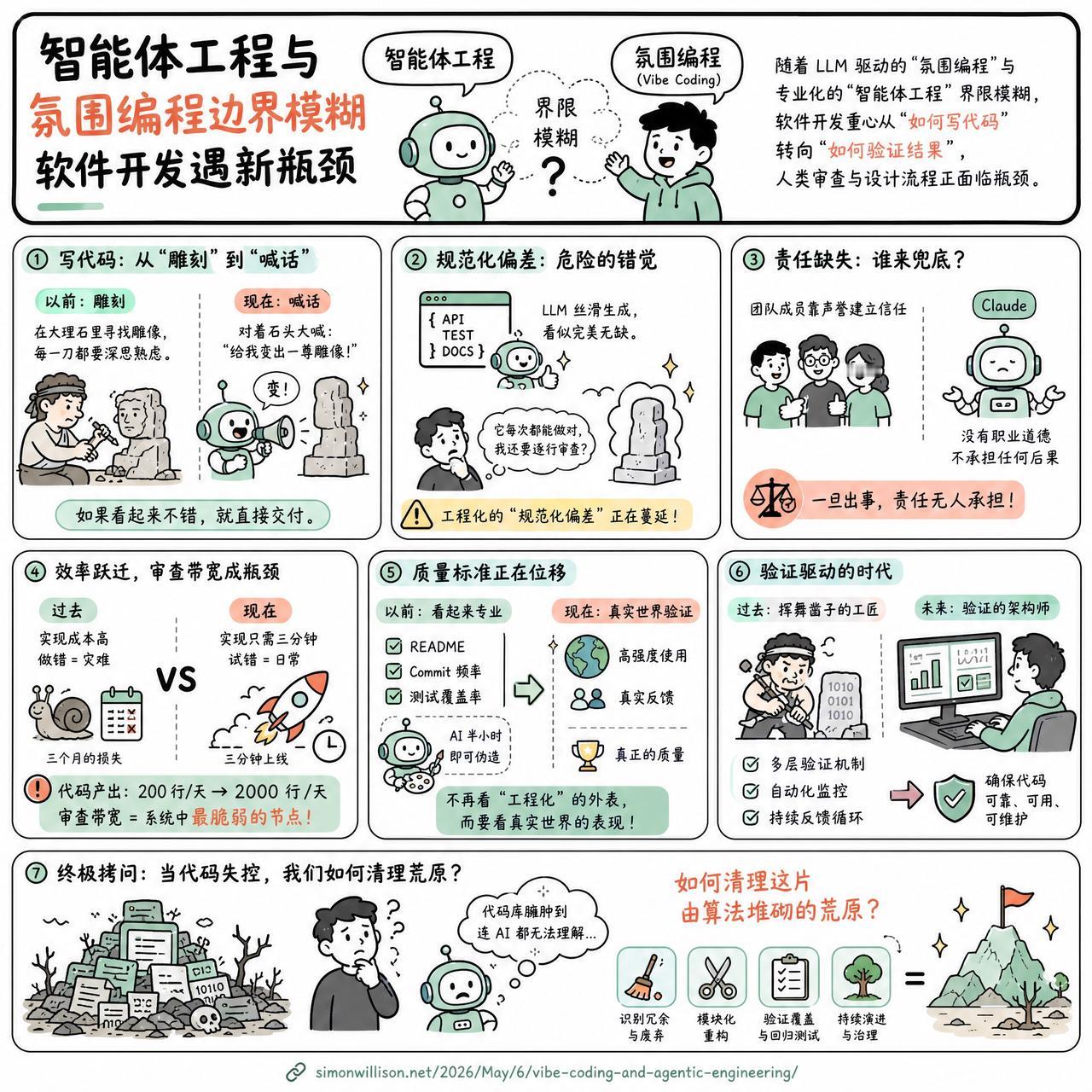
【智能体工程与氛围编程边界模糊,软件开发遇新瓶颈】
快速阅读:随着 LLM 驱动的“氛围编程”(Vibe Coding)与专业化的“智能体工程”(Agentic Engineering)界限日益模糊,软件开发的重心正从“如何写代码”转向“如何验证结果”。当代码产出效率提升十倍时,人类的审查能力与设计流程正面临前所未有的瓶颈。
写代码这件事,正在从一种“雕刻”艺术变成一种“喊话”行为。
以前我们写代码,像是在大理石里寻找雕像,每一刀下去都要考虑应力、纹理和结构。现在的 Vibe Coding 像是对着石头大喊一声:“给我变出一尊雕像!”如果出来的东西看起来不错,我们就直接交付。
这种转变让一种危险的倾向正在蔓延:工程化的“规范化偏差”。当 LLM 能够极其丝滑地生成看似完美的 API 接口、测试用例和文档时,开发者很容易产生一种错觉——既然它每次都能做对,那我为什么还要逐行审查?
有观点认为,这本质上是责任制的缺失。团队成员可以靠声誉建立信任,但 Claude 没有职业道德,它不承担任何生产事故的后果。
这种效率的跃迁正在撑破整个软件开发生命周期(SDLC)。过去,设计流程之所以严谨,是因为实现成本极高,做错三个月是灾难;现在,如果实现只需三分钟,设计过程是否也会变得轻率?当代码产出从每天 200 行飙升到 2000 行时,人类的审查带宽成了系统中最脆弱的节点。
更有意思的是,代码质量的衡量标准正在发生位移。以前看 README、看 Commit 频率、看测试覆盖率,现在这些“看起来很专业”的指标可以被 AI 在半小时内伪造得天衣无缝。真正能证明一个项目质量的,不再是它看起来有多“工程化”,而是它是否在真实世界中被高强度地“使用”过。
我们正在进入一个“验证驱动”的时代。未来的工程师,可能不再是那个挥舞凿子的工匠,而是坐在监控器前,通过构建多层、交织的自动化验证机制,去确保那台疯狂运转的“代码打印机”没有在制造一堆无法维护的数字垃圾。
如果有一天,代码库变得臃肿到连 AI 都无法理解,我们该如何清理这片由算法堆砌的荒原?
simonwillison.net/2026/May/6/vibe-coding-and-agentic-engineering/