[LG]《M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling》M Mishra, S Tan, I Stoica, J Gonzalez… [UC Berkeley & MIT-IBM Watson Lab] (2026)
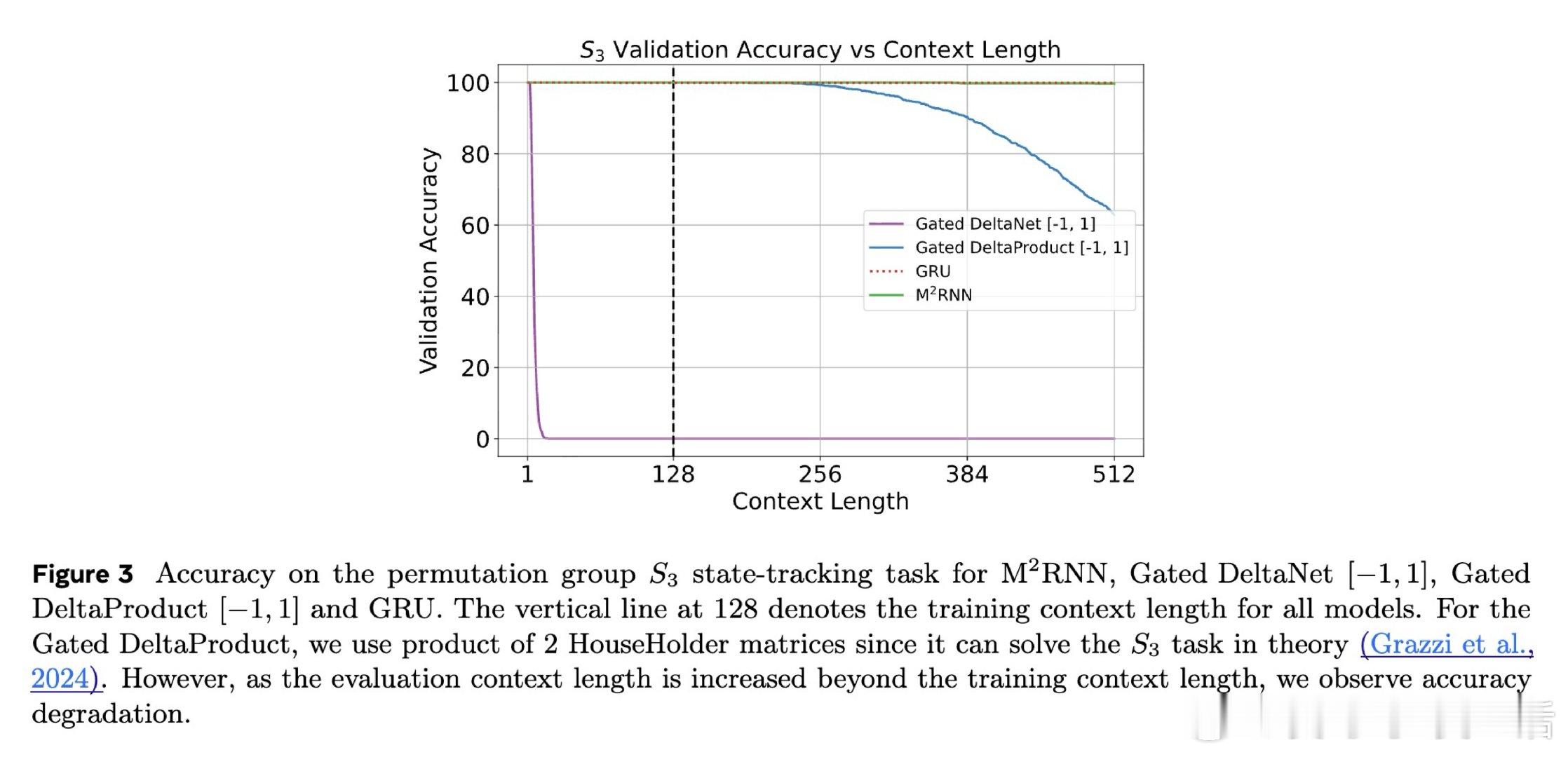
线性RNN在状态追踪任务上被理论证明无法突破TC0复杂度上限,无法处理程序执行、实体追踪等需要更强表达力的任务。