刚刚,理想汽车发布 MindVLA-o1 模型,詹锟主讲。前两年连续在 GTC 代表理想汽车主讲的贾鹏,现在自己创业做机器人了,昨天也讲了很多有关具身智能相关的思考。
MindVLA-o1 是如何诞生的呢?原因是理想汽车发现现在业界 VLA 的局限性。
1. 3D 空间、语言、思考之间存在对齐效率不一致的情况;2. 长尾场景需要结合合成数据和强化学习;3. 计算效率和系统成本,未来的方向必须是软硬协同的架构设计。(暗示自研芯片)
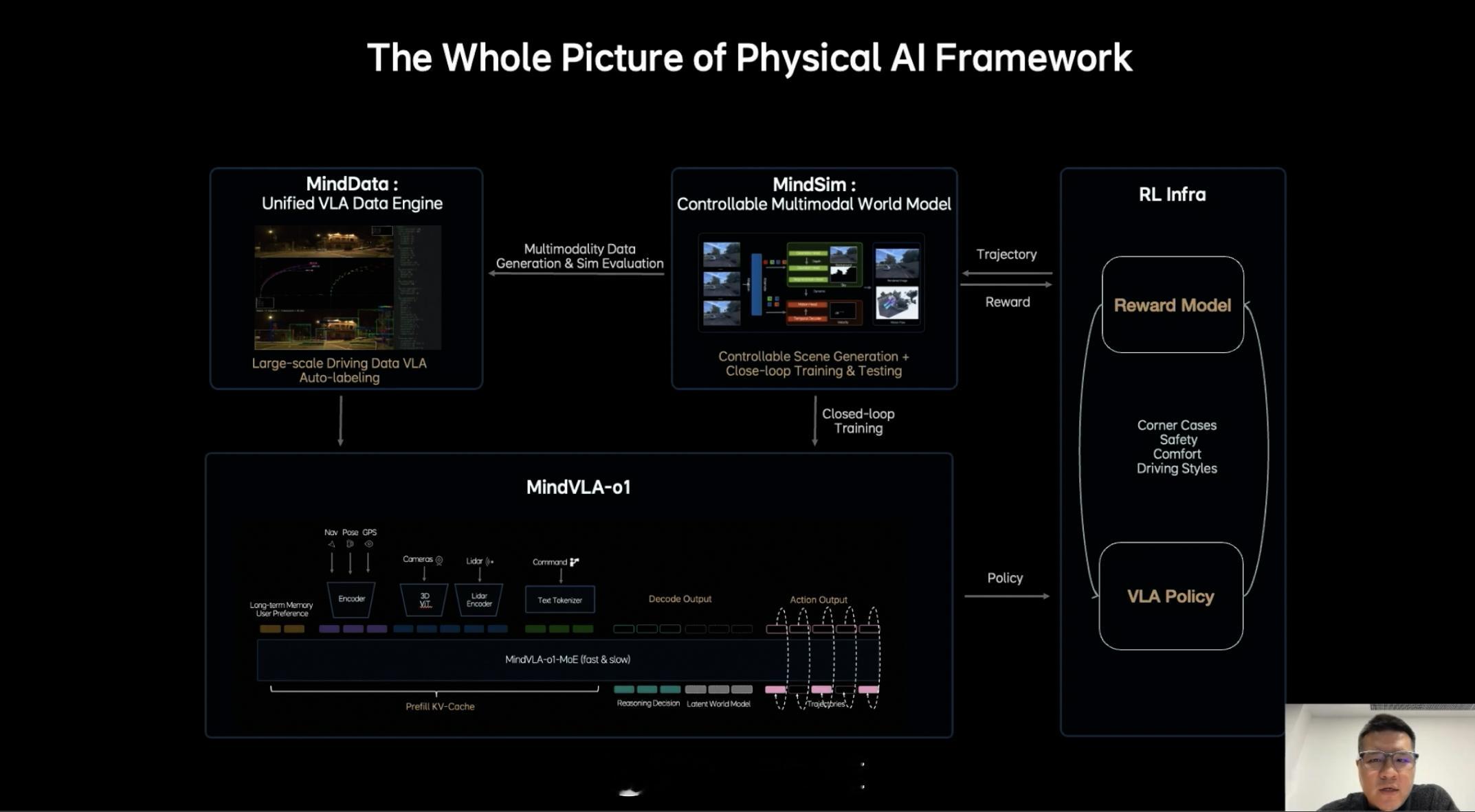
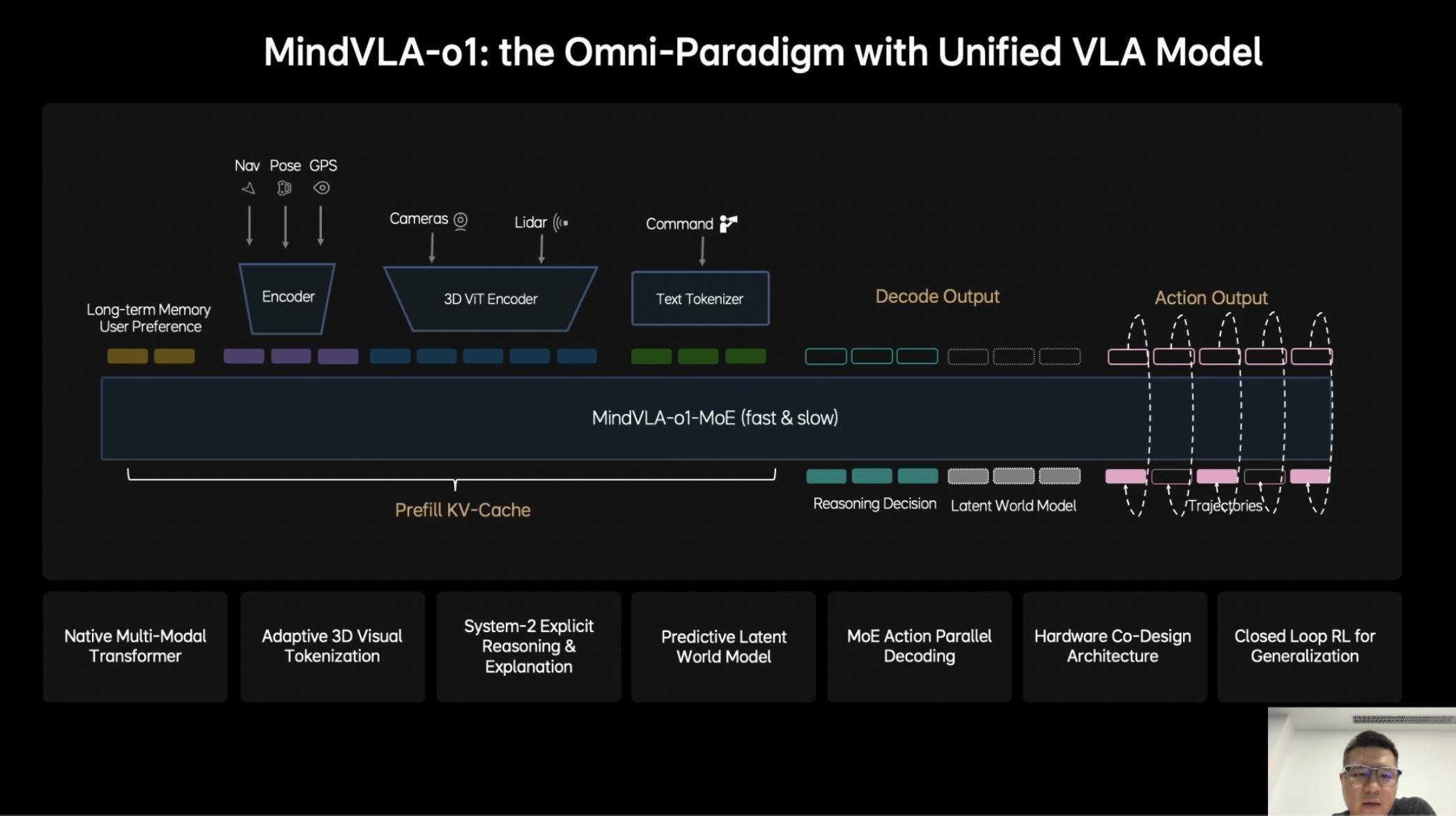
基于此,理想汽车推出了下一代统一架构 MindVLA-o1,有这样几个设计原则。
