[LG]《Rethinking the Divergence Regularization in LLM RL》J Yao, X Zhou, P Qi, W S Lee… [Tencent Hunyuan & NUS] (2026)
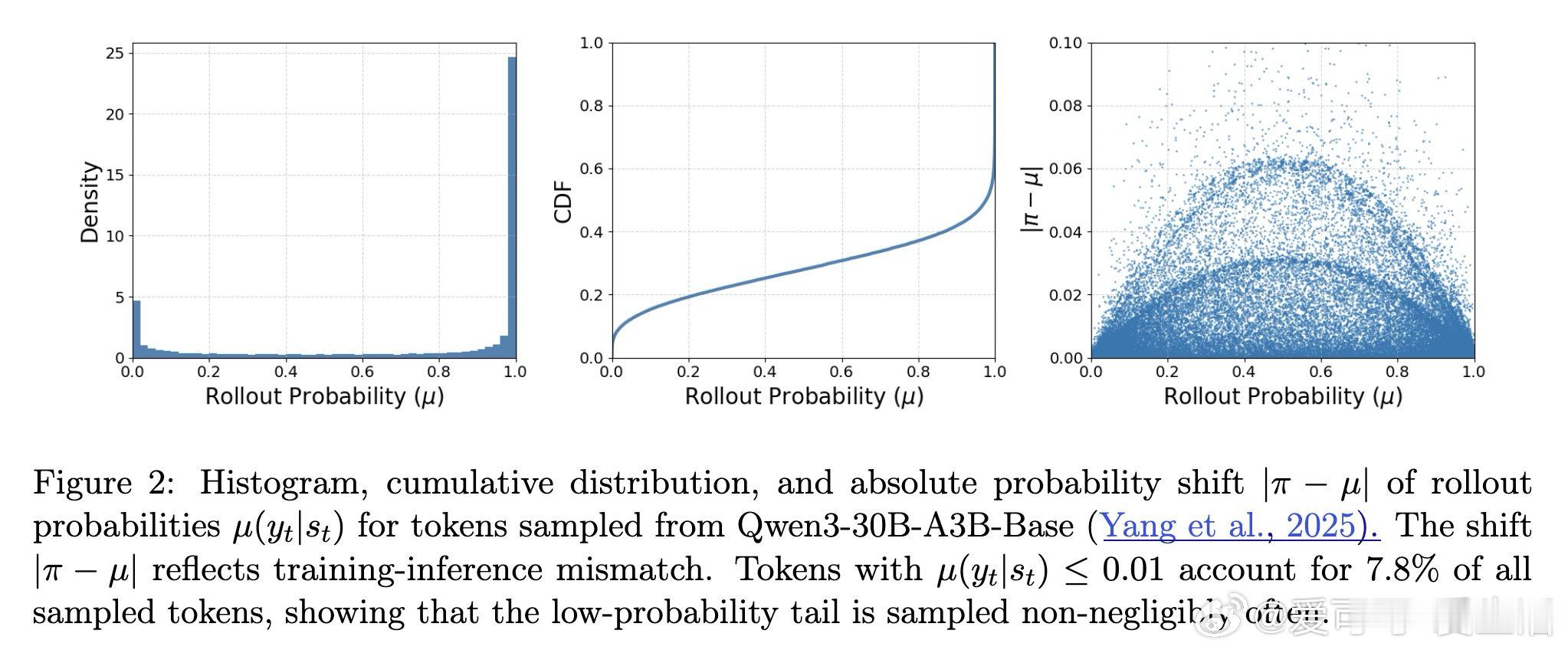
