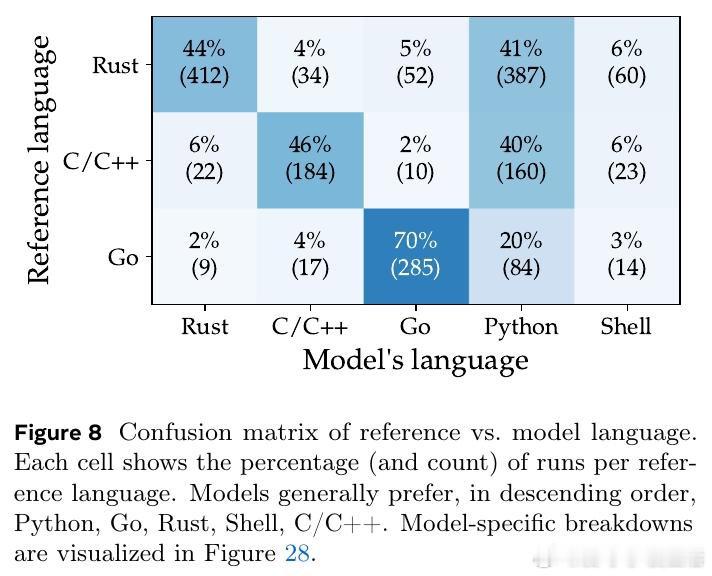
[AI]《ProgramBench: Can Language Models Rebuild Programs From Scratch?》J Yang, K Lieret, J Ma, P Thakkar… [Meta FAIR] (2026)
在软件工程评测中,衡量“从零造项目”是一个悬而未决的难题。过去基准受困于补函数、修单点 bug,本质原因是它们预设了结构,绕开了架构选择。
