刚参加完一场智算行业交流会,发现政企朋友们都提到一个趋势:未来,十万卡级的算力集群将成为标配,而当下万卡集群已经卷起来了。
但大家私下讨论最多的,就是当万张加速卡全力运转,为何AI训练还是快不起来?你可能没想到,真正的瓶颈不在算力,而在一个常被忽视的环节:存力——明明GPU规模拉满,却因为数据吞吐跟不上,模型训练周期动辄拉长数月。
当AI模型迈入万亿参数时代,堆砌GPU数量已不是难题,关键在于如何让海量数据以最低延迟、最高效率“喂饱”这些计算核心。传统存储架构在万卡集群面前,往往成为那条拖慢整个系统的独木桥。
曙光存储的思路很值得借鉴:它发现,问题的核心在于存储与计算之间的“速度断层”。为此,他们提出了一个关键解法:从“存数据”转向“喂数据”,让存力主动协同算力。
其核心技术“超级隧道”,在存储与GPU之间修建了一条直达专线,通过零中断、零竞争、零拷贝的设计,让数据传输路径更短,并且一路绿灯。结果是:推理延迟降低80%,训练速度提升4倍,万亿参数模型训练周期缩短60%以上!
而另一大核心技术“AI数据工厂”,让存储系统能主动预处理、调度数据,甚至能够理解AI工作流的独特需求——比如在推理时,主动将部分计算任务卸载到存储侧处理,显著提升响应速度。这意味着存储系统开始“主动思考”,提前准备好算力最需要的数据形态。
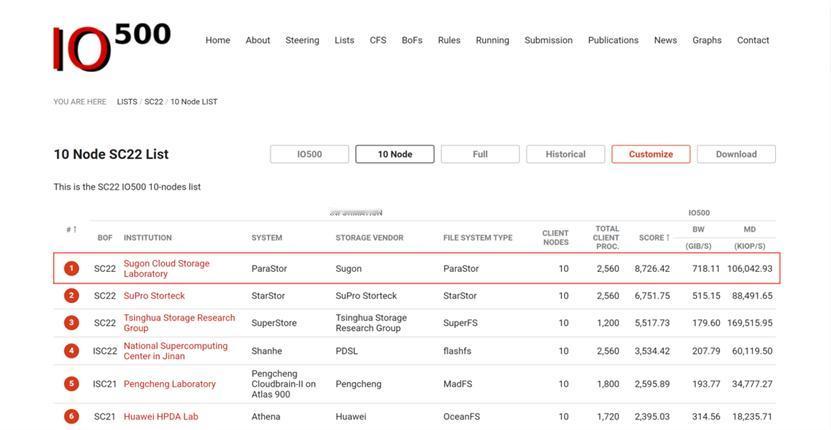
支撑这套体系的是硬核的产品矩阵:刷新IO500纪录的分布式存储ParaStor F9000,220GB/s单节点带宽、800万IOPS,能够支撑起十万卡集群的数据洪流;在SPC-1测试中创造3000万IOPS、0.202ms延迟世界纪录的集中式存储FlashNexus,则能轻松应对最极致的性能需求。
可以看到,在AI竞赛的下半场,决胜点已不在单纯的算力堆叠,而在于如何让数据与计算“无缝对话”。一场由存力驱动的效率革命,已经悄然开始。