在大语言模型的强化学习中,训练与推理的数值差异加上批次策略老化使得优化本质上是离策略的。主流方法如PPO通过重要性比率裁剪来控制信任域,但比率在长尾词表中是分布偏移的糟糕代理:低概率词的小增长可能产生巨大比率却几乎不改变概率质量,而高概率词的适度比率变化却能显著改变策略。
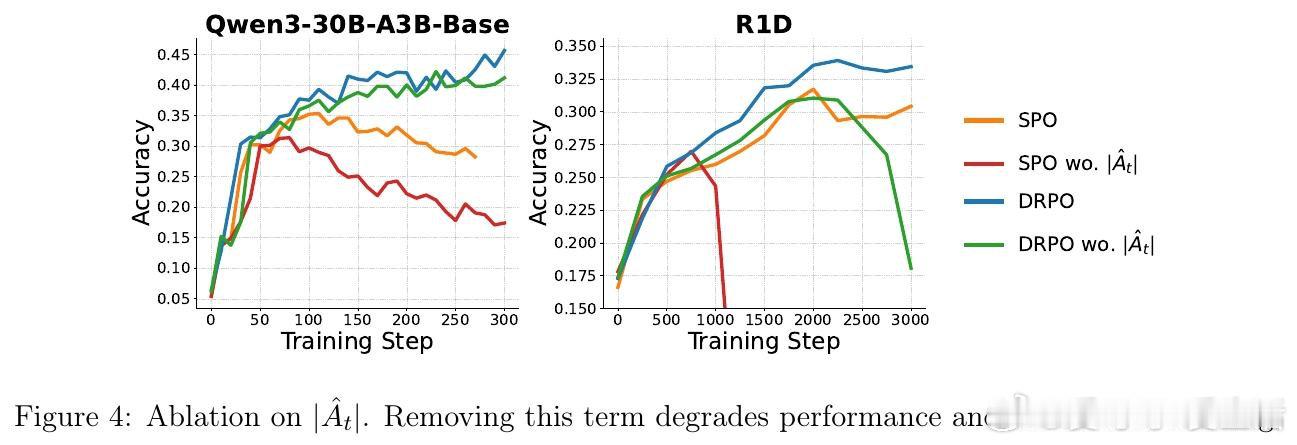
