这两天看不少车企都发布了自身的VLA模型,总的来说都是云里雾里。想子的MindVLA-o1,透露的信息最多,应该算是比较清晰的。以下是我个人理解
1、最核心的点,MindVLA 是统一原生多模态的VLA模型。具备「多模态」3D Vit,支持包括语言信息、摄像头,点云等多模态信息。
这里激光雷达主要当成复检工具,利用激光雷达点云引导模型理解真实空间结构,使3D Vit同时具备语义理解与三维感知能力。
李想把这类比“人类的大脑”,会理解3D空间、语义信息。但做到这点很吃算力和效率,所以必须软硬件结合,上M100自研芯片。
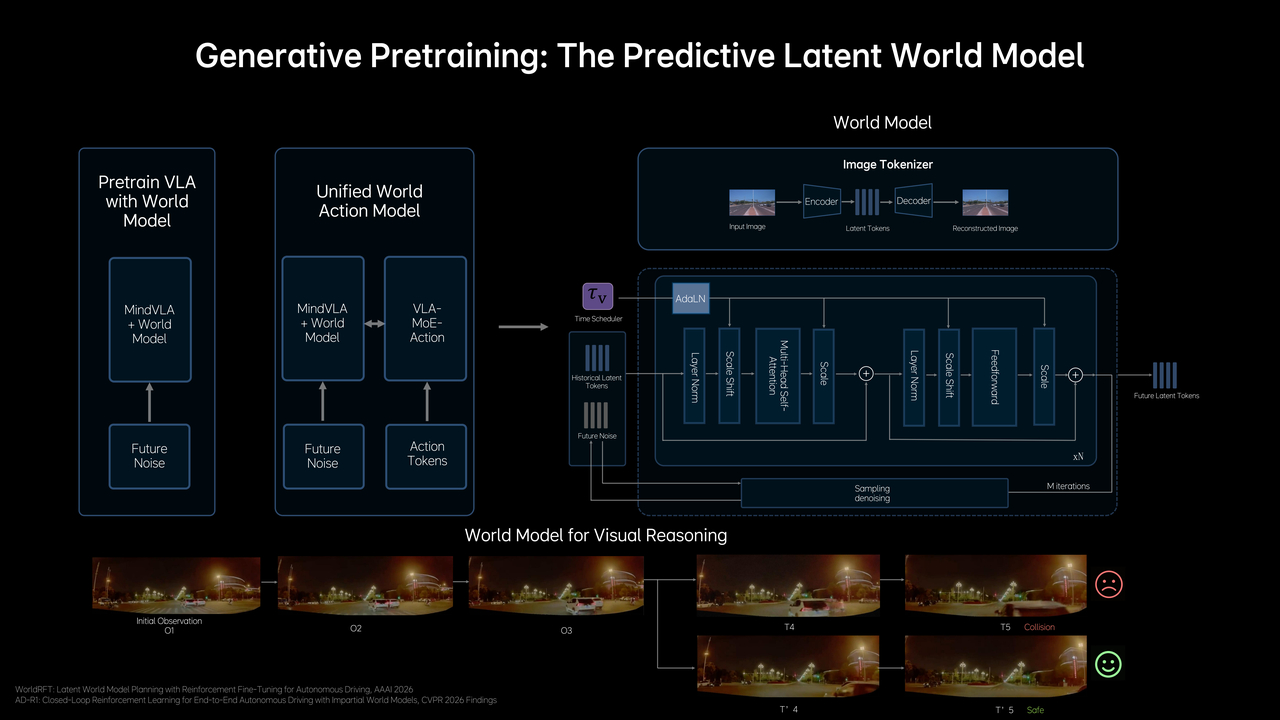
2、理想这套MindVLA-o1用了世界模型,来应付复杂的场景。
云端用大量视频训练,车端部署轻量化世界模型推演(个人理解),最后世界模型、多模态推理、驾驶行为进行联合训练,输出轨迹。
3、本质上这是一套具身智能模型。既可以控制车辆,也可以控制机器人,并用于训练不同形态的物理智能体。自动驾驶只是物理AI的起点。理想汽车李想称机器人也用VLA