非线性RNN虽具备这种能力,但其向量值隐状态容量极小(约1,360维),导致语言建模和长文本检索性能大幅落后,且逐步矩阵乘法无法利用GPU张量核心。
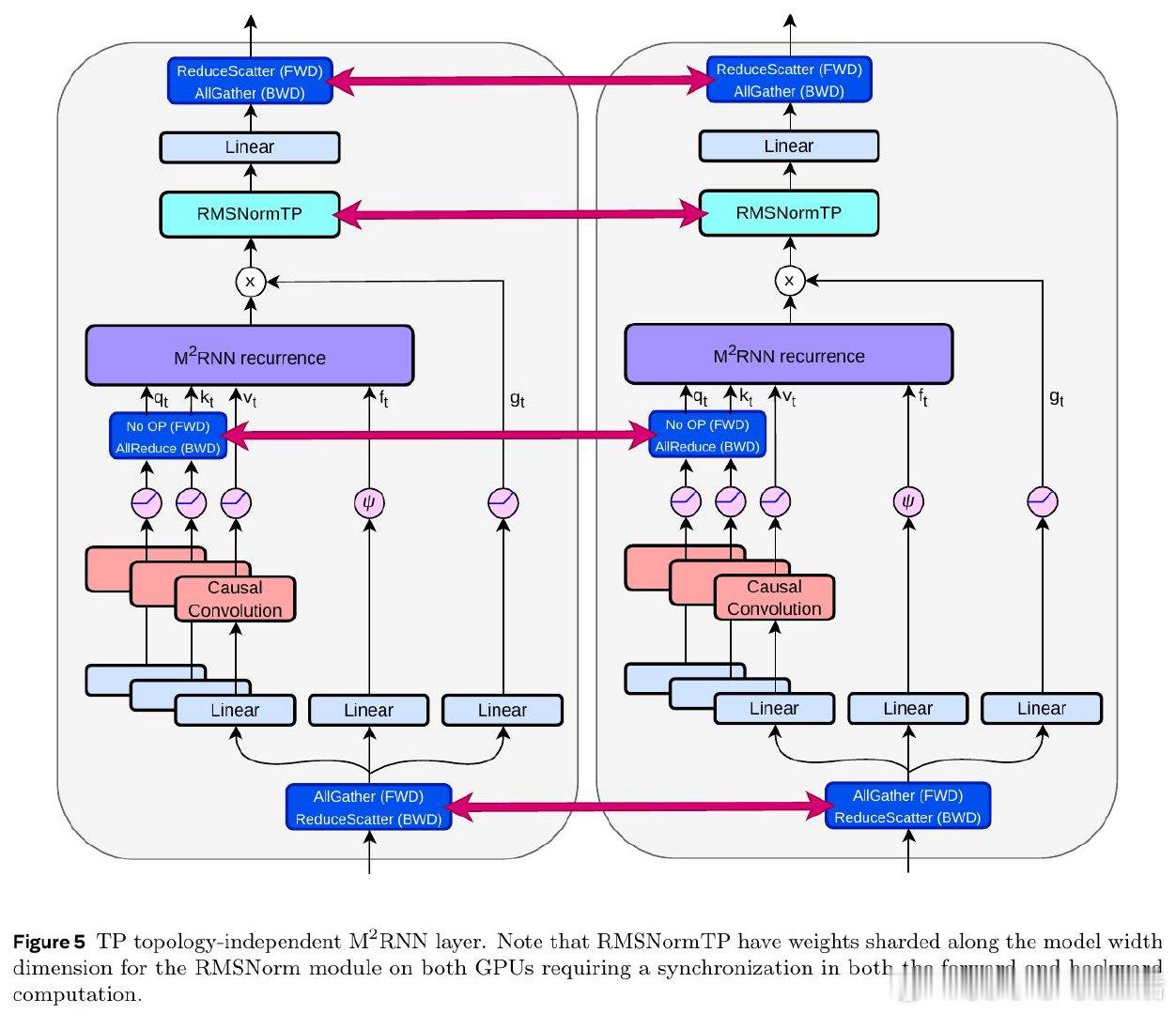
