今日推介(第2081期):路径约束混合专家模型、面向大语言模型推理时对齐的Token级自适应路由、同策略奖励建模与测试时聚合、扩散大语言模型策略优化中的轨迹缩减、大语言模型如何“扭曲”我们的书面语言 公·众·号:爱可可爱生活 网页链接 机器学习人工智能论文
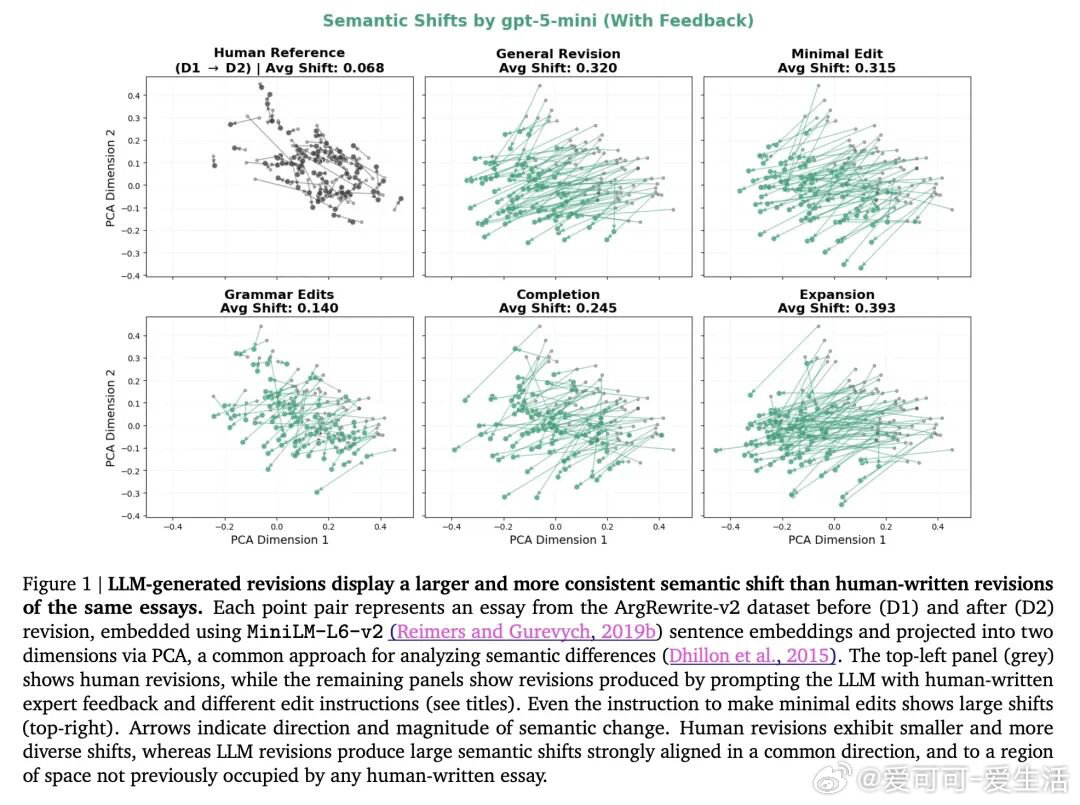
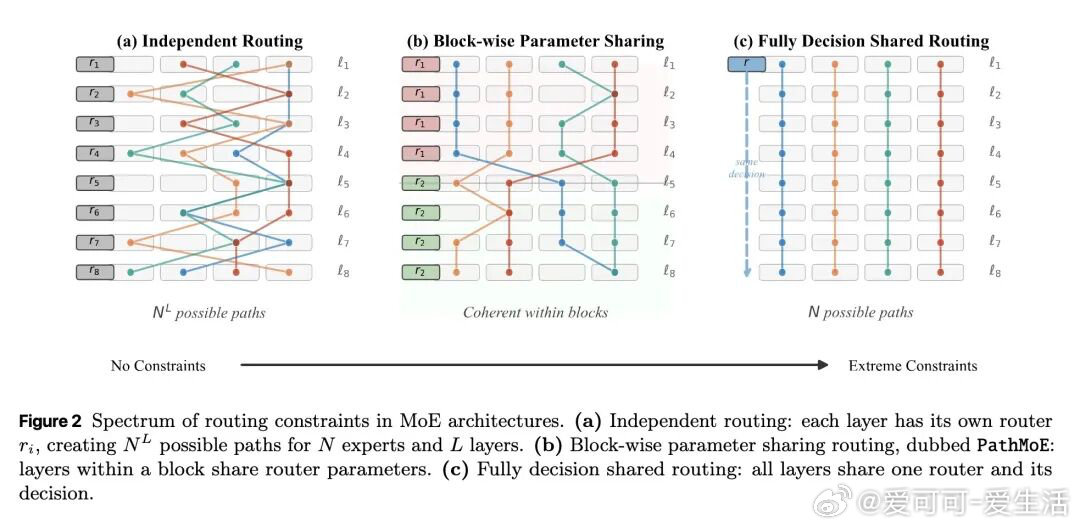
