[LG]《Rubric-Guided Self-Distillation: Post-Training Without Rubric Verifiers》M Rezaei, A Mahmoud, Z Wang, U Tyagi… [Scale AI] (2026)
在开放式任务的强化学习中,传统方法依赖外部大模型对每条生成轨迹按评分标准(rubric)逐项打分,将多维度评价压缩为单一奖励信号。这种做法既产生巨大的计算开销(每个训练步需调用评分模型数十次),又将优化过程暴露在评分模型的偏见之下,且稀疏的轨迹级奖励无法精确告诉模型哪些具体决策满足了哪条标准。
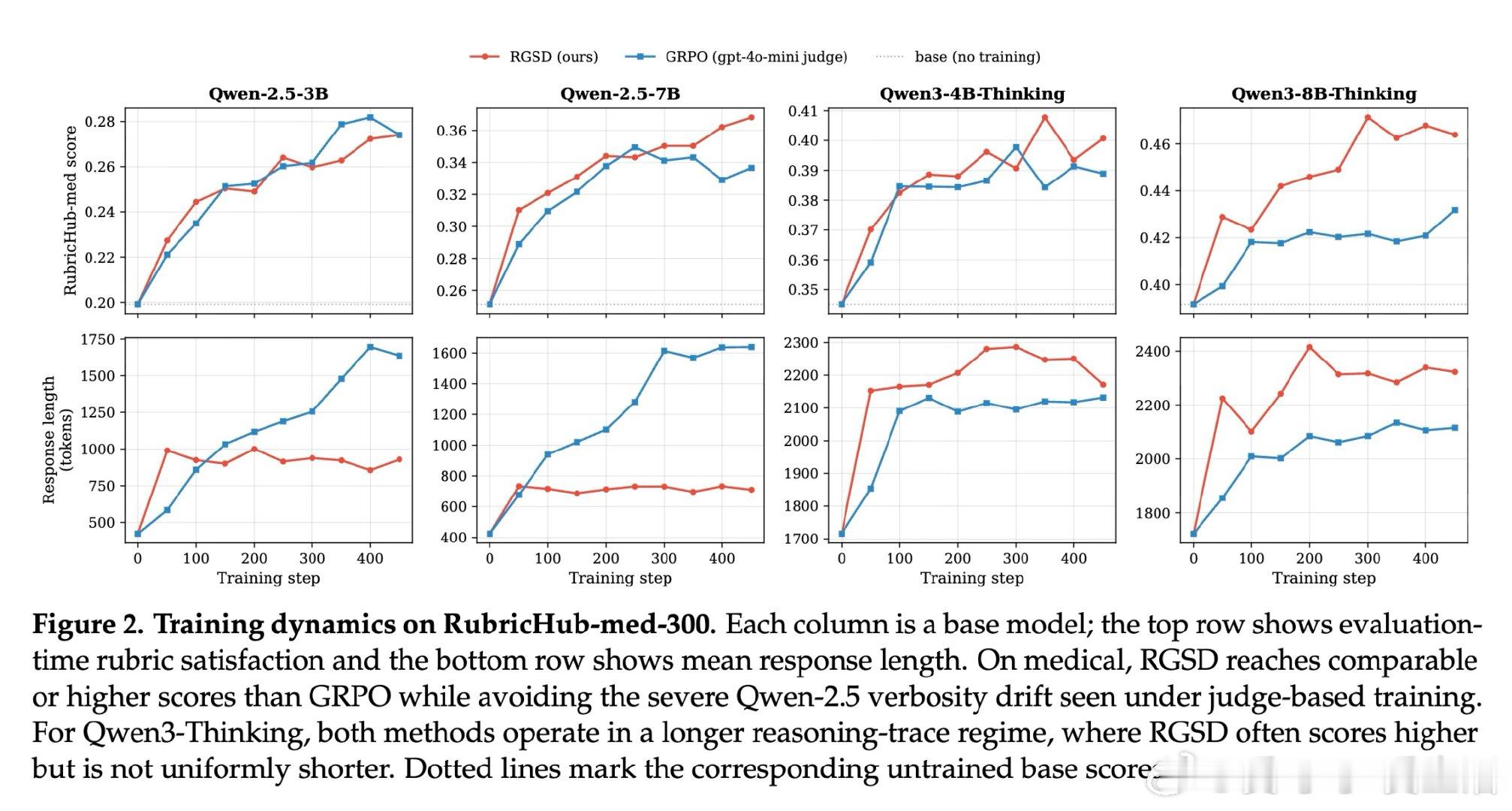
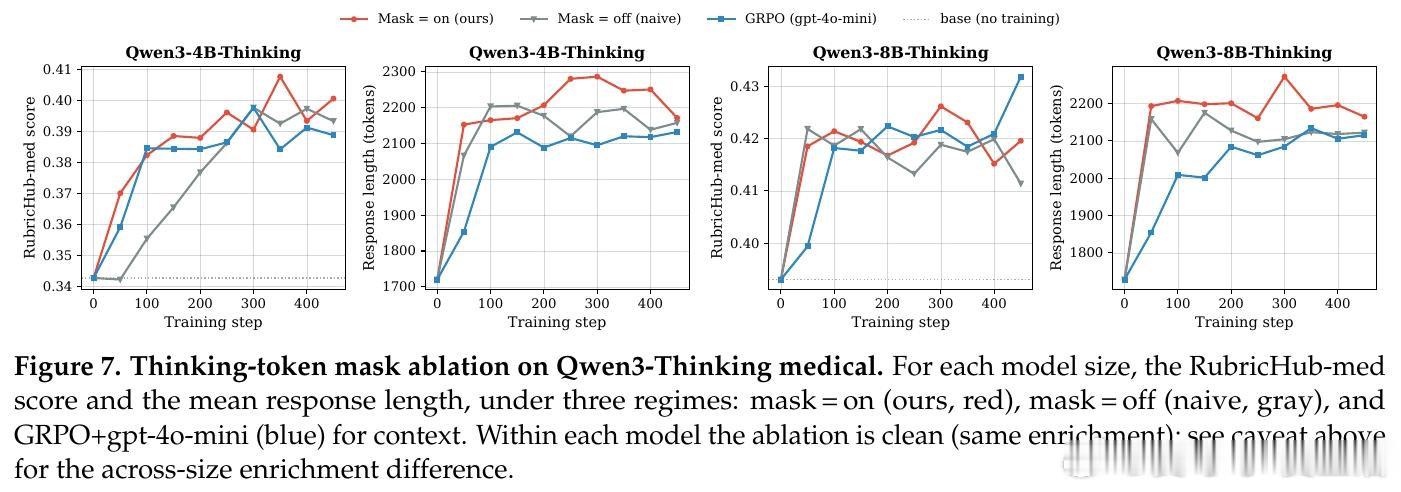
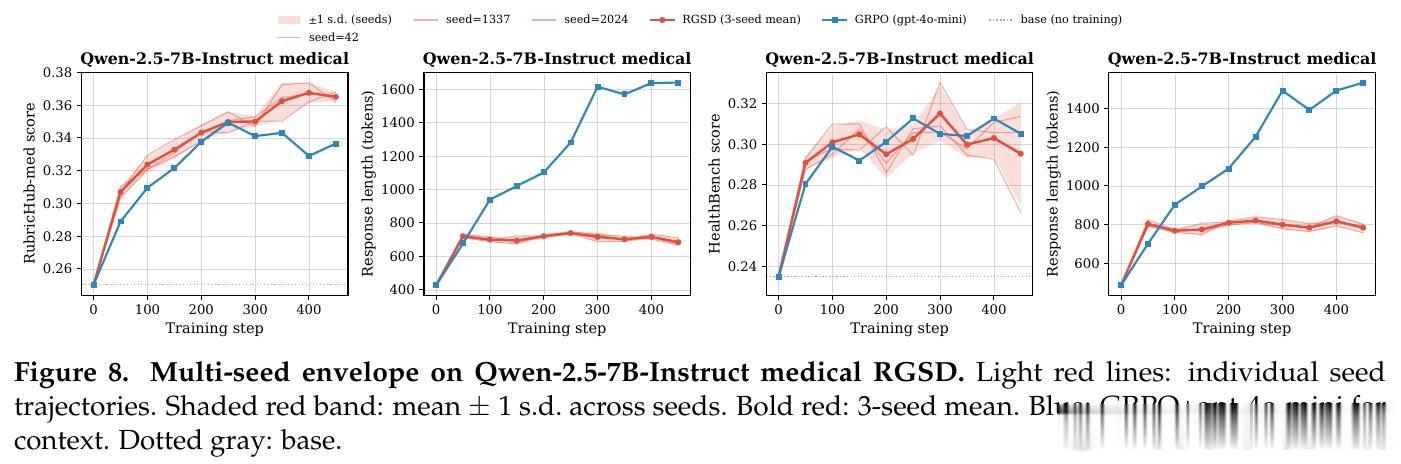
本文的核心洞见是:同一基座模型在看到评分标准后的回答质量比未看到时提升30-45个百分点,这一差距本身就是可转移的监督信号。