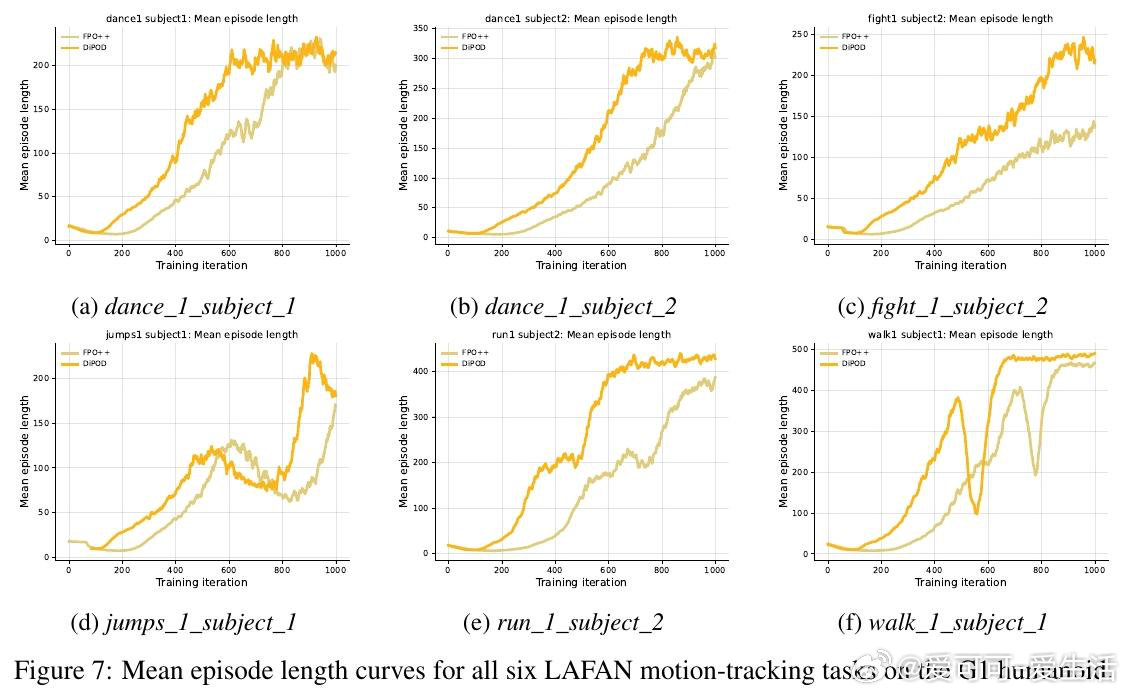
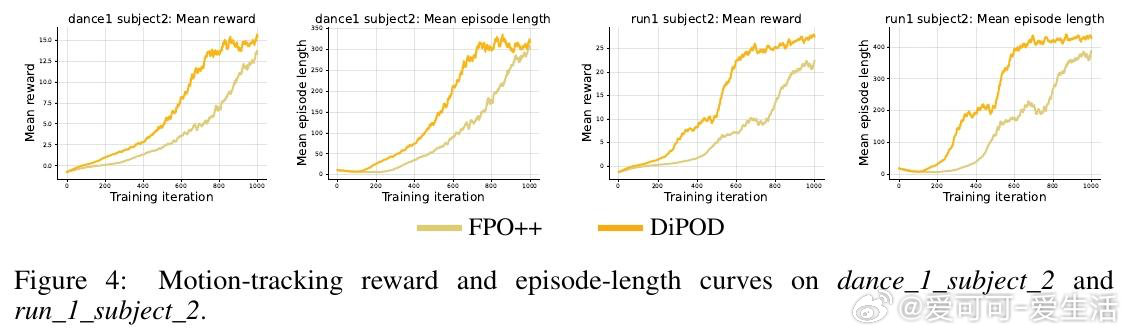
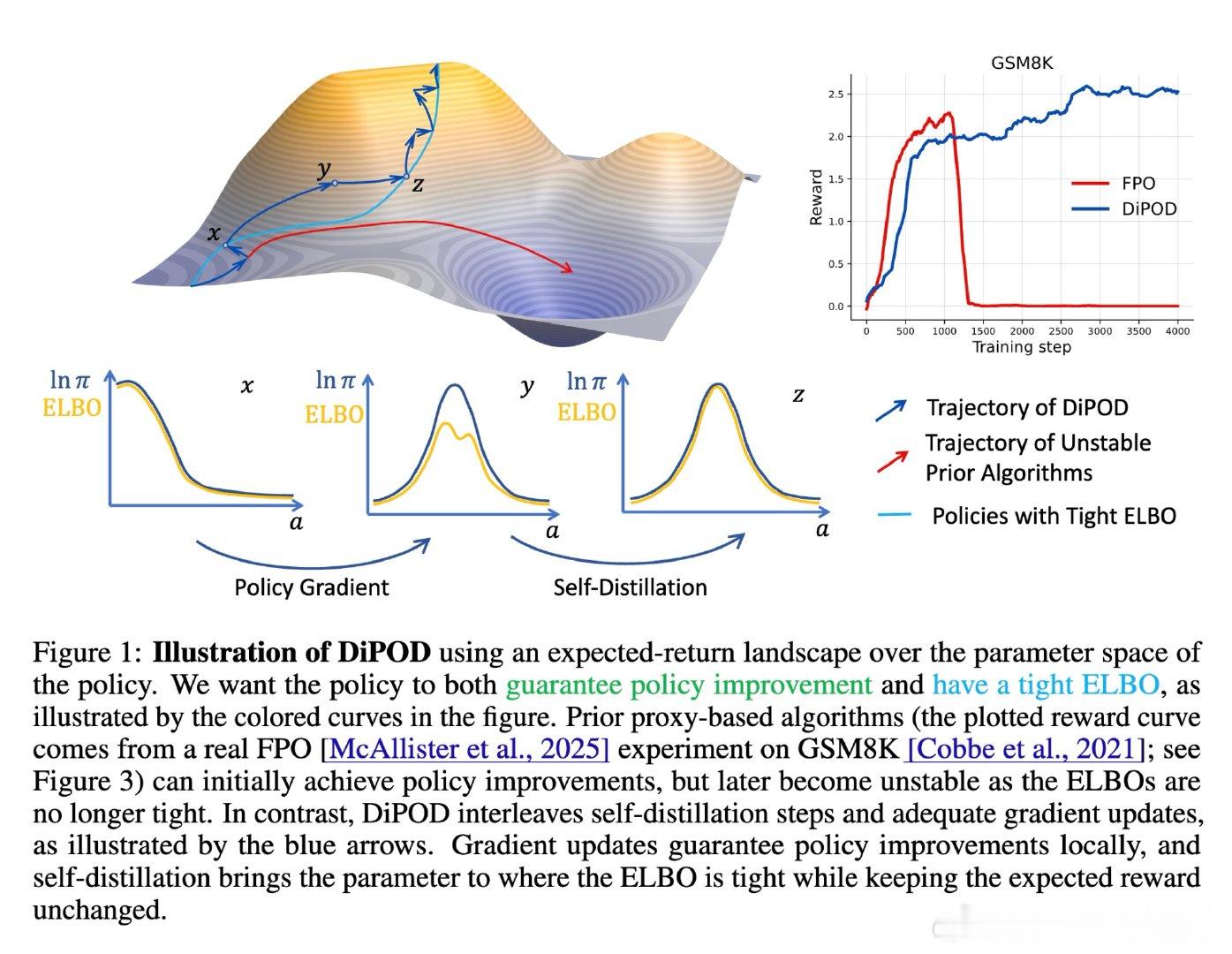
