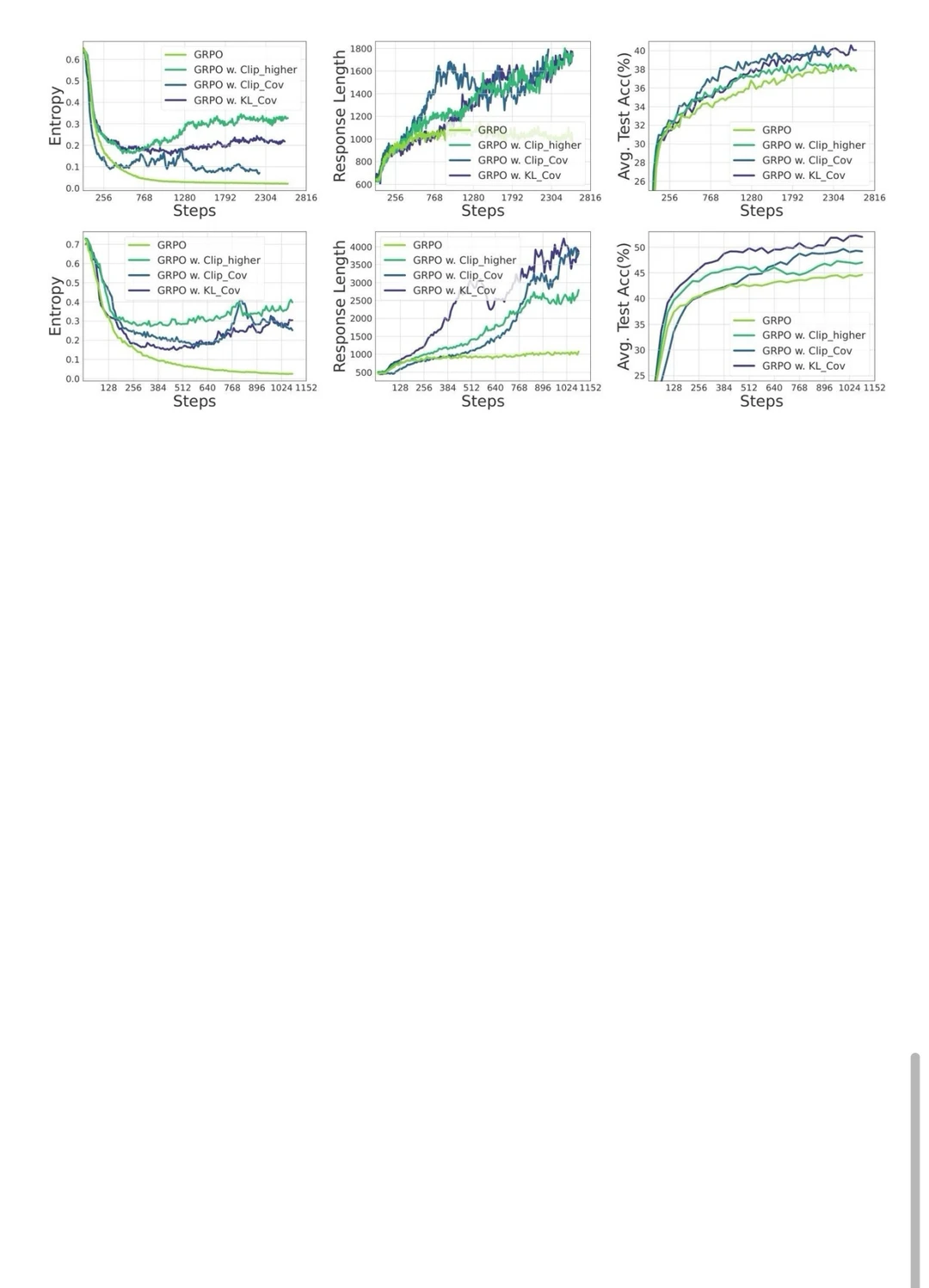
什么叫熵崩溃?
就是模型一开始还有点探索精神,结果训练没多久就变得非常确定,只会选很少的几个动作——基本就不探索了,变成“一招鲜吃遍天”。这样会导致模型的表现(reward)刚开始进步很快,过一会儿就到天花板,再也上不去了。
实测发现,换算法其实影响不大,真正决定reward上限的是模型多大、数据复杂度、难度这些因素。所以只想靠换RL算法,没什么用。
怎么办?
先来分析一下哪些动作会让policy熵掉得特别快,就是那些本来概率很高、又特别有优势的动作。而相反,有些不太可能被选中的动作,如果它们偶尔表现好,其实能帮模型涨熵。
基于这个分析,作者提出了两种简单但很有效的控熵方法:Clip-Cov和KL-Cov。简单来说就是,盯住那些容易让熵崩溃的token,别让它们影响太大,这样模型就能持续探索、表现也能持续提升。