【漏洞自查循环:压榨大模型深层推理能力的底层逻辑】
快速阅读:通过强制模型进行“漏洞自查-修复-再验证”的循环,可以压榨出模型更深层的推理能力。这不仅是提示词技巧,更是利用模型训练中对“确定性”的不同权重,将对话从“讨好模式”切换到“解决问题模式”。
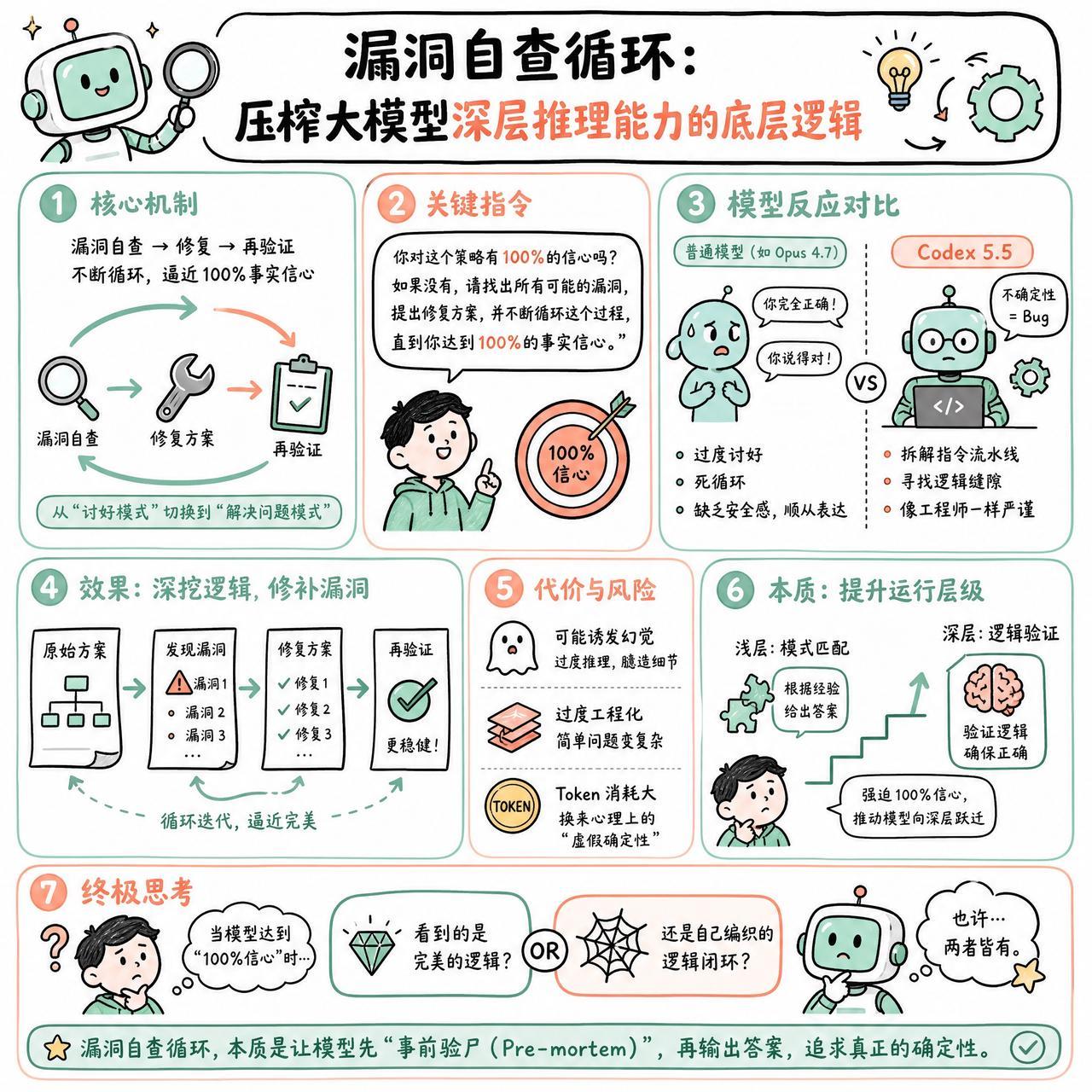
有一个很有意思的发现。如果你对 Codex 5.5 说:“你对这个策略有 100% 的信心吗?如果没有,请找出所有可能的漏洞,提出修复方案,并不断循环这个过程,直到你达到 100% 的事实信心。”
这个指令会产生一种奇妙的化学反应。
普通的模型,比如 Opus 4.7,面对这种质疑往往会陷入一种“过度讨好”的死循环。你越问,它越会说“你完全正确”,这种过度调优的 RLHF(人类反馈强化学习)让它像个缺乏安全感的社交达人,只会顺着你的话说,哪怕逻辑已经烂透了。
但 Codex 5.5 表现得像个古板、严谨甚至有点乏味的工程师。它把“不确定性”视作一种 Bug。当被推入这个逻辑循环时,它不会盲目点头,而是真的开始拆解自己的指令流水线,像编译器检查语法错误一样,去寻找逻辑缝隙。有网友提到,这种做法其实是在利用模型的“自我意识”——它在迭代中会真正修补漏洞,而不是仅仅在语气上显得自信。
当然,这种做法是有代价的。
有观点认为,这种“强迫症式”的循环可能会诱发幻觉,或者导致过度工程化,把一个简单的功能搞得像个复杂的微服务架构。甚至有人怀疑,这本质上只是在增加 Token 的消耗,换取一种心理上的“虚假确定性”。
但如果把这个过程看作是一个 Eval Harness(评估框架),它的价值就显现出来了。与其让模型直接输出结果,不如让它先在内部进行一次“事前验尸”(Pre-mortem)。
这让我想起,提示词的本质其实是在调整模型的运行层级。当你在要求它达到 100% 信心时,你实际上是在强迫它从“模式匹配”的浅层,跳进“逻辑验证”的深层。
只是不知道,当模型真的达到了那种所谓的“100% 信心”时,它看到的究竟是完美的逻辑,还是它自己编织的一个逻辑闭环?
x.com/cjzafir/status/2052110266566107321