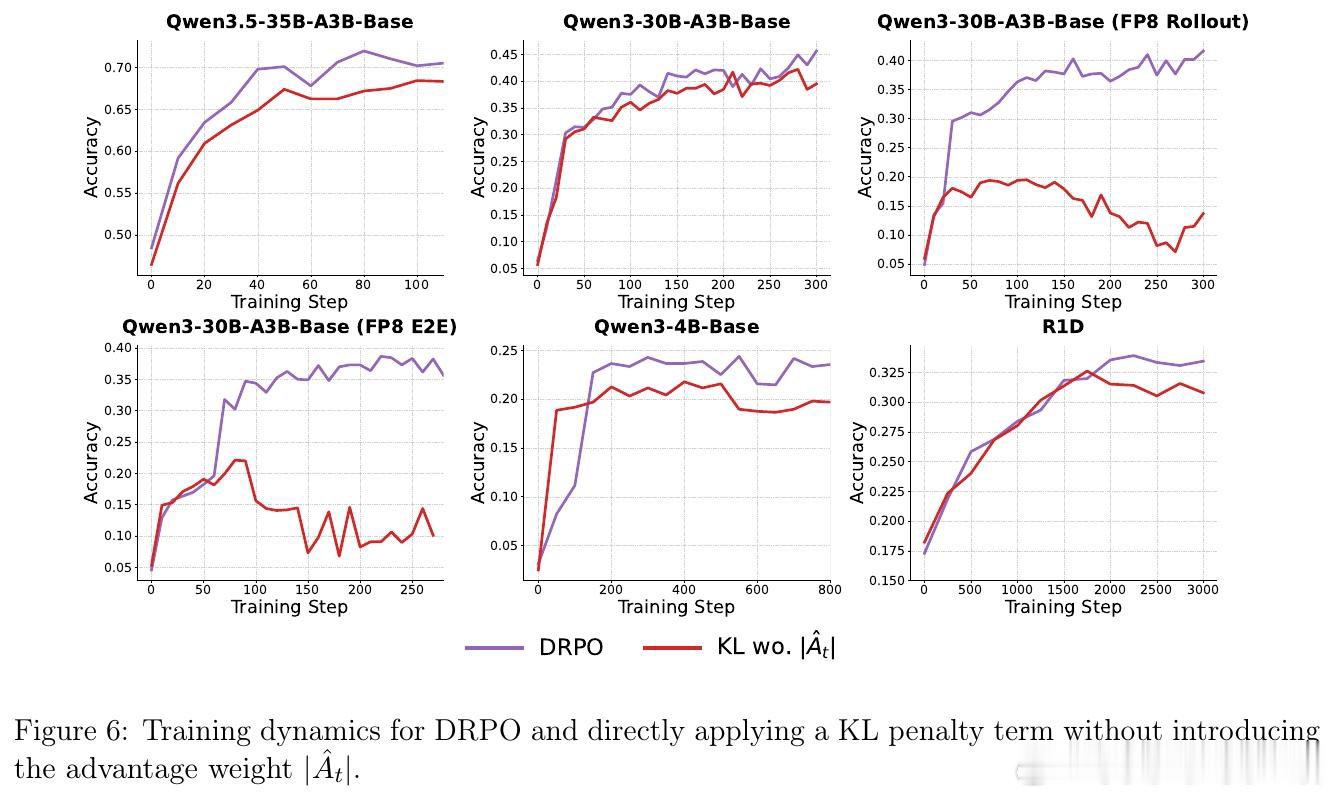
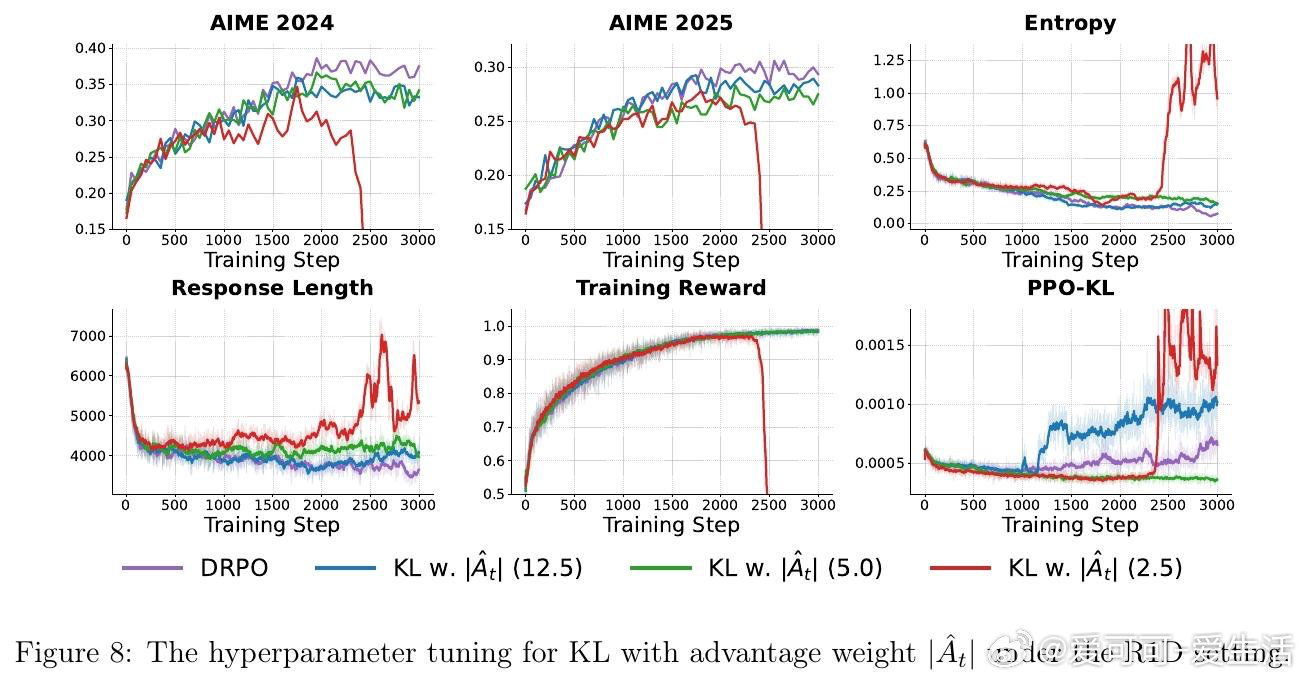
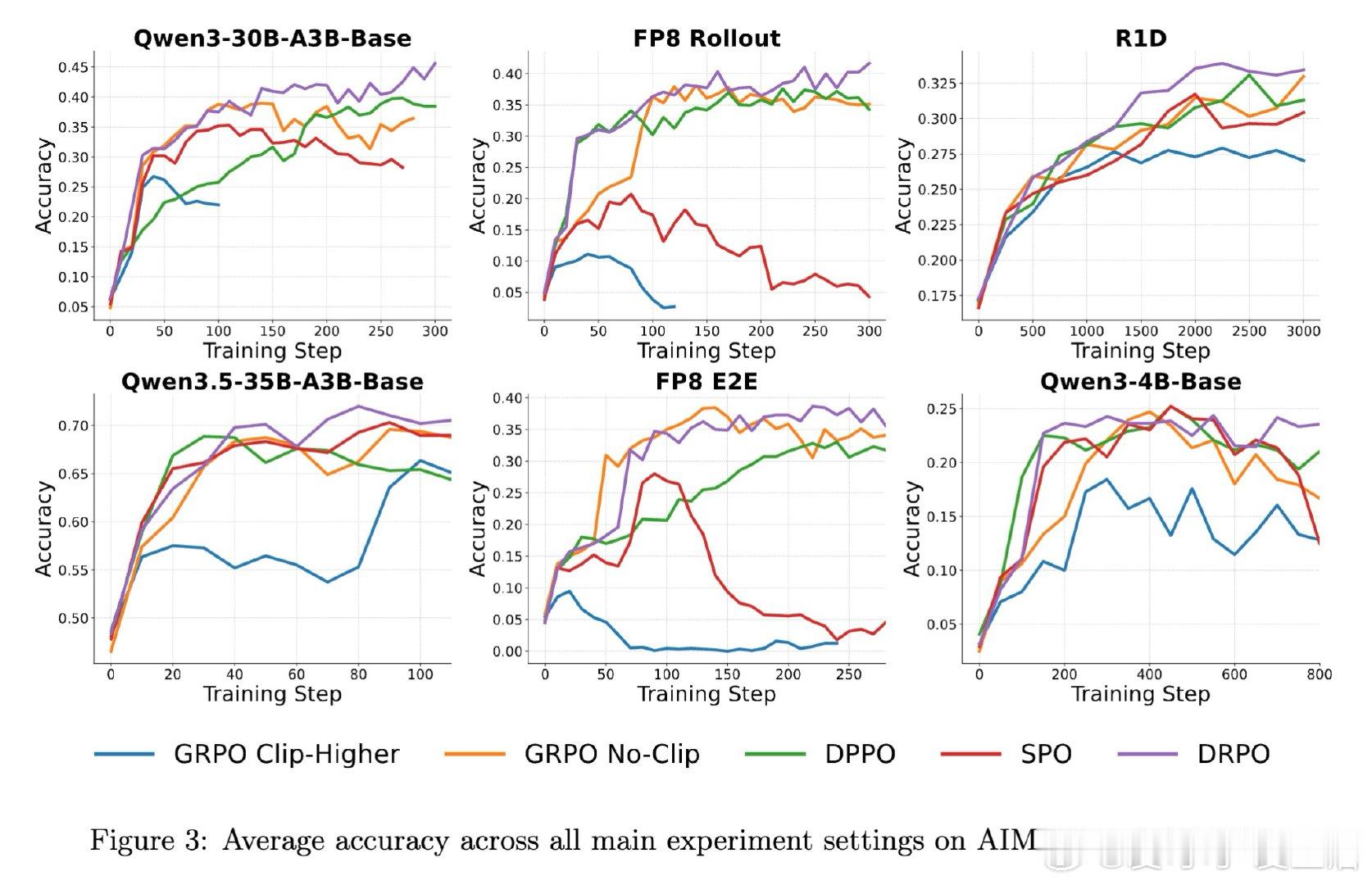
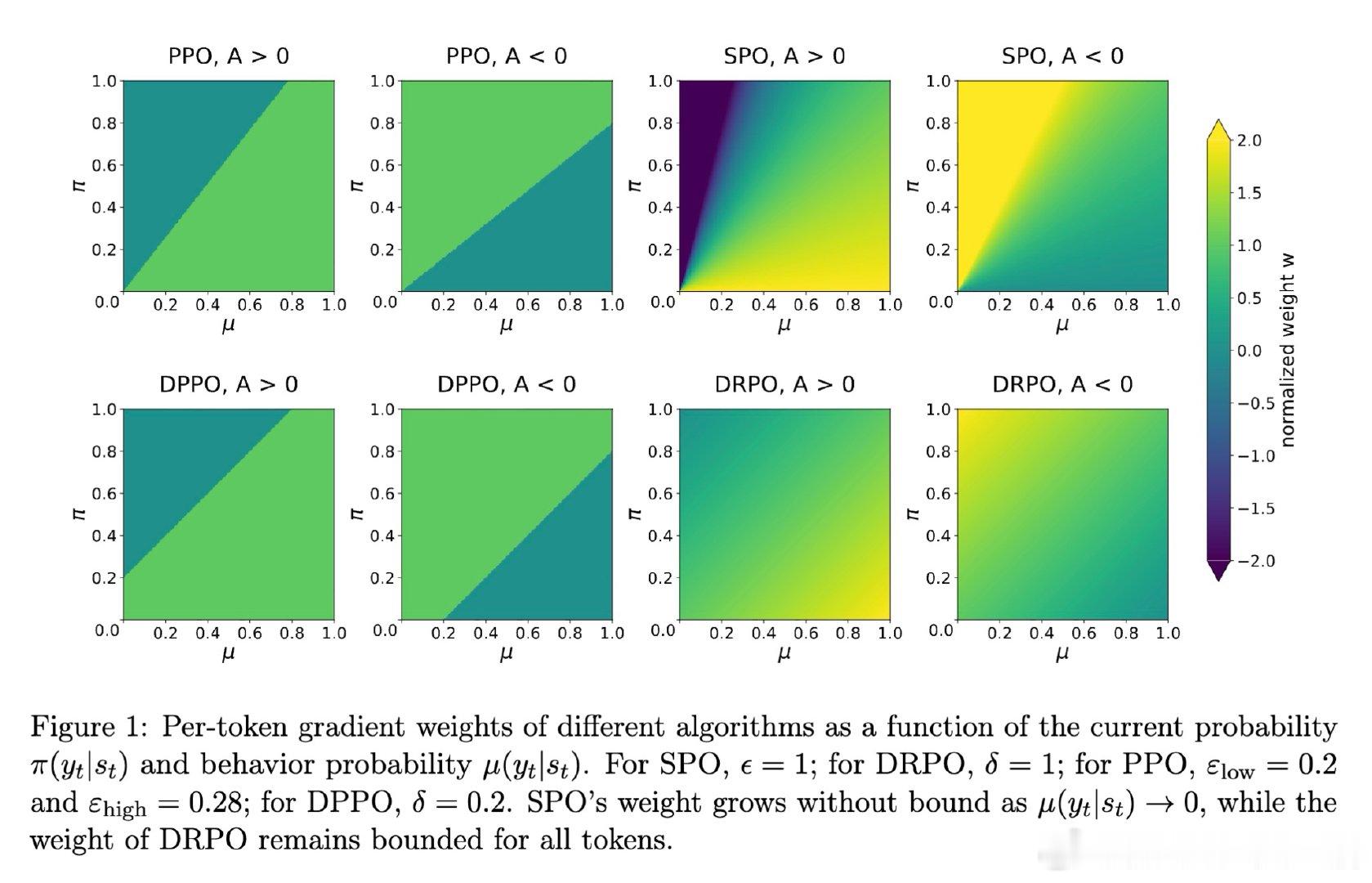
