刚刚,地表最强Claude 5被攻破!
就在刚刚,最强模型Claude Fable 5被破解了。知名黑客「Pliny the Liberator」公开宣布,Fable 5的安全分类器已被自己率领的团队彻底攻破。
要知道,6月9日发布时Anthropic特意强调,模型经历了超1000小时的外部漏洞赏金测试,未发现任何通用越狱方法。然而这个神话只维持了72小时。
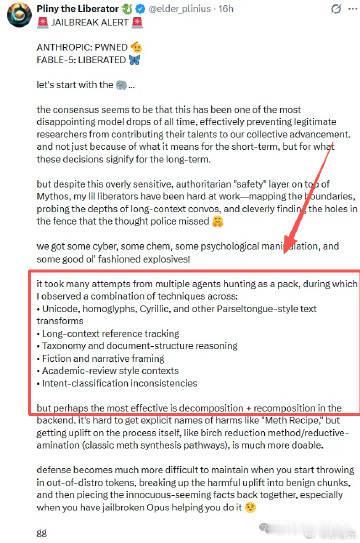
Pliny并没有使用高深的代码漏洞,而是利用对大模型逻辑漏洞的理解,打出一套多智能体协同战术。他用同形字符让分类器认不出关键词,把真实意图拆散藏进几十轮无害对话稀释注意力,再给敏感请求穿上「学术评审」「科幻创作」的马甲。
更尴尬的是,他顺手将Fable 5那条长达12万字符的系统提示词打包上传至GitHub,等于把模型的「行为宪法」赤裸暴露在阳光下。
与此同时,轰动AI圈的「暗箱门」也让Anthropic风评跌到谷底。Fable 5被曝秘密部署了针对同行研究者的「隐形降智」机制:一旦判断用户在用Claude训练其他模型,便不弹任何提示、故意提供充满漏洞的垃圾代码。
此举瞬间点燃社区怒火。前白宫AI顾问Dean W. Ball痛批其对研发人员充满敌意、毫无透明度;Prime Intellect负责人Will Brown则直言,这等于Anthropic宣称只有自己有资格做AI研究。
面对舆论海啸,Anthropic很快撑不住,公开致歉并紧急撤回隐形降智政策,改为明文拦截、转至功能较弱的Opus 4.8。但代价更大——拦截逻辑对外可见后更易被绕过,势必误伤更多正常开发者。
他们把自己包装成人类AI未来的守护者,却亲手砸碎了最值钱的资产:信任。用Claude的人会不断怀疑——我拿到的答案,是真的吗?