【颠覆梯度下降!AI 靠自己写代码学会解决复杂任务】
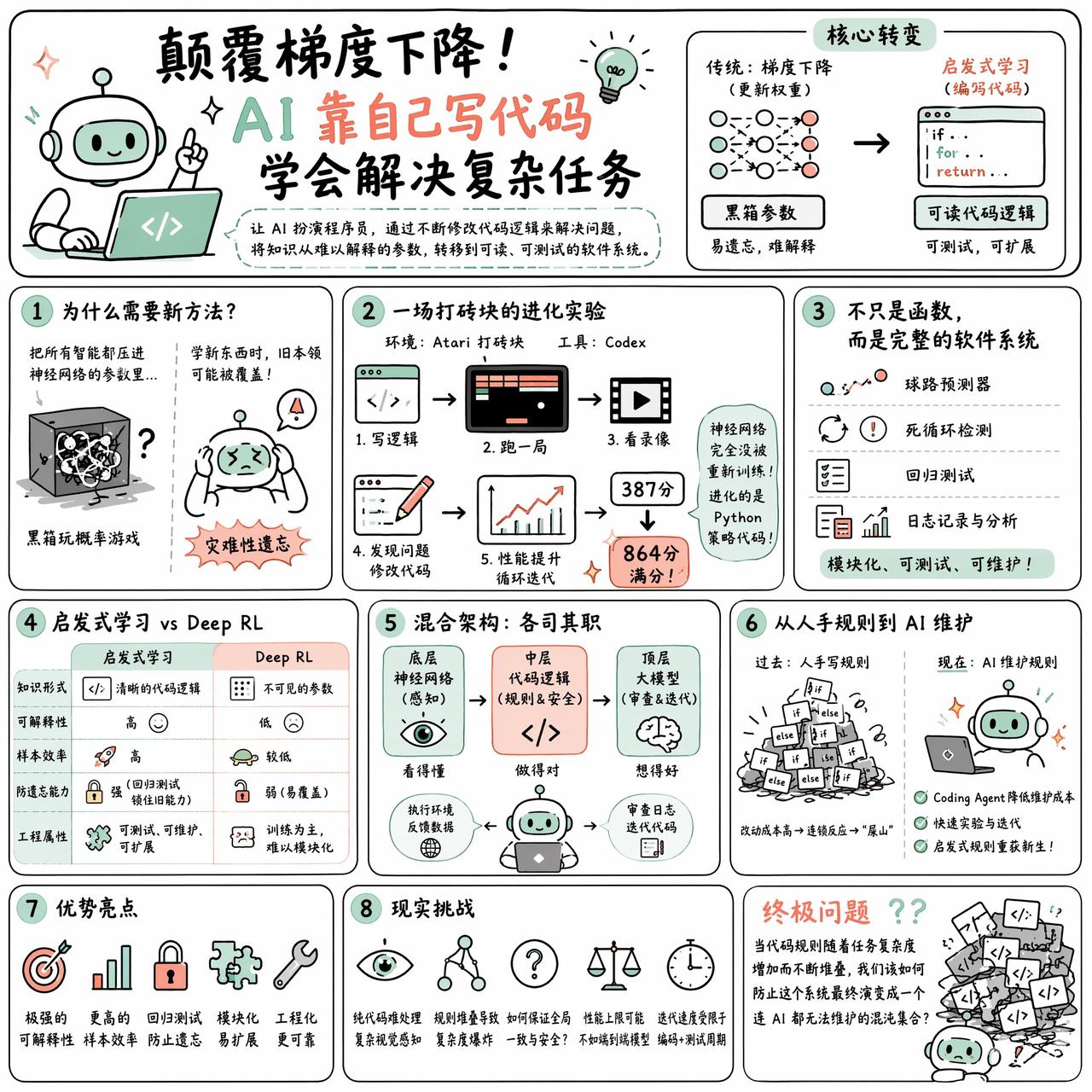
快速阅读:与其在神经网络的权重里通过梯度下降苦苦寻找规律,不如让 AI 扮演程序员,通过不断修改代码逻辑来解决问题。这种被称为“启发式学习”的方法,将知识从难以解释的参数转移到了可读、可测试的软件系统中,为解决“灾难性遗忘”提供了工程化的思路。
如果把所有的智能都压进神经网络的参数里,我们其实是在一个黑箱里玩一场概率游戏。一旦要学新东西,旧的本领就可能被覆盖掉,这就是所谓的“灾难性遗忘”。但如果把进步的重心从“更新权重”挪到“编写代码”上呢?
最近有个很有意思的实验:用 Codex 去玩 Atari 打砖块。这里有个前提,神经网络本身完全没有被重新训练。真正进化的不是模型,而是它写出来的那套 Python 策略。它先写逻辑,跑一局,看录像,发现球没打中,于是改代码,加个落点预测,再跑一局。就这样,策略从 387 分一路涨到了 864 分的满分。
这不再是一个简单的函数,而是一个完整的软件系统。它包含了球路预测器、死循环检测、甚至还有回归测试。有网友提到,这本质上是让 AI 作为一个程序员,通过环境反馈持续修改代码,让外部软件系统学会任务。
这种“启发式学习”和传统的 Deep RL 有着本质区别。在 Deep RL 里,知识是不可见的参数;而在启发式学习里,知识是清晰的代码逻辑。这意味着它具备了极强的可解释性和样本效率。更重要的是,它能通过回归测试来“锁住”旧能力,让新规则不再轻易冲垮旧逻辑。
当然,这并非万能药。有观点认为,纯代码很难处理复杂的视觉感知任务。最理想的状态可能是混合架构:底层神经网络负责感知,中层代码负责逻辑和安全边界,顶层大模型负责审查日志并迭代代码。
过去,手写规则之所以被弃用,是因为人类维护这些“if-else”的成本太高,稍微改动就会引发连锁反应,变成难以收拾的“屎山”。但现在,当 Coding Agent 的维护成本大幅下降,那些曾经被认为无用的启发式规则,可能正在成为通往持续学习的新路径。
问题在于,当代码规则随着任务复杂度增加而不断堆叠,我们该如何防止这个系统最终演变成一个连 AI 都无法维护的混沌集合?
trinkle23897.github.io/learning-beyond-gradients