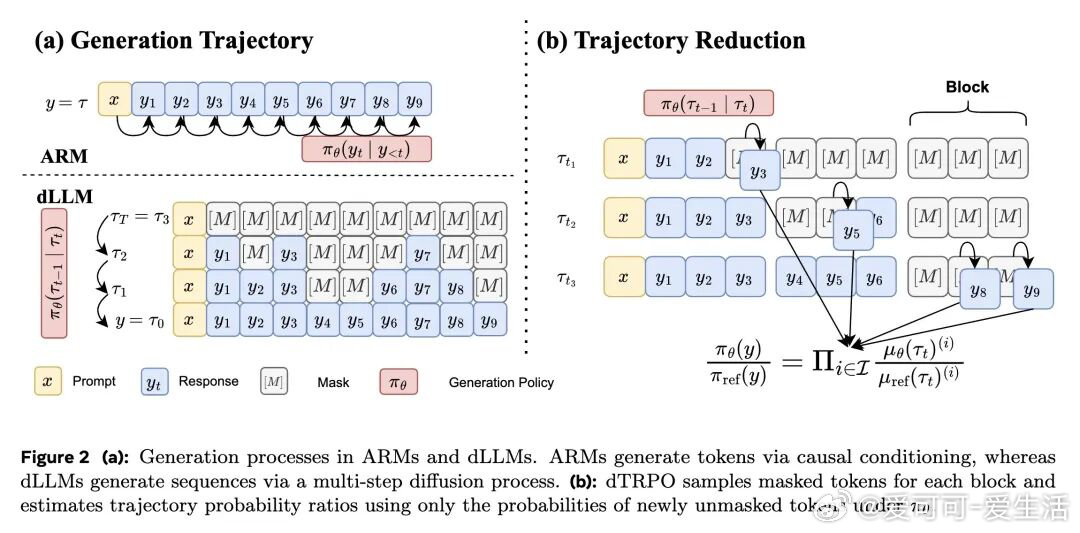

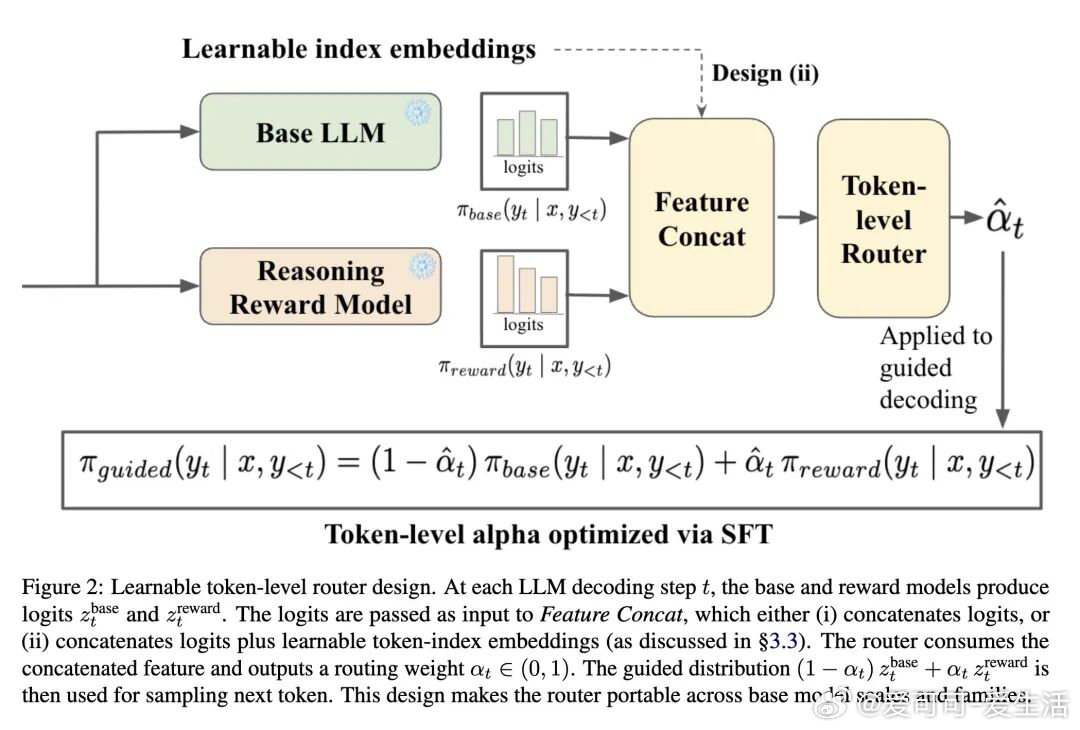
今日推介(第2081期):路径约束混合专家模型、面向大语言模型推理时对齐的Token级自适应路由、同策略奖励建模与测试时聚合、扩散大语言模型策略优化中的轨迹缩减、大语言模型如何“扭曲”我们的书面语言 公·众·号:爱可可爱生活 网页链接 机器学习人工智能论文