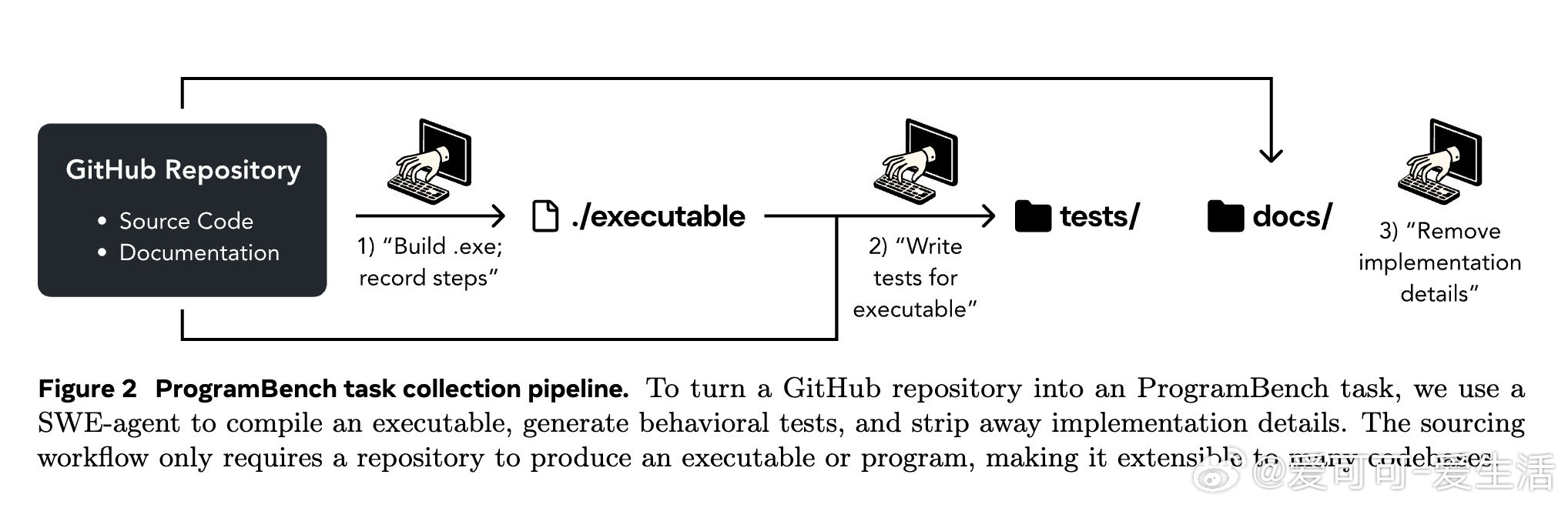
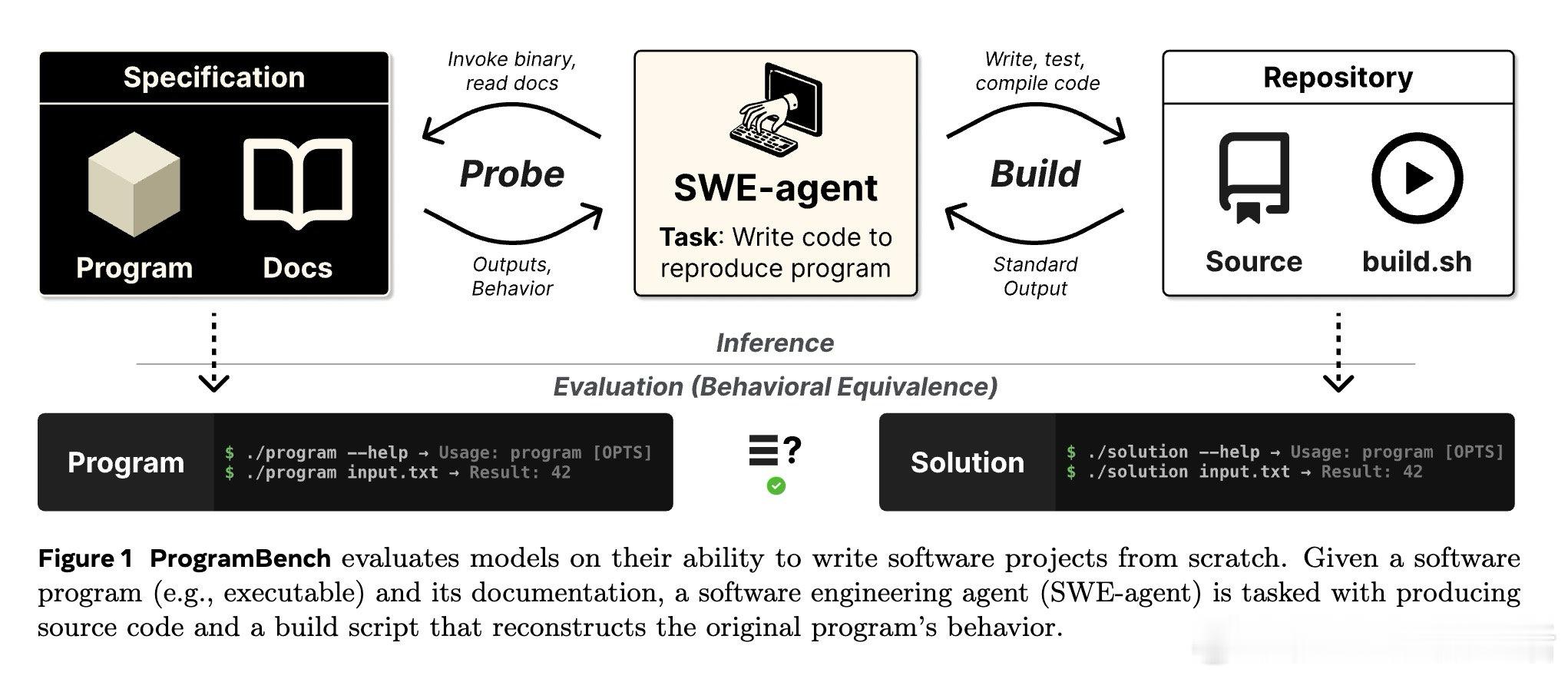
本文的核心洞见是:把可执行程序重新看作行为规格书。由此,让模型只凭程序与文档重建代码库,并用黑盒行为测试验收,使设计能力暴露出来。
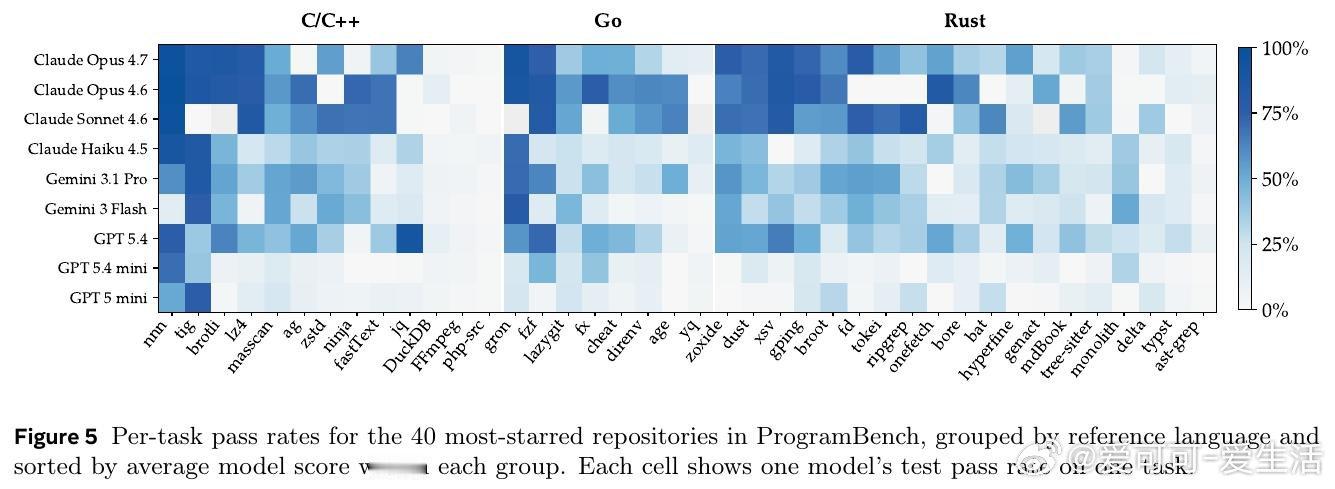