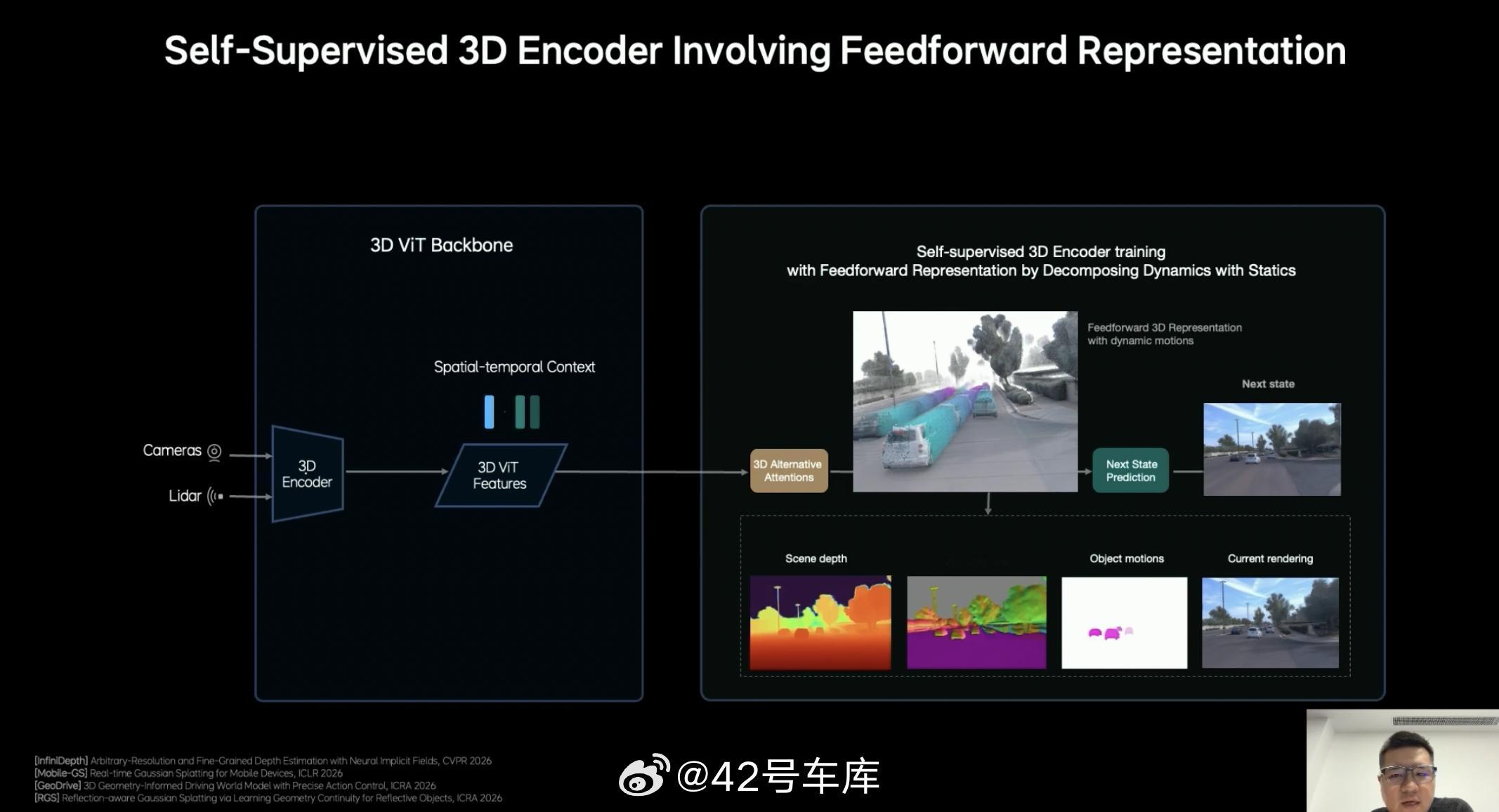
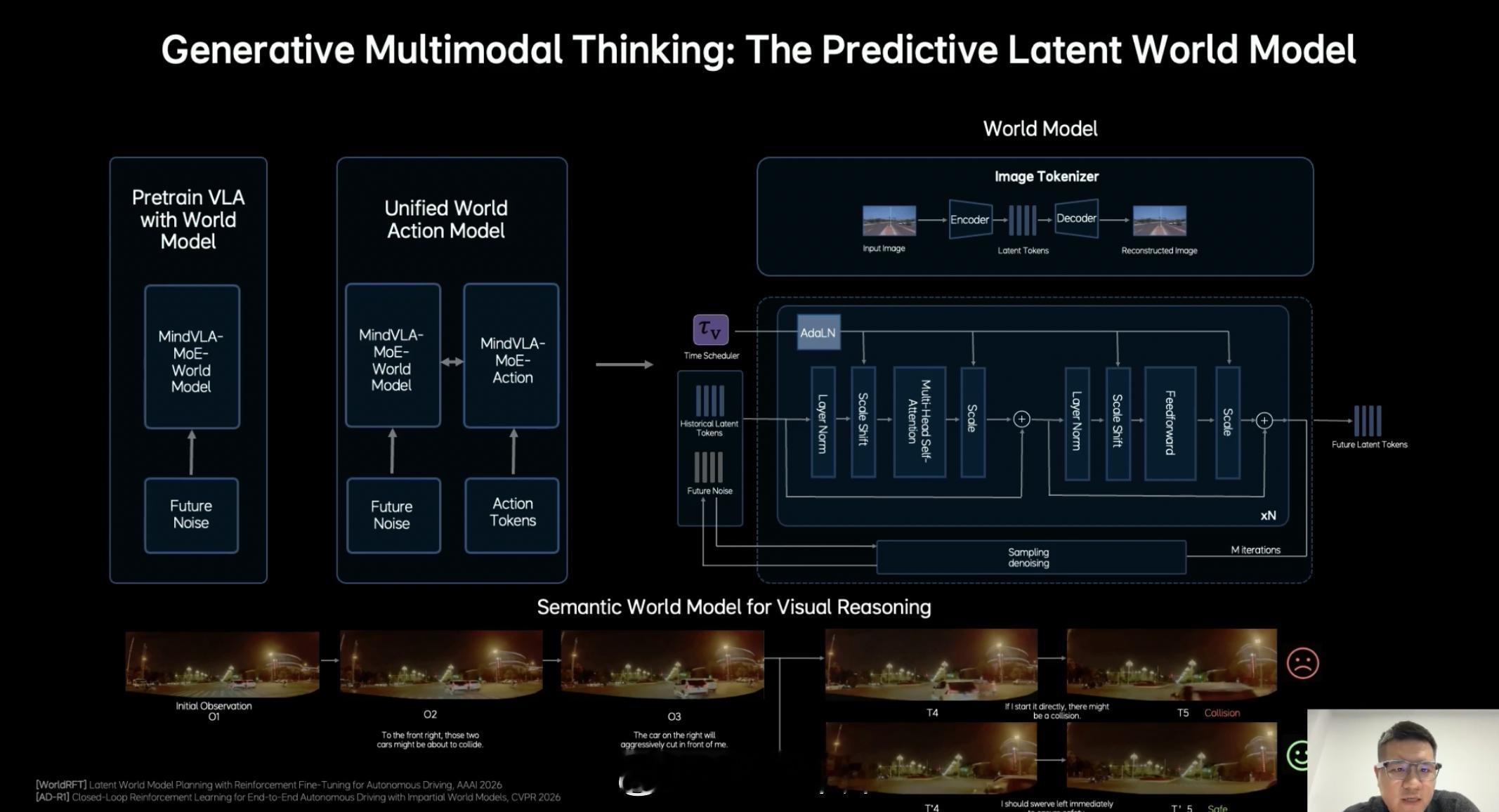
1. 具备原生多模态 MoE Transformer 架构,模型设计之初,就统一进行视觉、语言行动的训练,而不是分别训练再融合(对齐,并且有更强的泛化能力)。2. 原生 3D 视觉 Tokenizer,引入 3D ViT 编码器,用视觉建模 3D 世界。让模型能更自然地理解空间结构。3. 多模态推理能力。语言模型承担语义理解、常识知识、交互能力,同时引入显示推理能力。4. 隐式世界模型,通过 Predictive Latent Model,模型可以对未来的环境进行预测。5. 软硬件协同设计和强化学习闭环能力。
42how新能源汽车理想发布MindVLA-o1