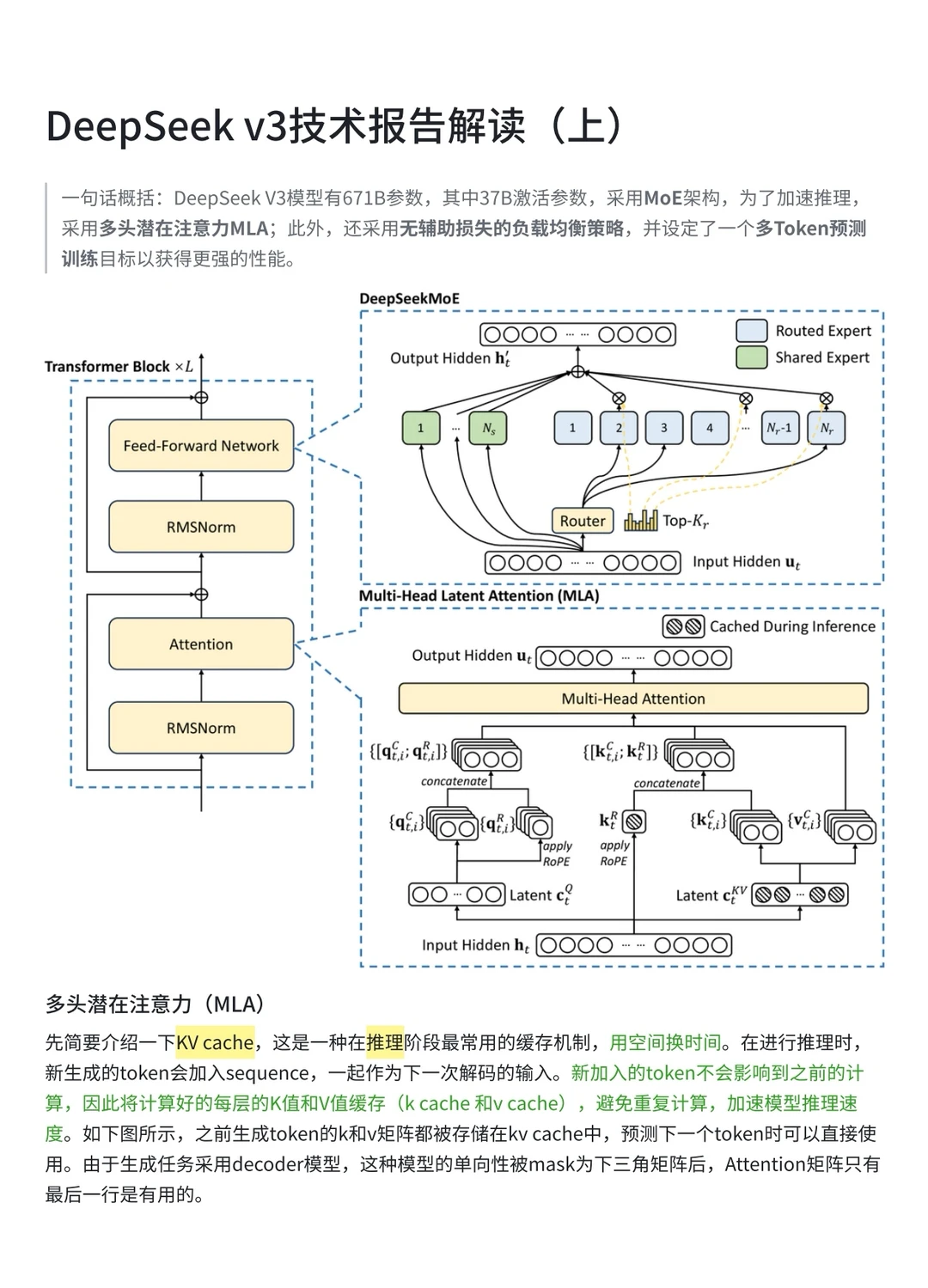
本文主要解读DeepSeek v3技术报告中提及的MLA、Moe、多token预测。
下面梳理一下DeepSeek全系列模型的发展历程:
1️⃣24年1.5日,DeepSeek LLM发布,没太多创新类似llama那一套(llama1的RoPE/RMSNorm/SwiGLU+llama270B或llama3的GQA)
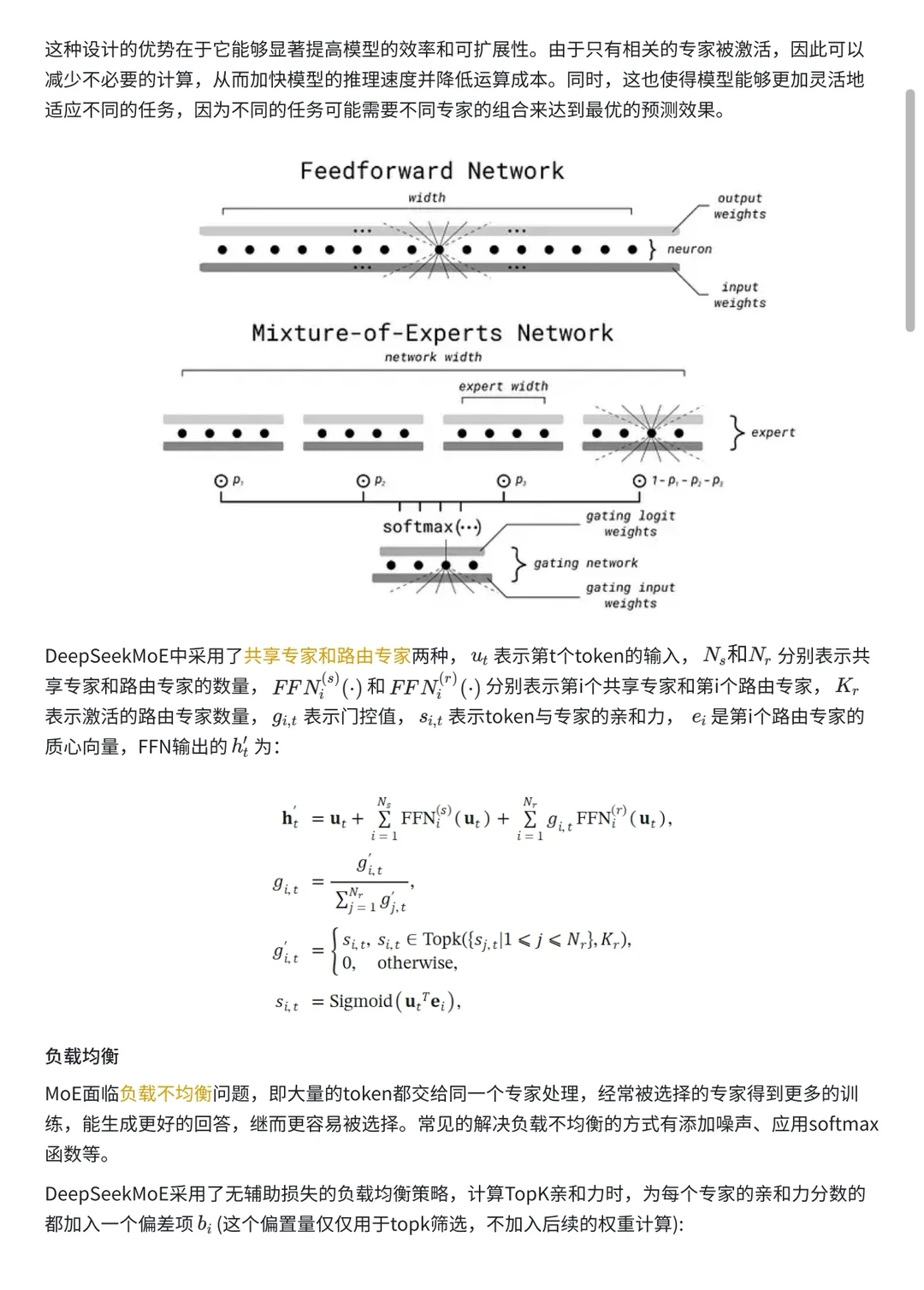