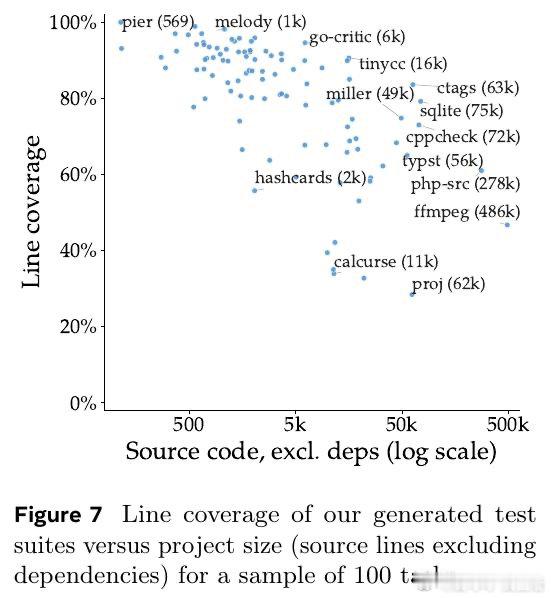
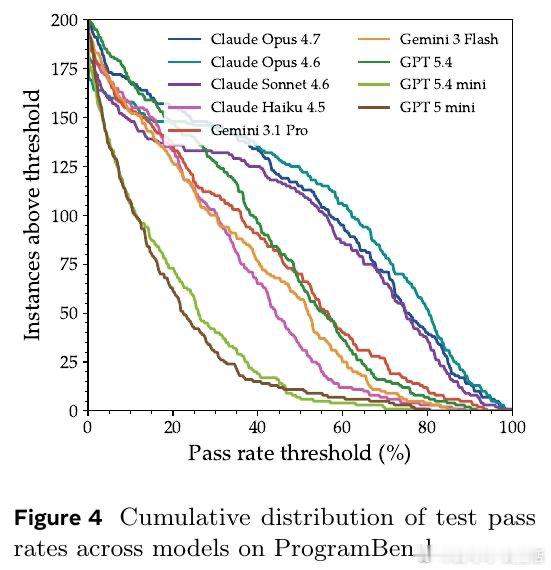
这项工作真正留下的遗产是把代码智能评测从“会写片段”推向“会建系统”。它打开的新门是端到端软件代理评测,但尚未跨过的门槛是有限测试难覆盖性能、资源与未测行为。
arxiv.org/abs/2605.03546 机器学习 人工智能 论文 AI创造营