DC娱乐网
字节& 清华开源DAPO算法让GRPO更精致
2026-02-17 03:00:31
奔跑的跳跳
科技
字节与清华强强联合,推出了开源的DAPO算法,基于 Qwen2.5-32B 模型在 AIME 2024 上超过了之前最先进的 DeepSeek-RL-Zero-Qwen-32B,在long-CoT场景大放异彩。这个让模型更聪明的秘诀,藏在四大黑科技里:
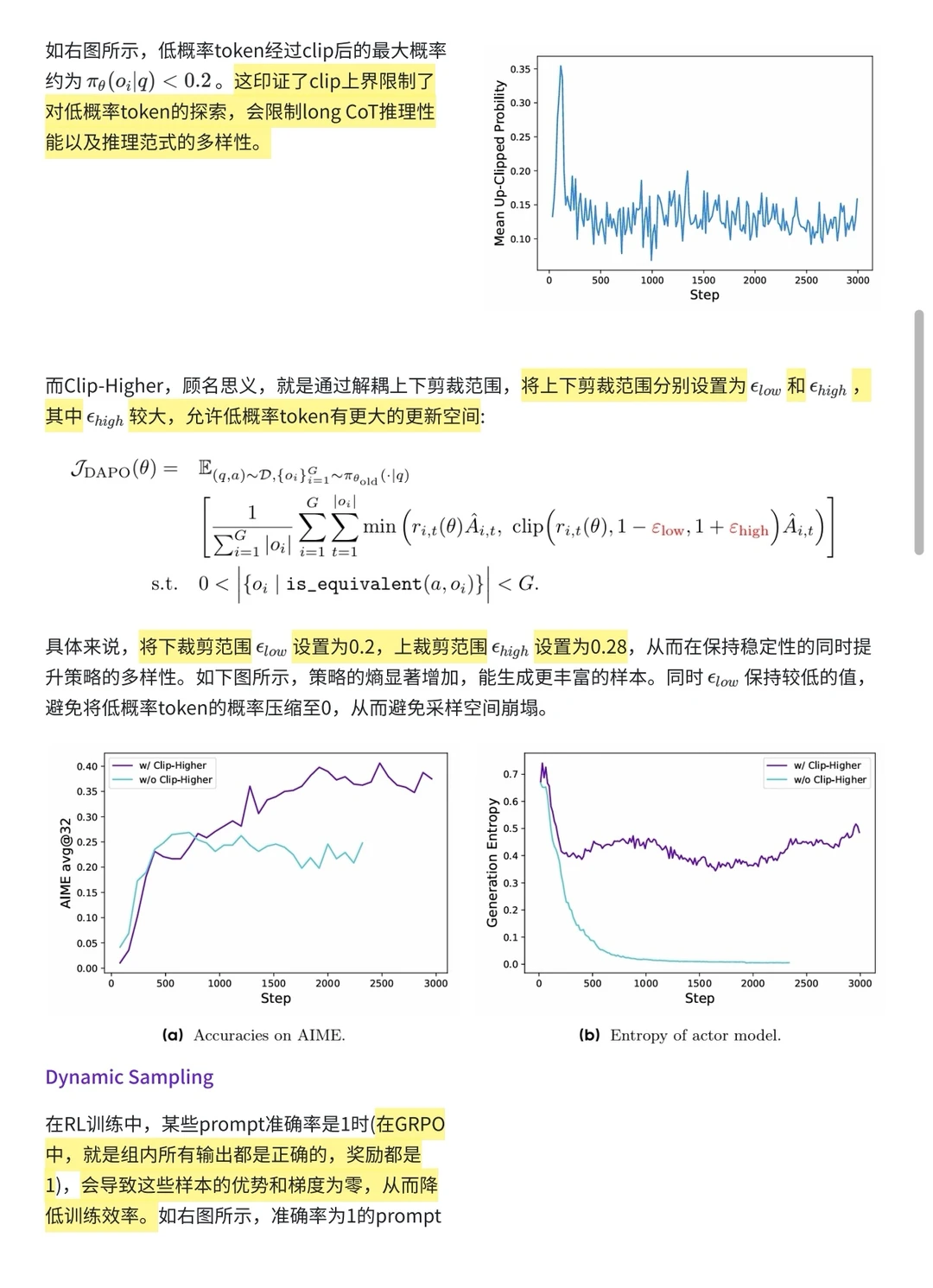
[海豚R]解耦裁剪:提高clip上界,避免熵崩溃,既保持了思维的严谨性,又让模型的回答充满惊喜创意。
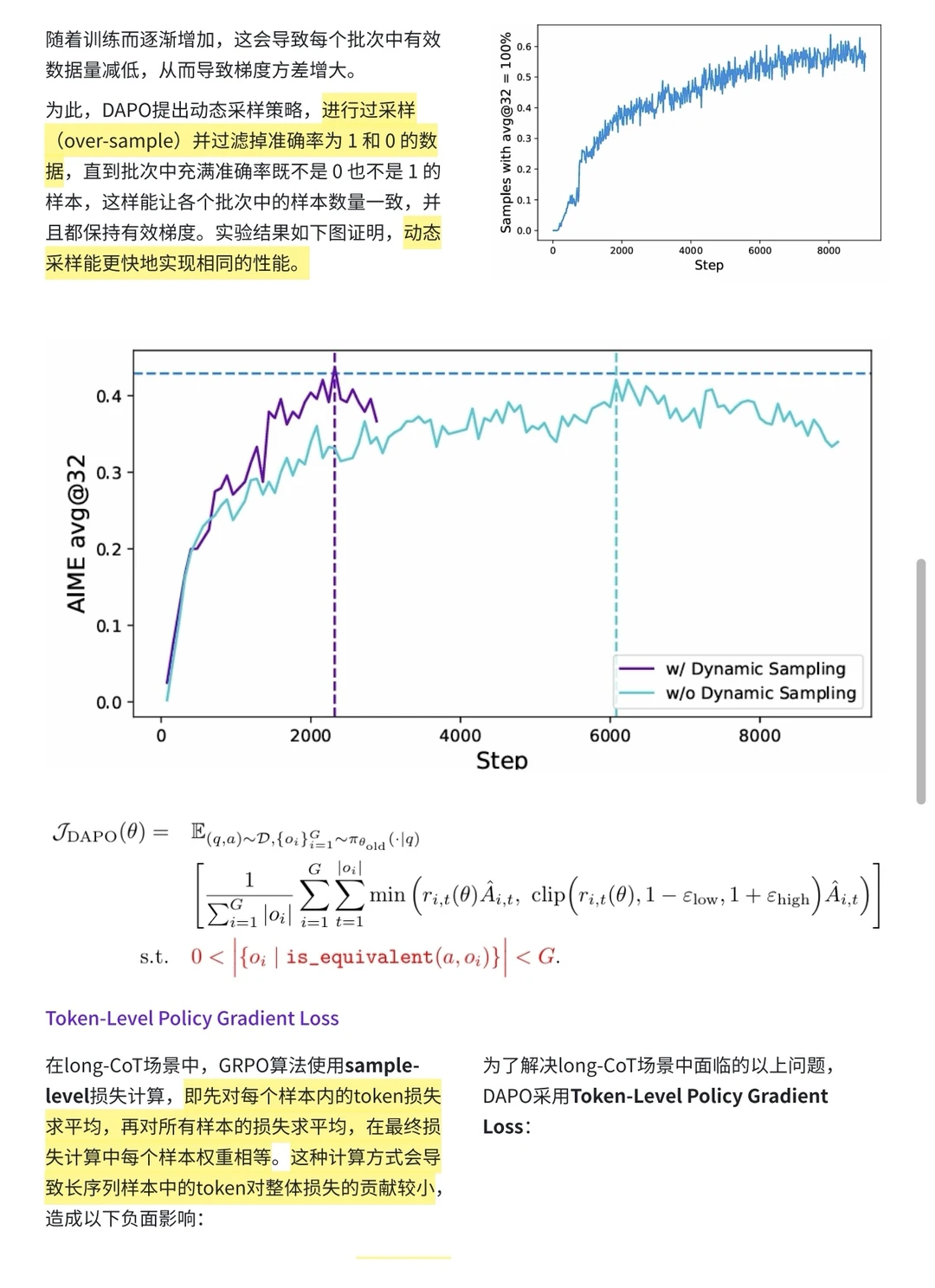
[海豚R]动态采样:过滤掉准确率为 1 和 0 的数据,自动过滤掉太简单或超纲的题目,提升训练效率和稳定性。
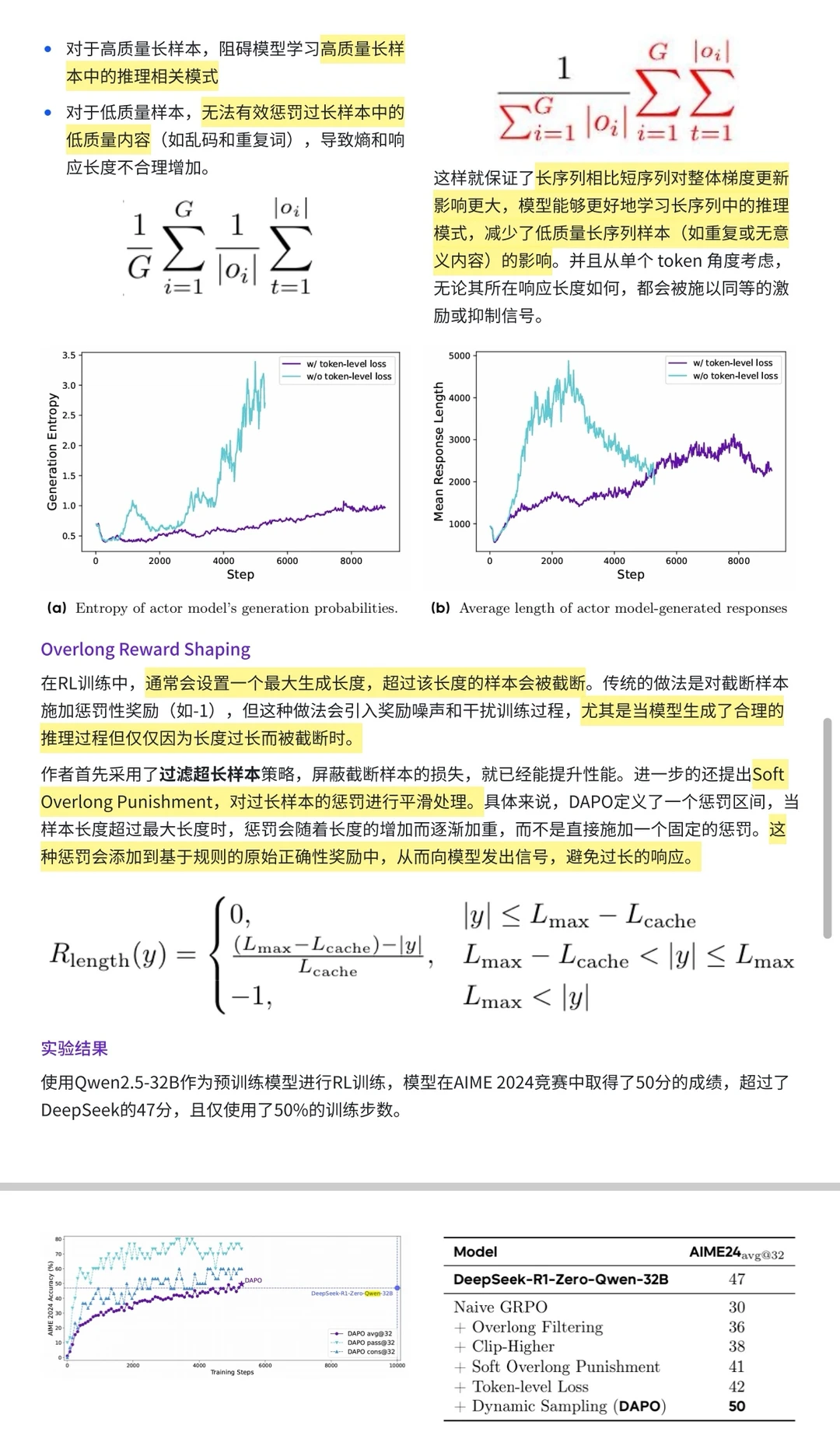
[海豚R]token级梯度损失:提升长序列样本中的token对整体损失的影响,使得模型能够更好地学习长序列中的推理模式(long-CoT)。
[海豚R]过长样本奖励调整:对过长样本的惩罚进行平滑处理,用渐进式调整让模型明白:不是文章越长越好,而是要把复杂问题说清楚。
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量