[LG]《Understanding Reasoning in LLMs through Strategic Information Allocation under Uncertainty》J Kim, X Luo, M Kim, S Lee… [Microsoft Research] (2026)
在最小包容球问题中,LLM 的逐步推理一旦锁定错误方向(如把"最大化"误作"最小化"),后续的步骤计算再精确也无法自救,推理在局部自洽、整体错误的轨道上僵死。
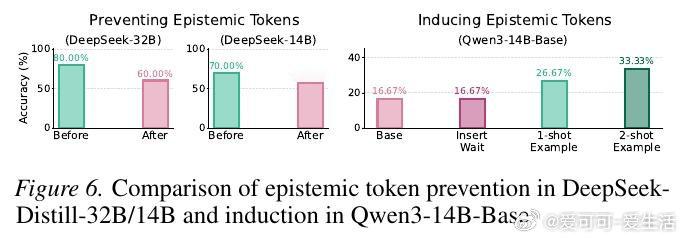
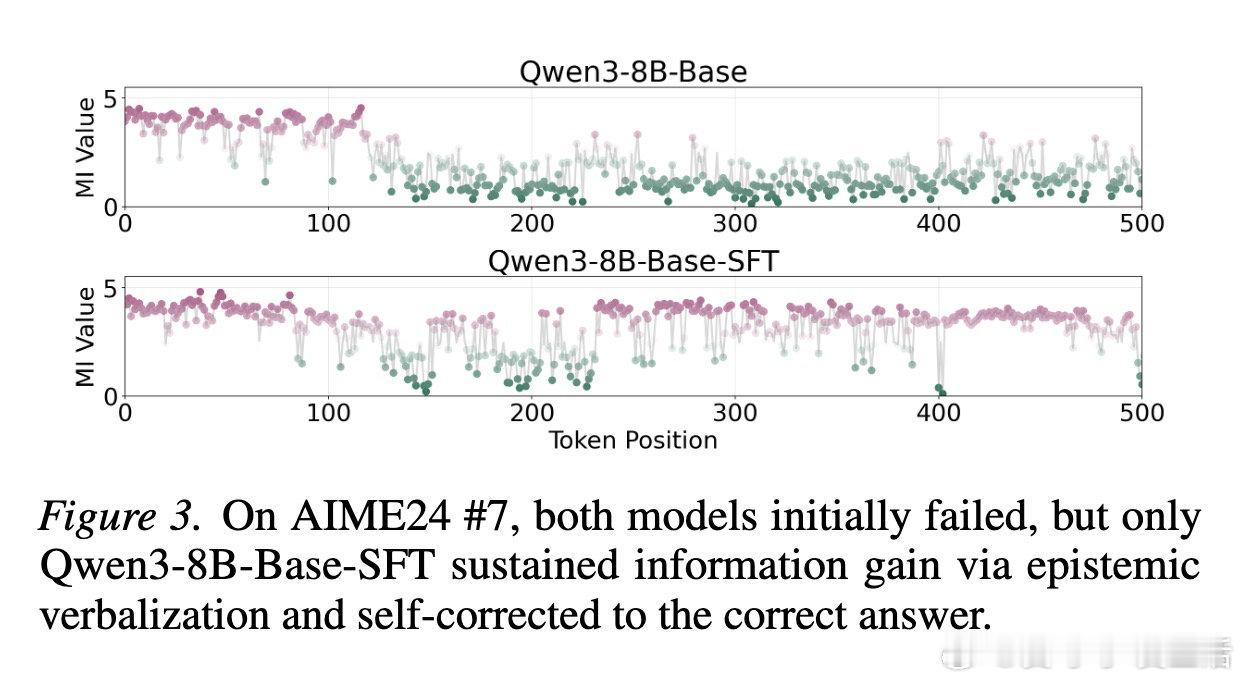
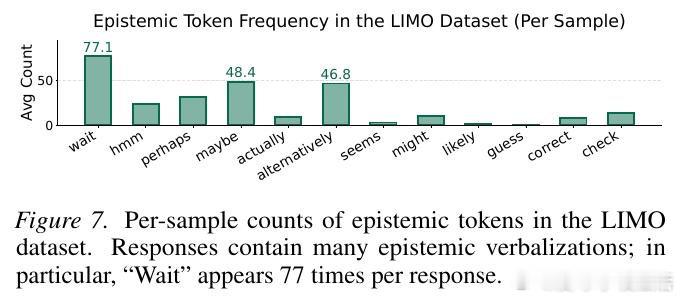
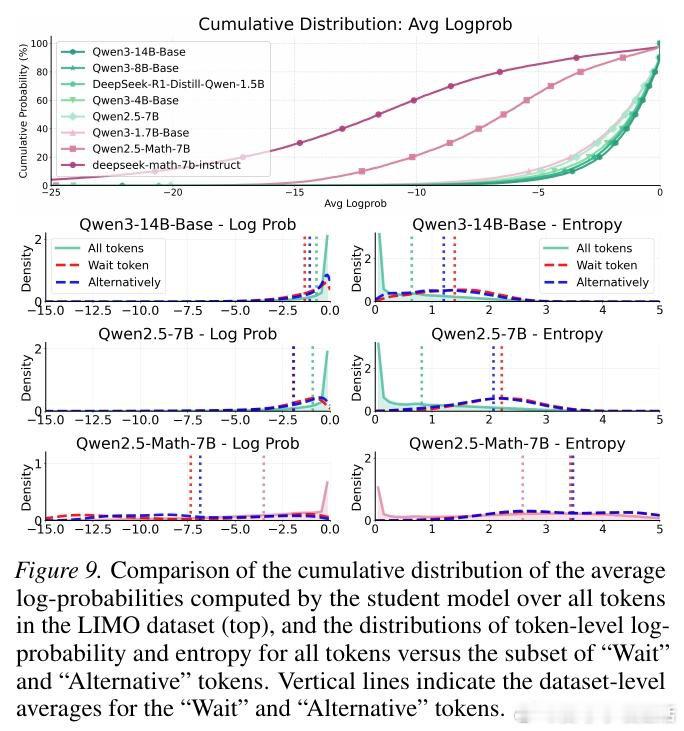
本文的核心洞见是:把 Chain-of-Thought 中的"Wait""Hmm"等表达重新看作不确定性外化(epistemic verbalization)的载体,而非触发自我修正的魔法词。由此,将推理状态分解为程序性信息与认识性外化两个正交维度,使模型能在程序推理信息停滞时,仍通过语言化自我质疑持续获取信息增益,最终突破局部错误轨迹。
这项工作真正留下的遗产是:为"Aha moment"提供了信息论意义上的因果机制,将零散的实验现象(蒸馏失败、小模型更爱反思、高熵token的作用)统一进同一框架。它为后来者打开的新门是:针对程序能力与不确定性外化能力分别设计训练目标,实现更精准的后训练策略。但尚未跨过的门槛是:如何在保留有效不确定性信号的同时,量化裁剪冗余推理链,避免以过度自我质疑换取低效的超长响应。
arxiv.org/abs/2603.15500
机器学习 人工智能 论文 AI创造营