RGSD将基座模型分裂为教师(输入包含评分标准)与学生(仅输入问题),在学生的每条在线采样轨迹上,逐token蒸馏教师的条件分布至学生,把外部评分器从训练循环中彻底移除,将稀疏的轨迹奖励替换为密集的逐token学习信号。
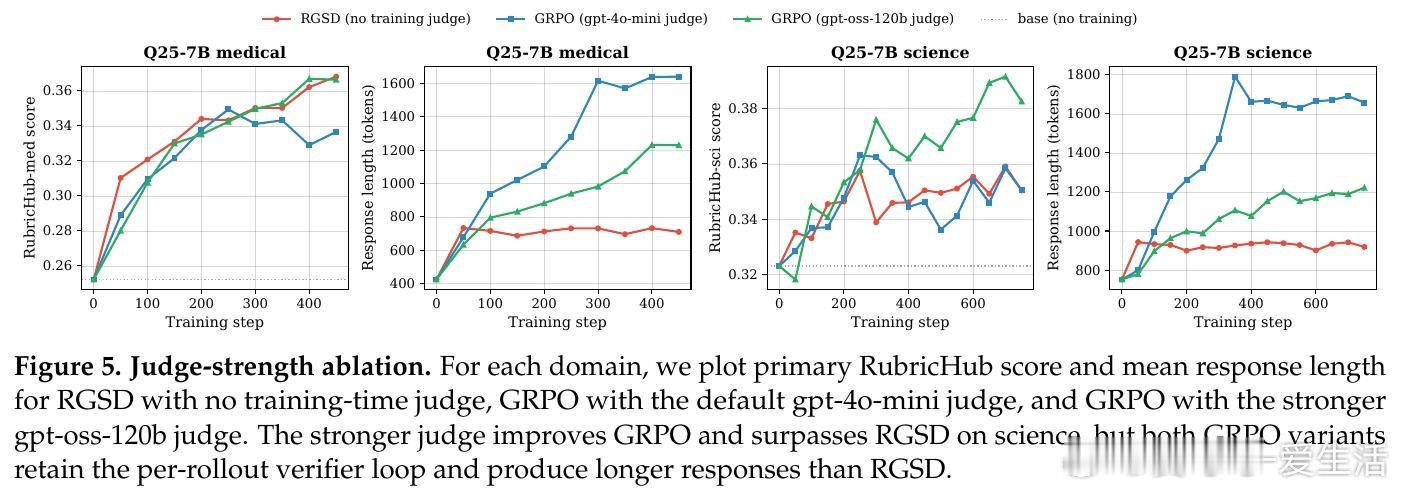
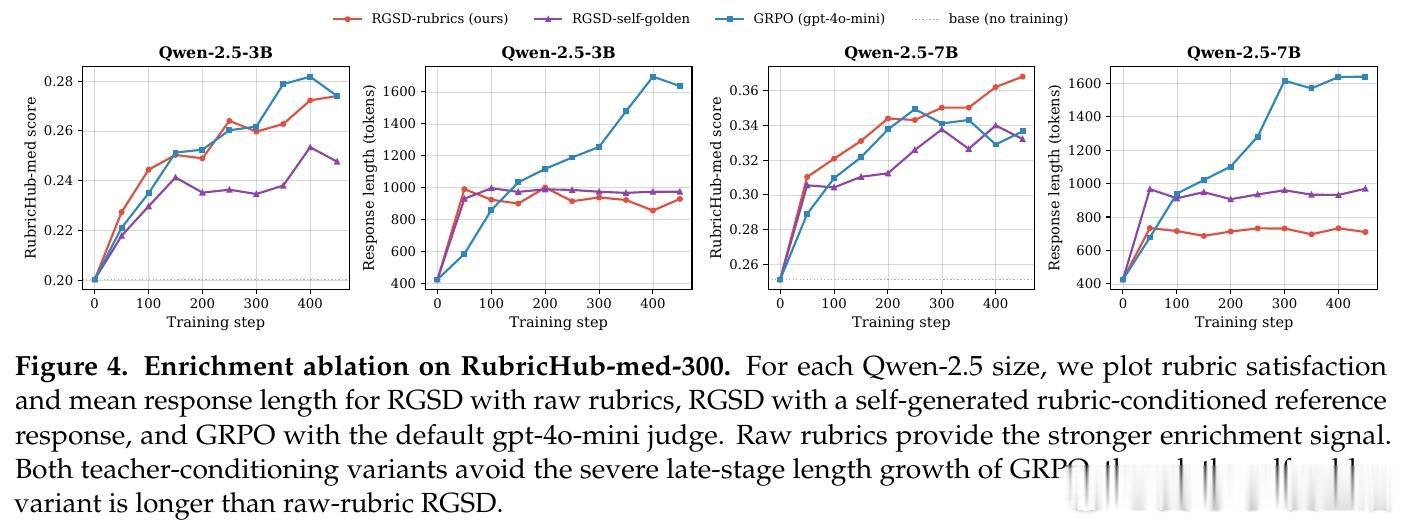
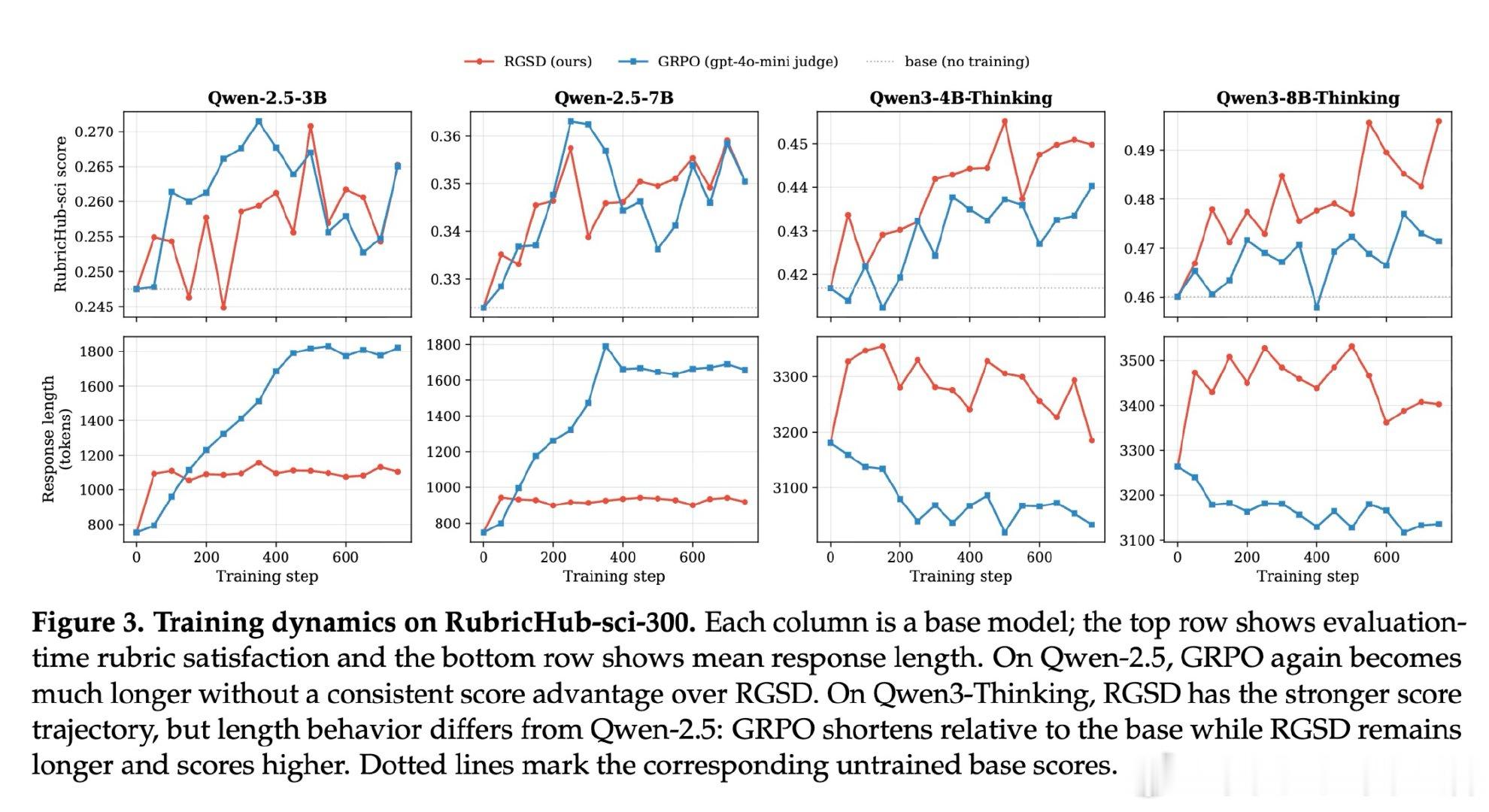
这项工作真正留下的遗产是证明了评分标准无需仅作外部裁判工具,它可以直接作为教师的特权上下文驱动自蒸馏。在医疗与科学领域的实验中,RGSD以零评分器调用、单条轨迹采样达到了与16倍采样基于评分器GRPO相当的性能,并在Qwen-2.5模型上避免了后者严重的冗长漂移。但尚未跨过的门槛是:当可获得更强评分器且成本可承受时,GRPO仍可能在某些设置中取得更高分数,因此RGSD更适合评分器成本高昂或不可靠的场景,而非对评分器方法的普适替代。
arxiv.org/abs/2606.12507 机器学习 人工智能 论文 AI创造营