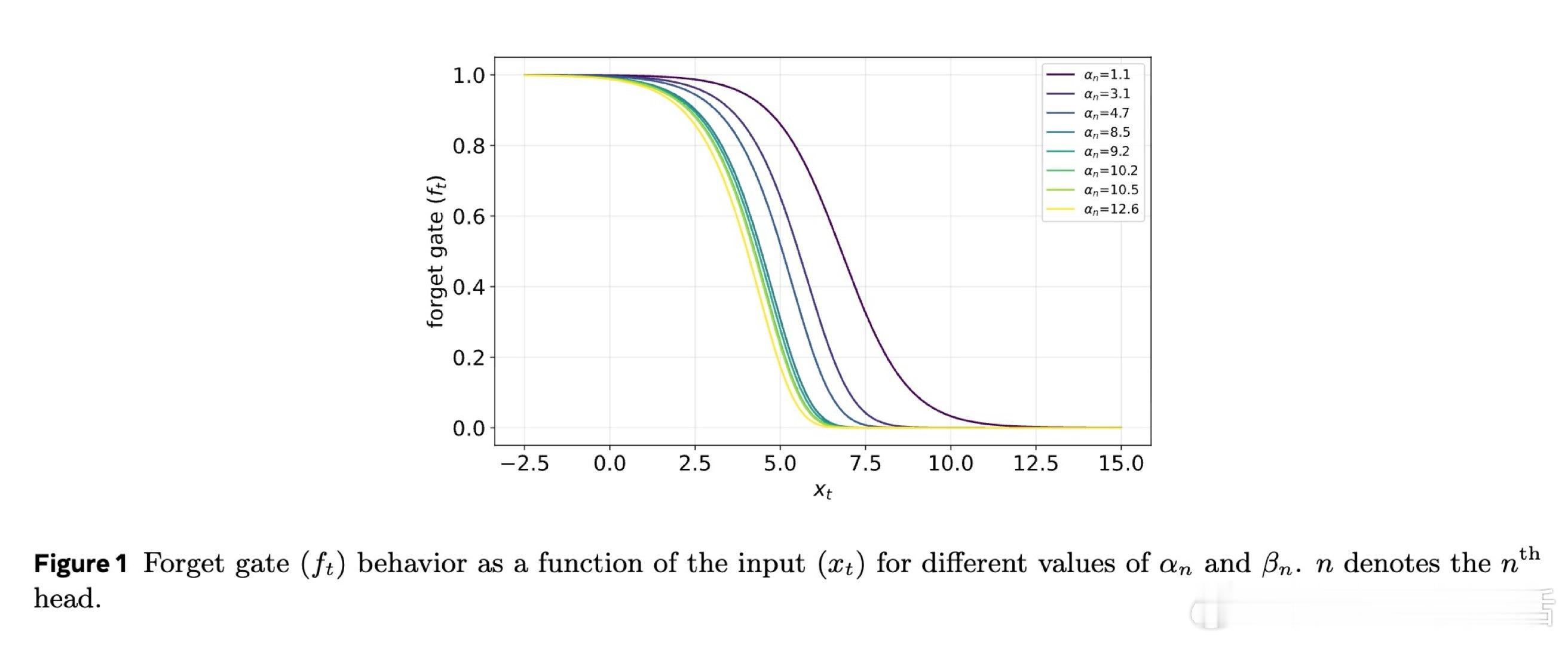
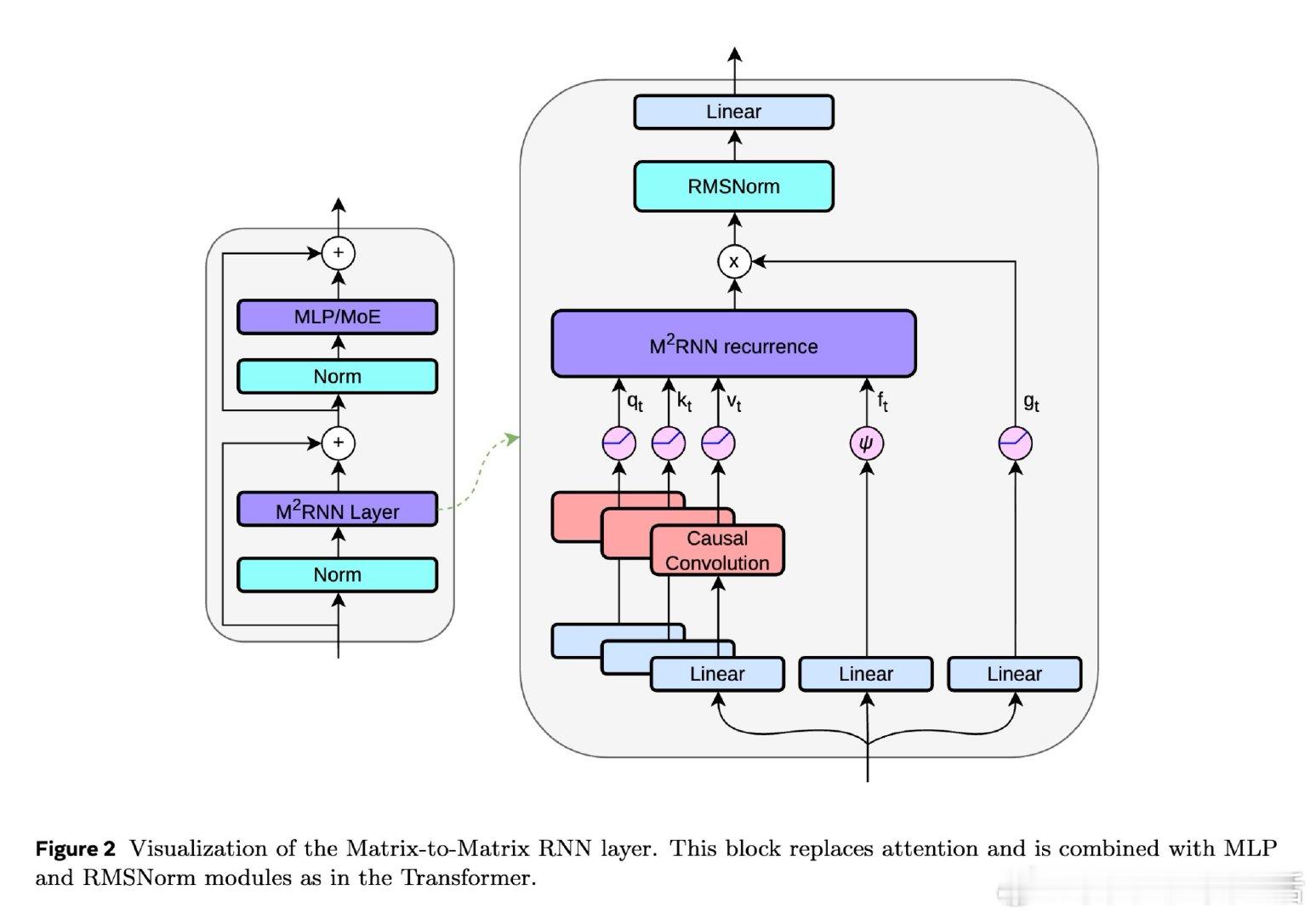
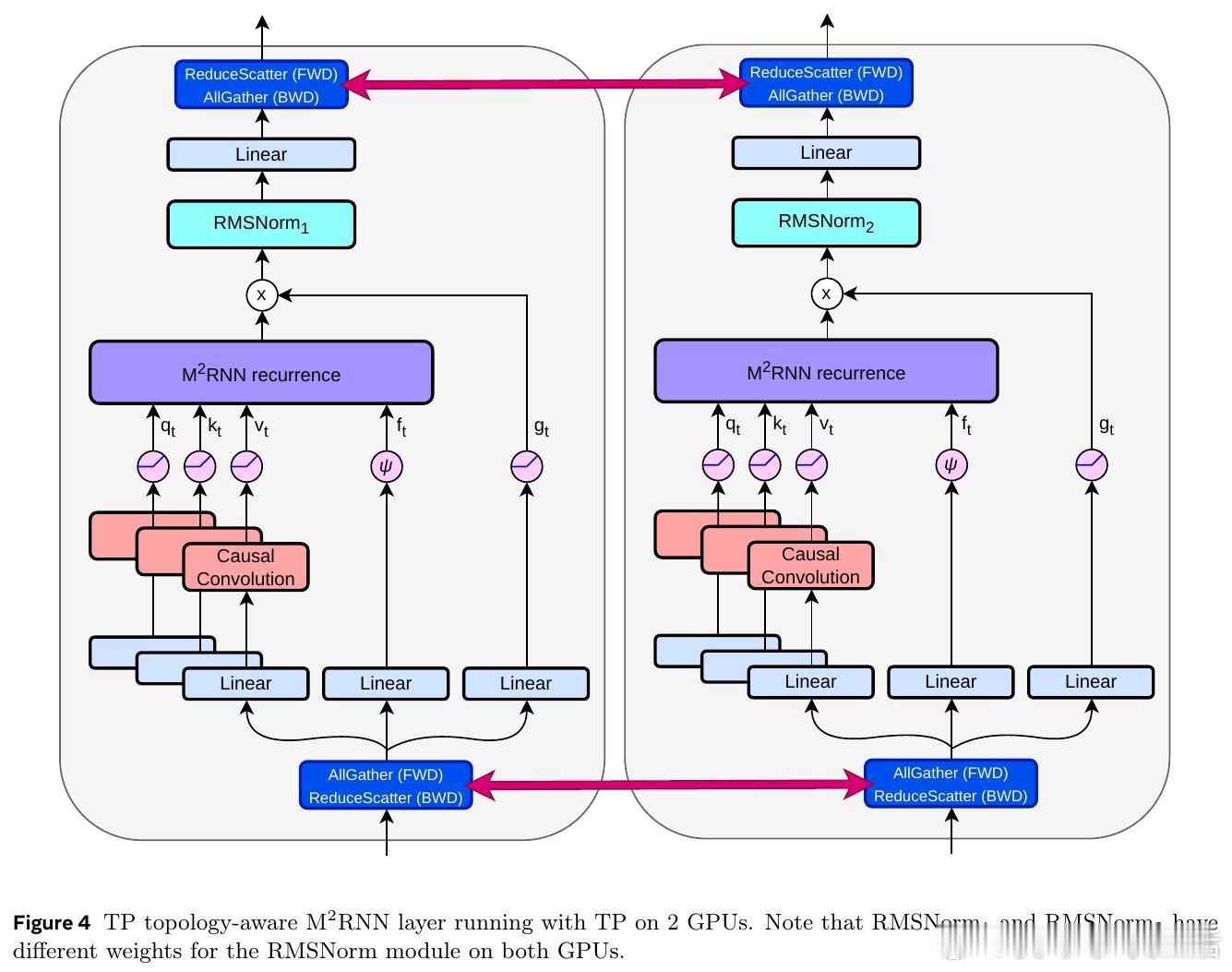
