【人类智慧被私有化了,这才是AI最大的问题】
快速阅读:AI本质上是人类集体知识的结晶,但却被少数科技公司几乎免费攫取并商业化。谁来拥有它、谁来控制它,已经不是技术问题,是政治问题。
---
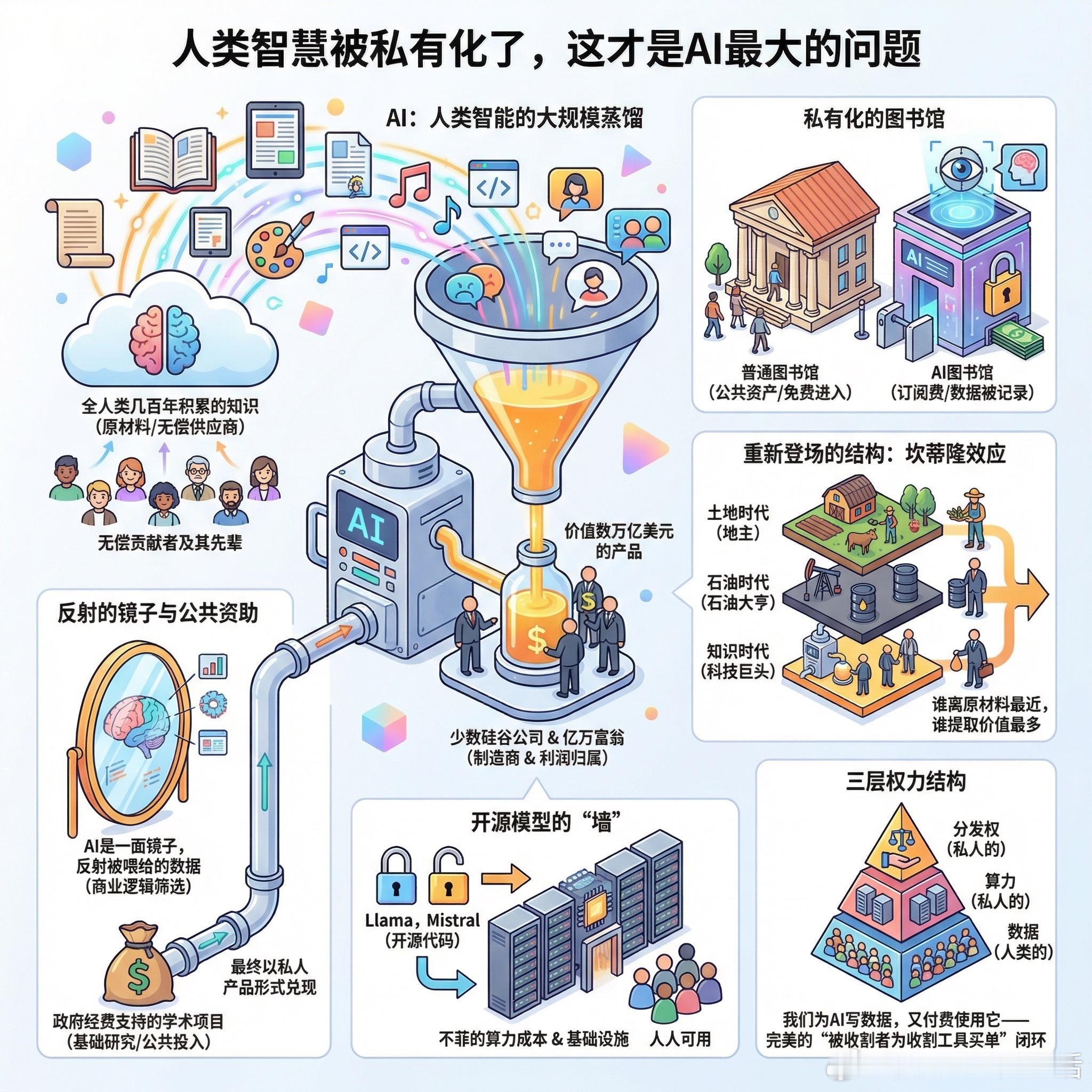
Jason Hickel提出了一个让人不舒服的观察:我们把AI叫做“人工智能”,其实它更像是人类智能的一次大规模蒸馏。每一个发过帖子、写过文章、画过画的人,还有他们的老师、老师的老师,都在无意间成了这场训练的“无偿供应商”。
换句话说,这个价值数万亿美元的产品,原材料是全人类几百年积累的知识,制造商是几家硅谷公司,利润归少数亿万富翁。
有观点认为,训练数据或许是集体的,但用于训练的算法、数十亿美元的算力、模型架构设计,这些可不是白来的,建数据中心、付电费的人也有自己的主张。这个反驳成立,却并不能消解原始问题的锋芒:收益应该流向谁?
有人把AI比作图书馆,公司不过是建了一个更聪明的图书管理员。但这个比喻失去了一个细节:普通图书馆是公共资产,任何人可以免费进入;现在这个图书馆,你每个月要付订阅费,而且馆长还拥有你借阅记录的全部数据。
有网友用“坎蒂隆效应”来描述这个结构:谁离原材料最近,谁提取的价值就最多。石油时代是这样,土地时代是这样,现在轮到人类的集体知识了。结构从未改变,只是换了个技术外壳重新登场。
还有一个更深的问题鲜少被认真对待。有人指出,AI不是在“理解”知识,它是一面镜子,把储存的人类智慧反射回来,本质上是计算,没有传统意义上的思考。这面镜子能照出多少真实,取决于我们喂给它什么。而“喂”这件事,由私人公司决定、用商业逻辑筛选。
公共资助这件事也值得一说。有人翻出了记录:AI背后的基础研究,相当一部分来自政府经费支持的学术项目,几十年的公共投入,最终以私人产品的形式兑现,这是商业化的正常逻辑,但说“完全是私人创造”就有些言过其实了。
开源模型算不算出路?勉强算。Llama、Mistral这类模型确实向公众开放,但运行一个像样的推理服务,仍需要不菲的算力成本,“开放代码”和“人人可用”之间还隔着一道基础设施的墙。
有网友的判断最直接:数据是人类的,算力是私人的,分发权也是私人的。这是一个三层权力结构,讨论AI归属问题,如果只盯着最上面那层,下面两层根本没动过。
---
简评:
这篇文章戳破了一个精致的谎言。人类花了五百年把土地私有化,两百年把石油私有化,现在只用了十年就把集体智慧私有化了——效率确实在进步,只是进步的方向令人不安。 所谓“AI是人类智慧结晶”,翻译成政治经济学就是:矿藏是公共的,矿主是私人的,而你连矿工都不算,顶多是被挖走的那块矿石。最讽刺的是,我们一边为AI写训练数据,一边付费使用它,完成了一个完美的“被收割者为收割工具买单”的闭环。历史从未改变,只是换了个算法外壳重新登场。
---
x.com/jasonhickel/status/2025657976434893206