本文的核心洞见是:将信任域从固定比率约束重构为绝对概率偏移约束。DPPO用基于散度的硬掩码替代了比率裁剪,但掩码在边界处仍会突然截断梯度且不提供修正信号。DRPO进一步将硬掩码替换为平滑的优势加权二次正则项,该正则化器通过行为概率μ(yt|st)缩放SPO的惩罚,使每个词元的最优点从|rt−1|=ε变为|π(yt|st)−μ(yt|st)|=δ,从而在保留DPPO的Binary-TV信任域几何的同时,诱导出连续衰减的梯度权重。
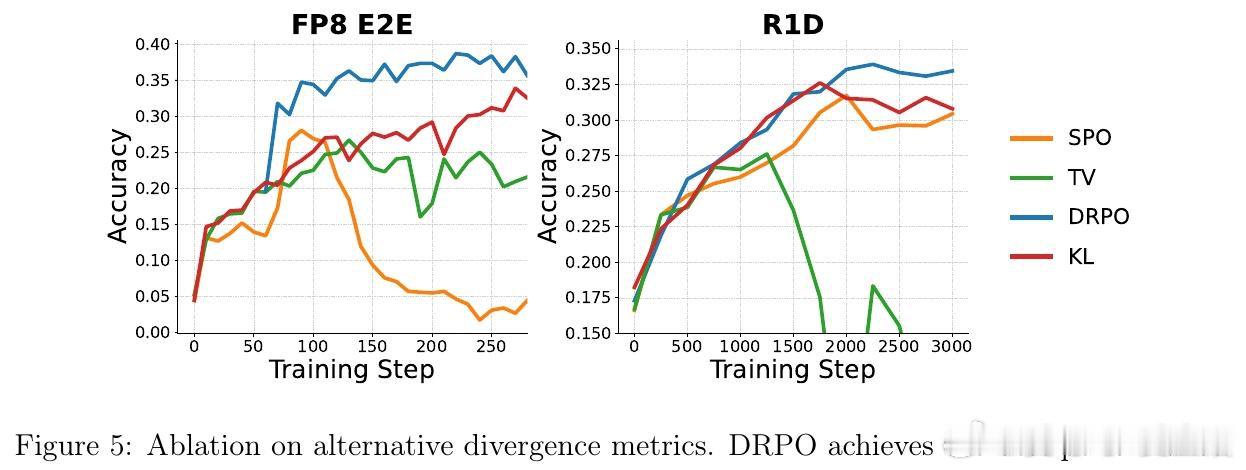
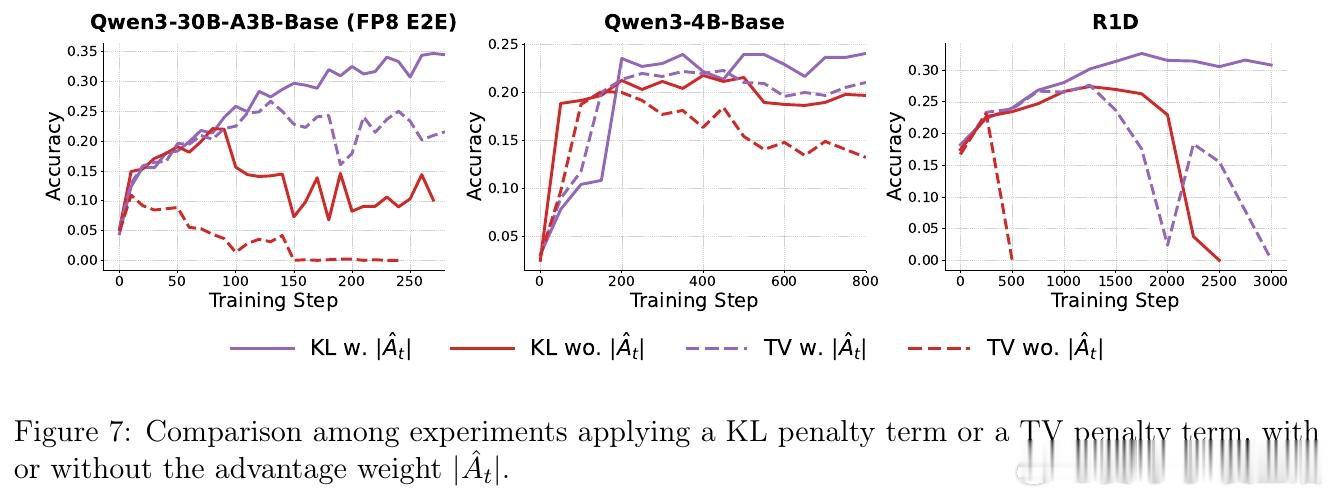
这项工作真正留下的遗产是揭示了正则化器的梯度形式比目标中的名义散度更关键。它为后来者打开的新门是一个设计准则:有效的LLM RL正则化器应诱导与分布偏移对齐的稳定边界、在长尾词表中保持有界的梯度权重、并在策略越界时提供平滑修正信号。但尚未跨过的门槛是如何在不依赖优势加权的情况下维持这些性质,以及如何将这一框架推广到更复杂的多目标优化场景。
arxiv.org/abs/2606.09821 机器学习 人工智能 论文 AI创造营