本文的核心洞见是:把非线性RNN的向量值隐状态重新看作矩阵值状态。通过外积展开将状态从向量升级为矩阵(约86,000维),并设计独立于隐状态的遗忘门,使得门控计算可并行执行,同时矩阵维度不依赖批次大小,从而消除FlashRNN因padding浪费的75%算力。
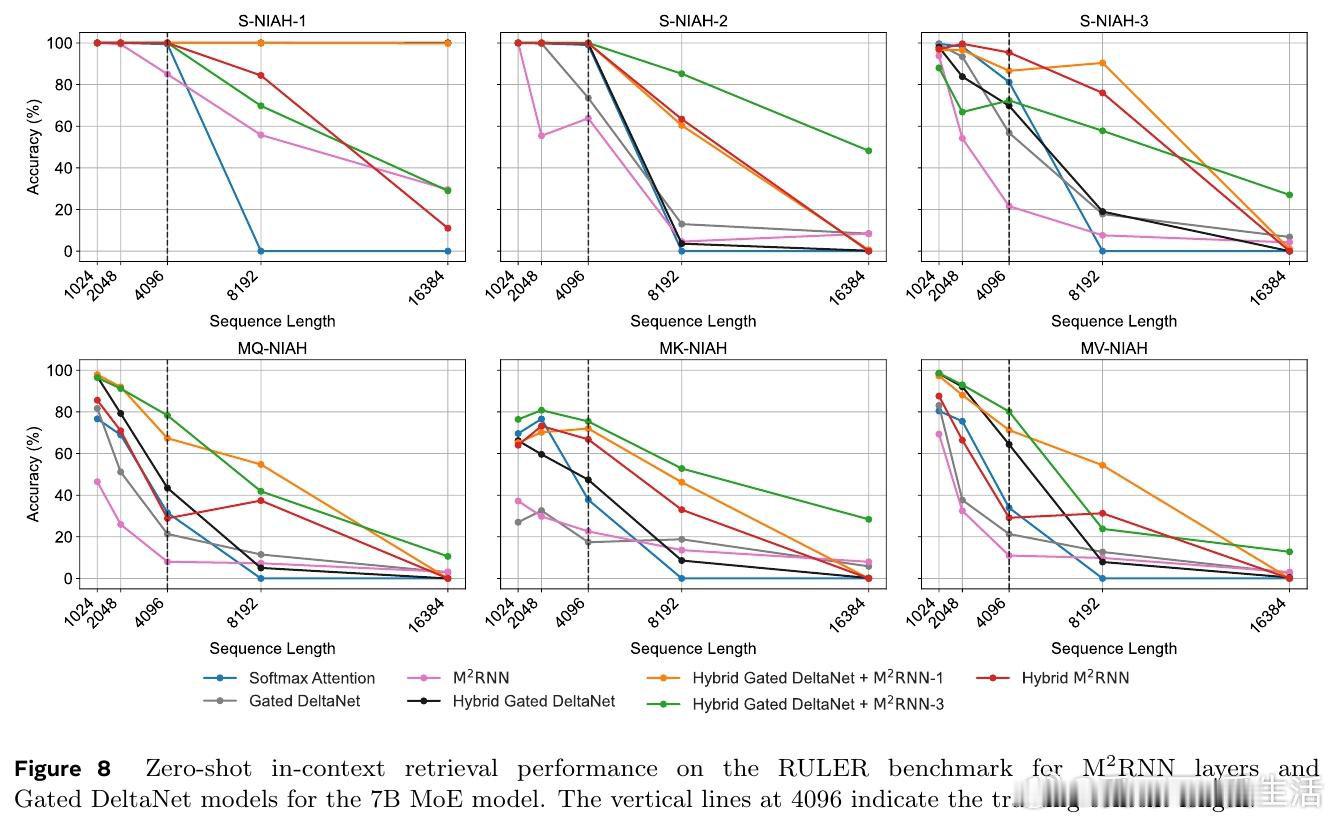
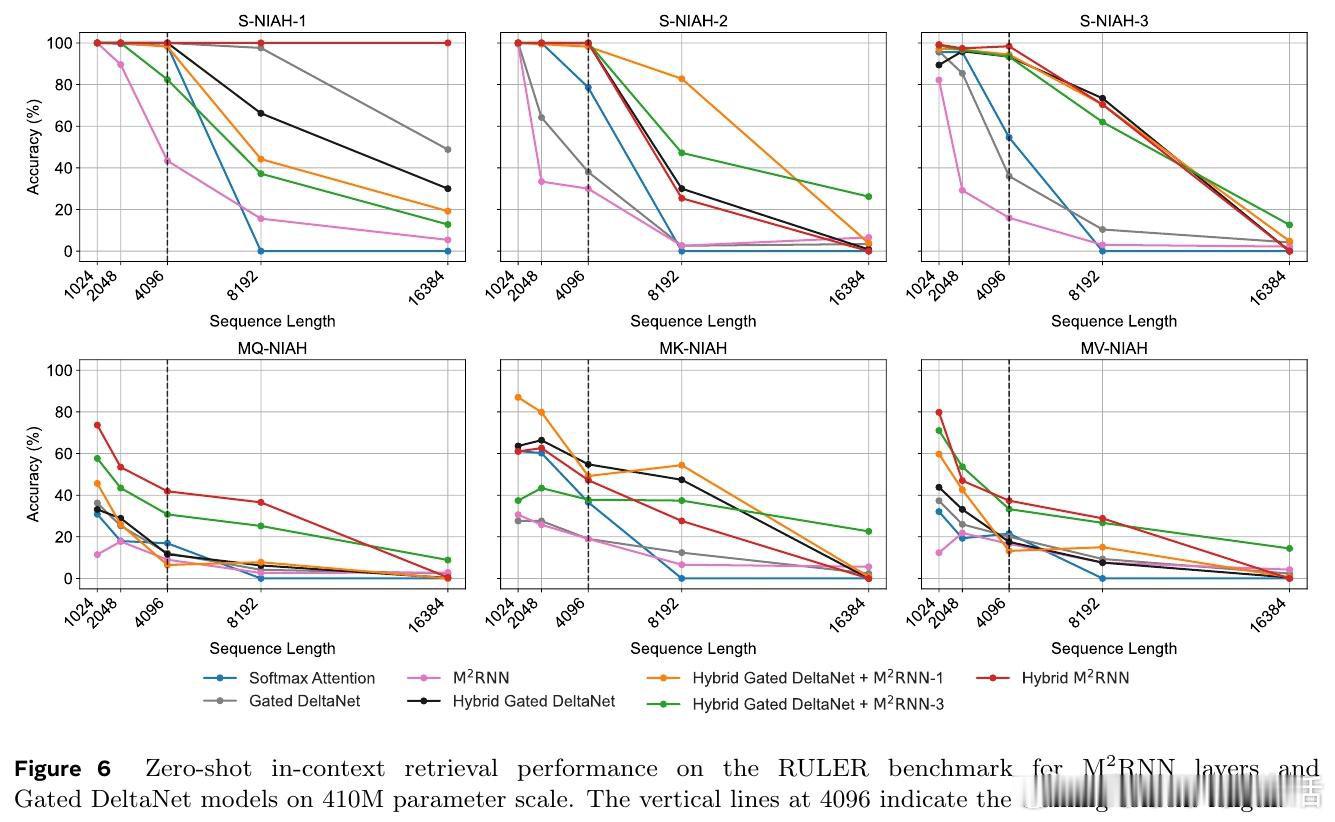
