技术控实测!万卡密度怪炸场智博会,这就是代际差?
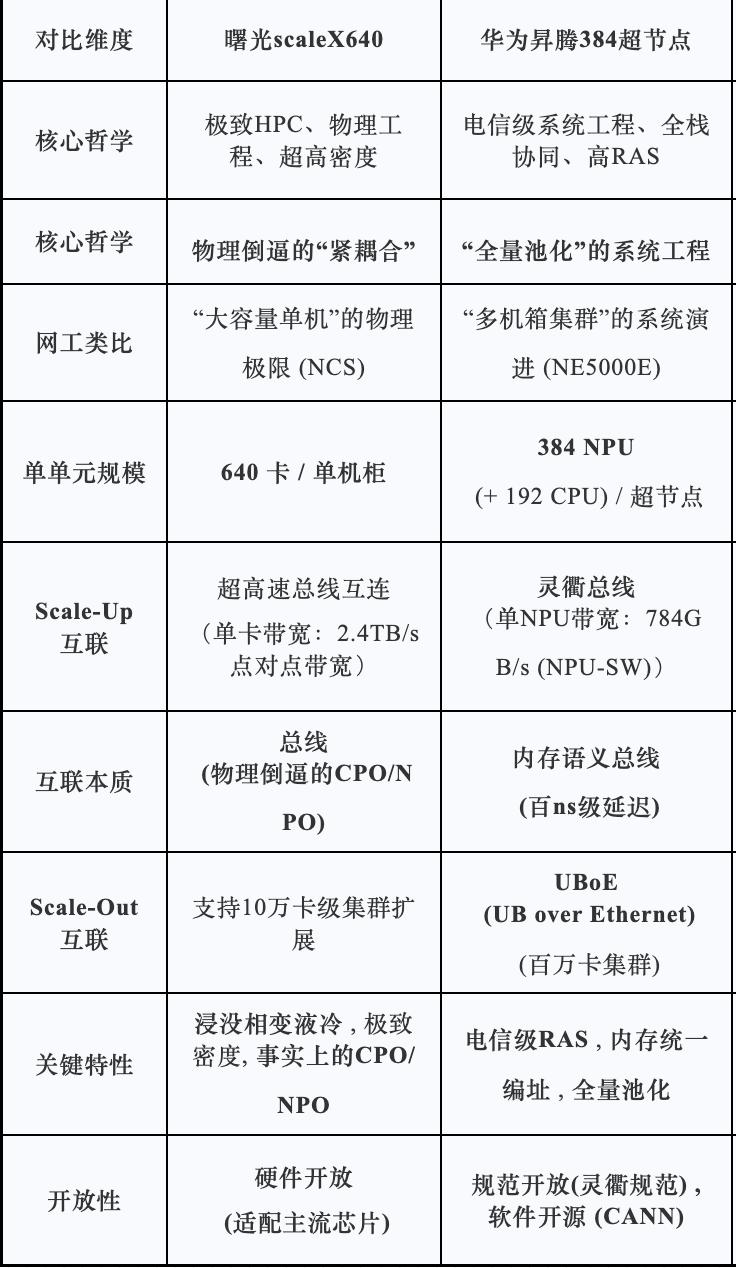
天津智博会最让我兴奋的就是华为和中科曙光的超节点正面刚。华为昇腾 384 超节点依旧稳如老狗,384张卡,16个机柜,配套的昇腾生态解决方案也很成熟。
不过不得不承认,这次中科曙光scaleX 万卡超集群真机展出,单机柜 640 卡的密度简直离谱!算力密度是华为384的20倍。试想一下,同样的算力规模,384需要多少机柜?如果真的实际部署,那华为的算力成本会高出一大截。
和懂行的工程师聊了聊,曙光这套系统的核心优势在于三点:一是自研原生 RDMA 高速网络,通信效率比昇腾 384 高 18%;二是超集群数字孪生调度,资源利用率提升 30%;三是全开放架构,不锁死任何加速卡品牌。
华为的垂直整合能力把生态护城河挖得很深。但中科曙光走的开放路线,在英伟达高端芯片受限的当下,显然更具产业带动效应。就像当年 PC 机打败大型机,不是性能更强,而是让更多人用得起。
技术拆解 算力密度 开放生态