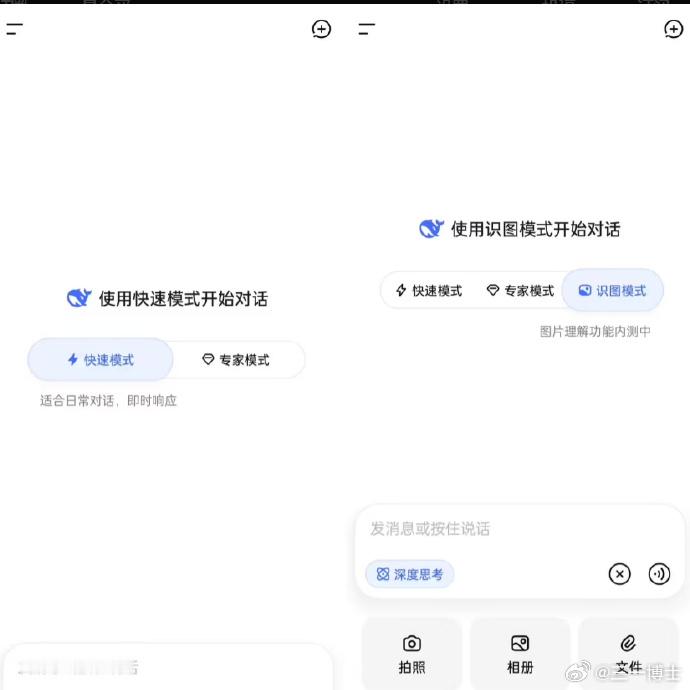
DeepSeek大范围开放了识图模式
DeepSeek之前灰度测试的“识图模式”,现在已经大范围开放体验内测。
识图的难点,不是把图片里的字抠出来。OCR只是第一步,真正难的是让模型看懂画面里的对象、位置、关系和意图。比如一张电路板图、一张报表截图、一张车机界面故障图,模型要知道哪里是主体,哪个细节异常,用户真正想问什么,还要把视觉信息和语言推理接上。
这也是DeepSeek开放识图的意义。大模型只会处理文字,入口就卡在“用户描述得清楚”这一步;能看图之后,很多问题可以直接丢现场材料。截图、图表、照片、作业题、产品说明、故障界面,都能变成输入。
AI助手要离真实工作更近,迟早得学会看图说话,这才叫多模态交互~