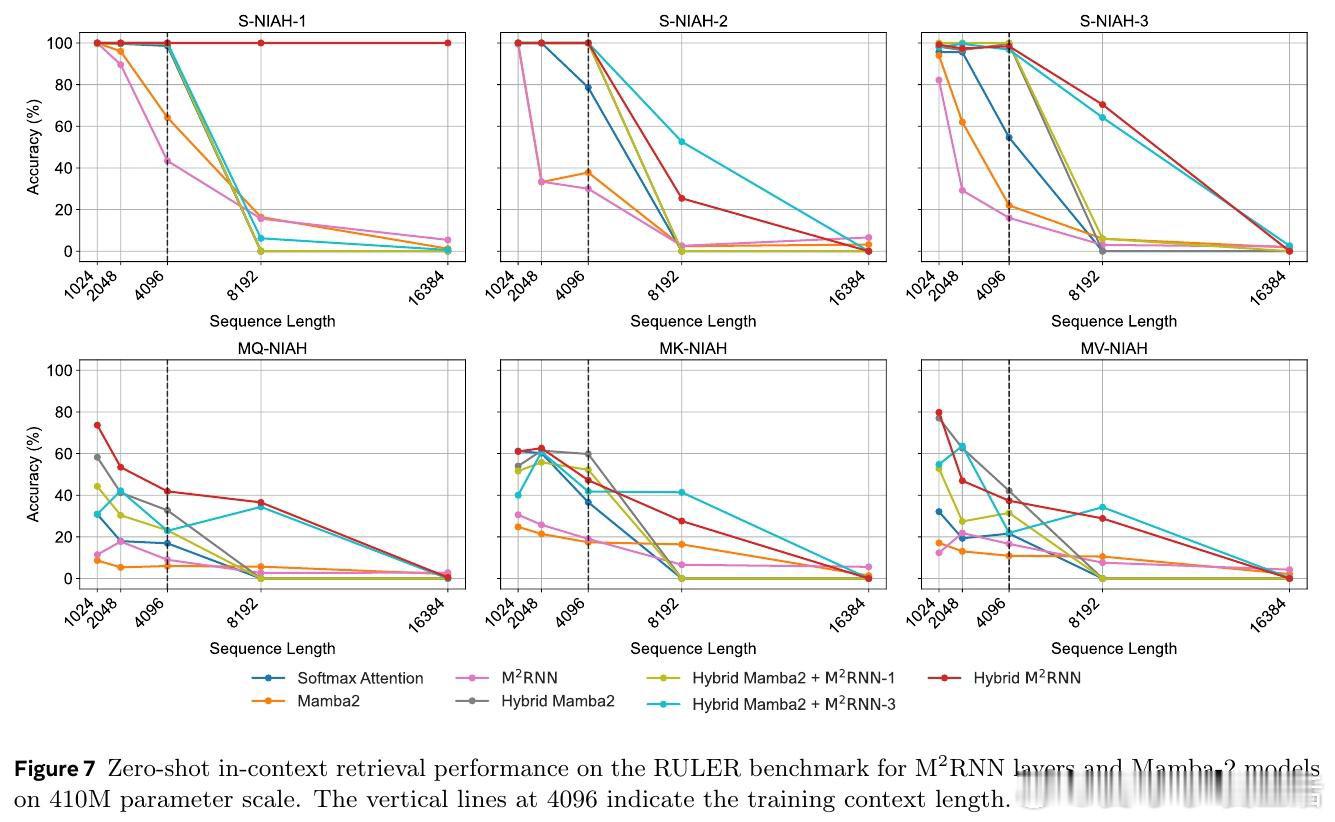
这项工作真正留下的遗产是:非线性递推与线性RNN并非对立选择,单层M²RNN嵌入混合架构即可带来8点长文本性能提升,仅损耗6%训练吞吐量。它为后来者打开的新门是"表达力与效率可在层级粒度上分配"的混合架构设计范式;但尚未跨过的门槛是非线性递推的序列并行壁垒,以及在更大规模和更长训练窗口下的验证。
arxiv.org/abs/2603.14360
机器学习 人工智能 论文 AI创造营