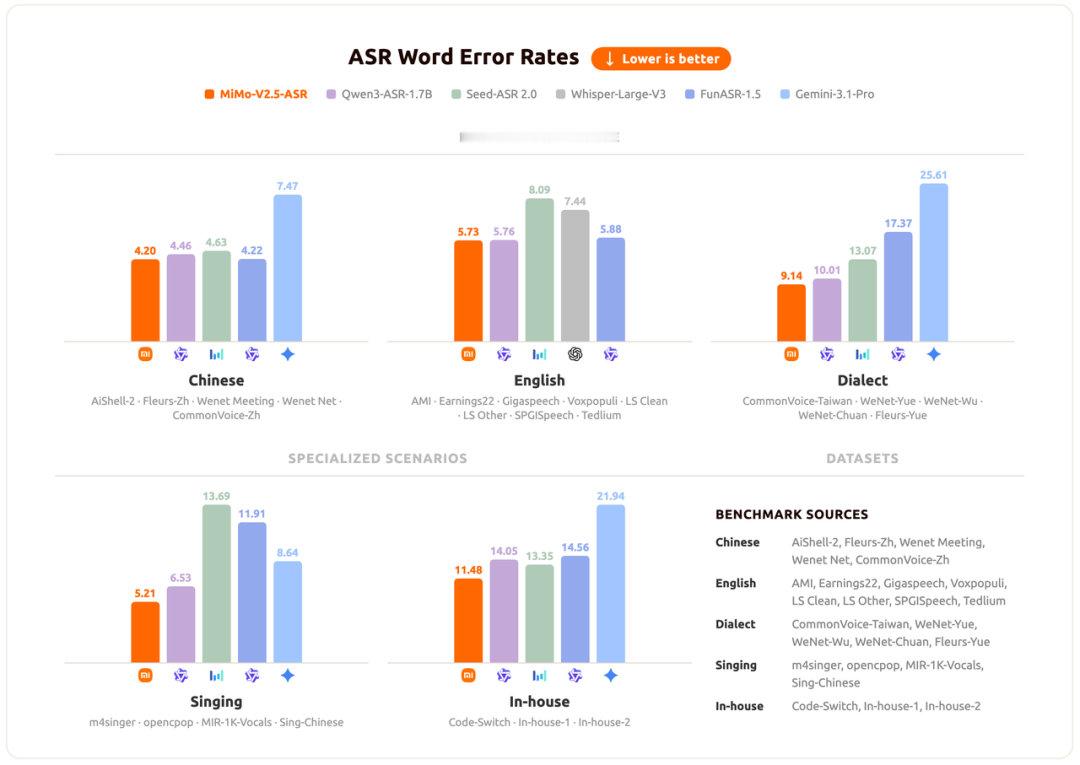
小米今日正式发布 MiMo‑V2.5‑TTS 系列与 MiMo‑V2.5‑ASR 全链路语音大模型,面向 Agent 时代打造语音输入输出完整方案,可通过自然语言直接调度声音表现,也将为智能座舱等人车家全生态场景提供更流畅的语音交互支撑。MiMo‑V2.5‑TTS 系列包含三款模型,已上线小米 MiMo 开放平台并限时免费。基础款内置多款精品音色,支持语速、情绪、语气精细化控制;VoiceDesign 版本可一句话快速生成全新音色;VoiceClone 版本用少量音频样本就能高保真复刻目标音色,同时保留风格指令与音频标签控制能力。三款模型共享统一能力,支持导演剧本级结构化输入、行内音频标签调控,即便纯文本也能自动捕捉情感韵律与说话人特征。MiMo‑V2.5‑ASR 同步开源模型权重与代码,在中英双语、中文方言、中英混语、强噪音、多说话人、歌曲识别、知识密集内容等复杂真实场景下识别性能达到业界领先,可原生输出标点,转写结果直接可用,为车载、会议等场景提供稳定可靠的语音转写能力。