2️⃣24年1.11日,DeepSeekMoE,开启创新之路提出细粒度专家分割和共享专家隔离,以及一系列负载均衡。
3️⃣24年1.25,发布DeepSeek-Coder24年2月,发布DeepSeekMath提出了GRPO,以替代PPO--舍弃critic模型
4️⃣24年5.7日,DeepSeek-V2,提出多头潜在注意力MLA且改进MOE,其中的MLA是整个deepseek系列最大的几个创新之一,且由此引发了各大厂商百万token的大幅降价。
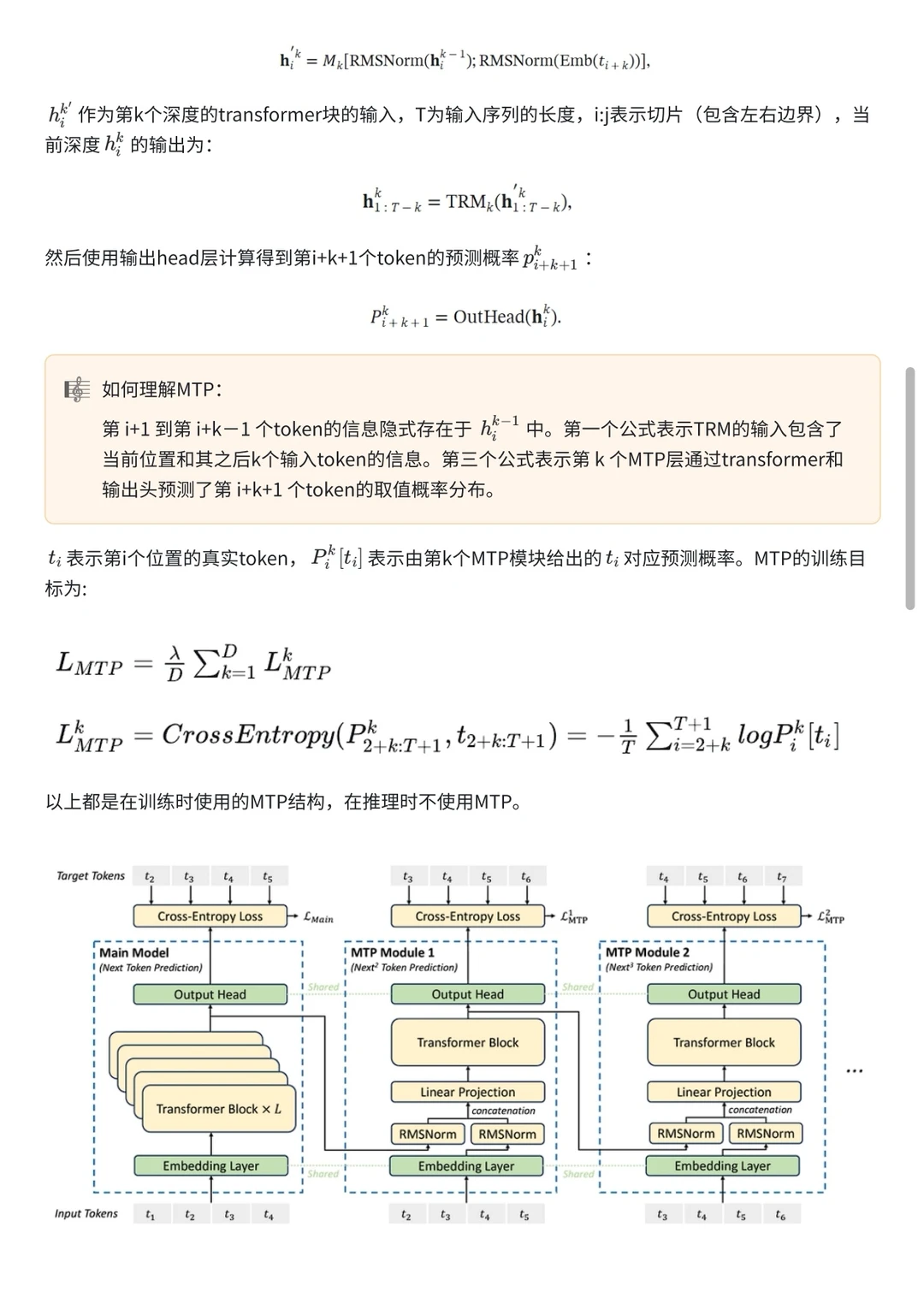
5️⃣24年12.26日,DeepSeek-V3发布在MOE、GRPO、MLA基础上提出Multi-Token预测,且含FP8训练
大家纷纷把它和Llama3.1 405B对比,V3以极低的训练成本造就超强的效果,再度出圈。
6️⃣25年1.20日,DeepSeek R1发布,
一方面,提出舍弃SFT、纯RL训练大模型的范式,且效果不错;
二方面,性能比肩o1甚至略微超越;
占三方面,直接公布思维链且免费,不像o1那样藏着掖着,对用户极度友好。