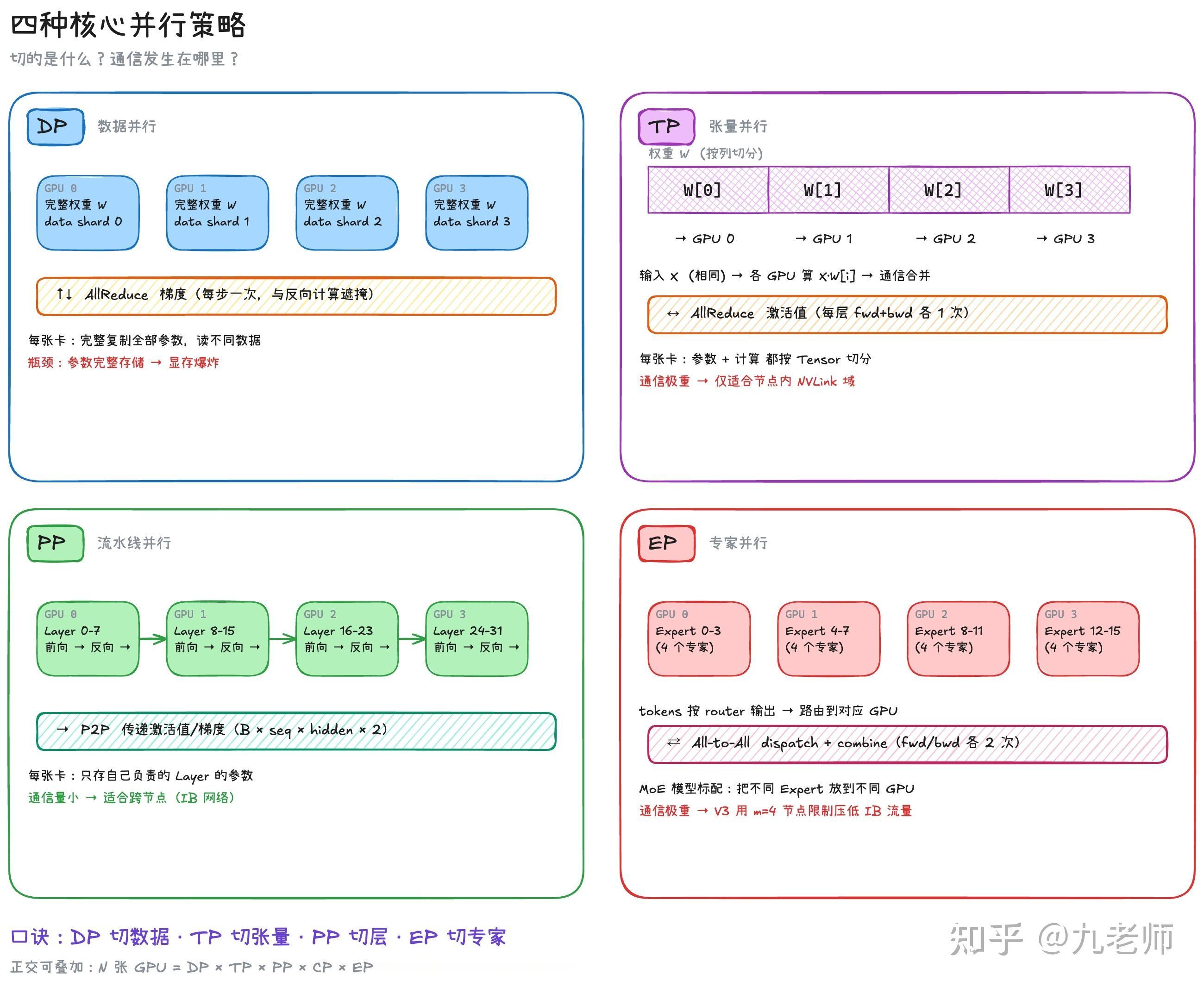
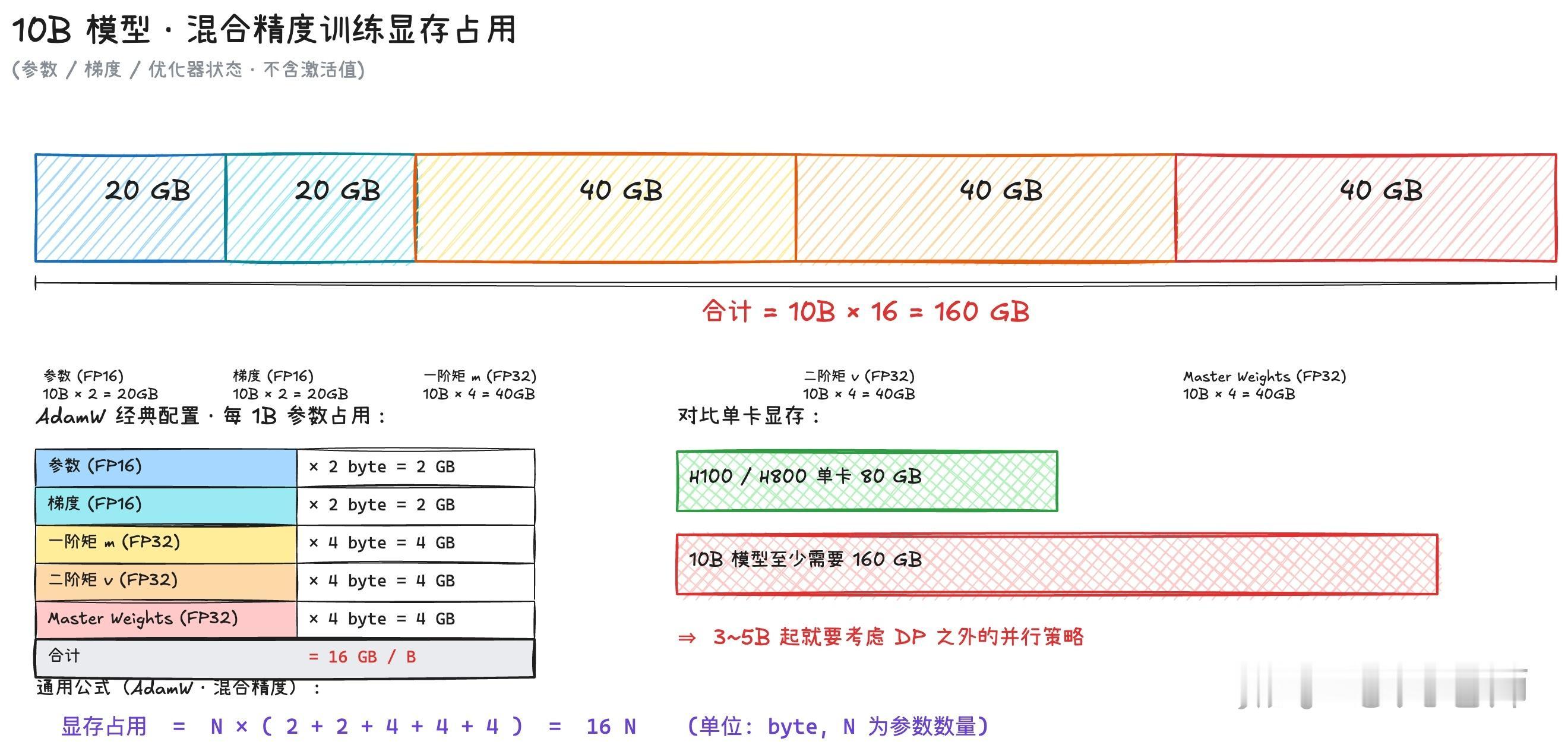
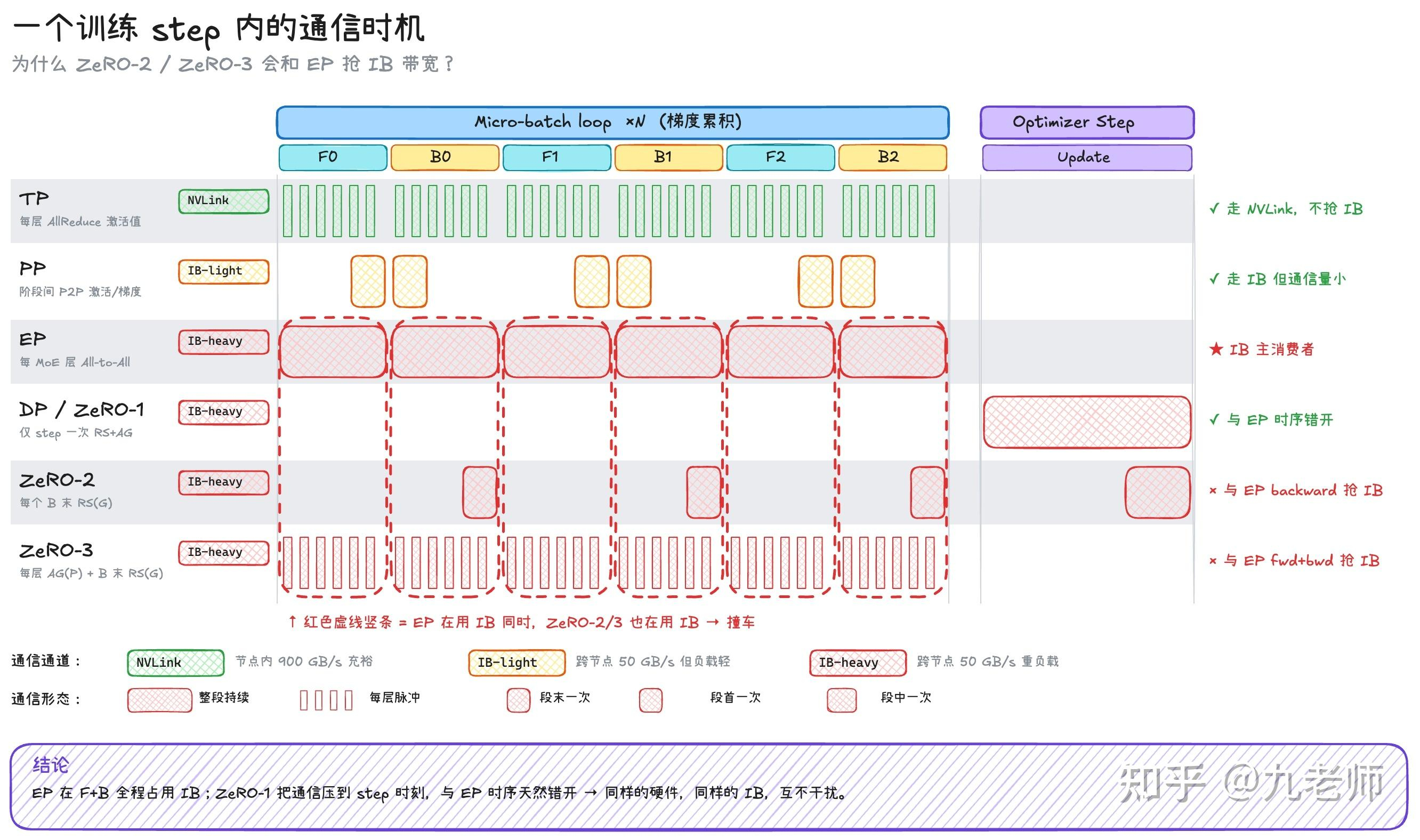
DeepSeek-V4的并行策略和计算通信遮掩网页链接“最近模型从 Dense 切到了 MoE,MFU 也相应地暴跌了,大家直觉上觉得 Expert 被切的很小,所以计算强度上不去,但实际切分完的维度至少也有 1024,MFU 暴跌的原因一定不来自这里。深入理解这个问题,就是理解 GPU 的分布式并行计算,要在计算和访存 bound 之外,引入通信 bound,而解决吞吐和 MFU 的问题的手段,就是设计合理的 GPU并行策略,做好 GPU 计算和通信的遮掩(overlap)。
DeepSeek 的 H800 和昇腾卡,8 卡 nvlink 高速互联,跨节点都是 IB(InfiniBand)低速网络,我们手里虽然有 B200,但实际也没用上 NVL72,所以DeepSeek 的并行策略有普适的借鉴意义——硬件基础相似,低成本方案,新的 MoE 的方案也做了开源。”AI创造营