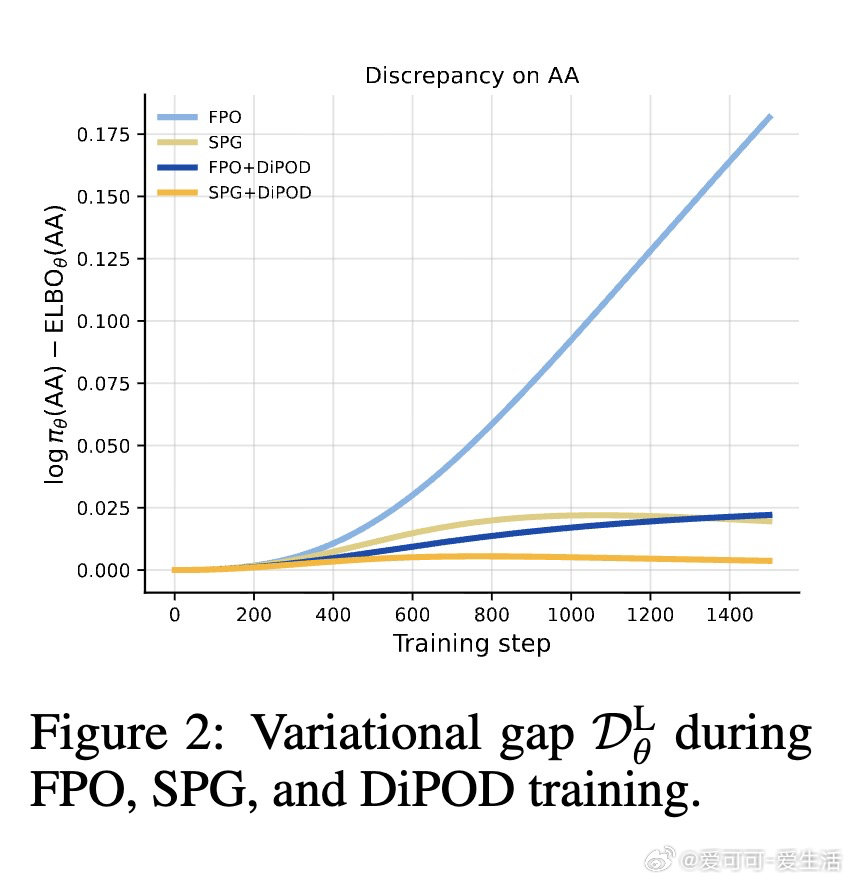
[LG]《Diffusion Policy Optimization without Drifting Apart》H Jiang, H Feng, P Abbeel, J Jiao… [UC Berkeley] (2026)
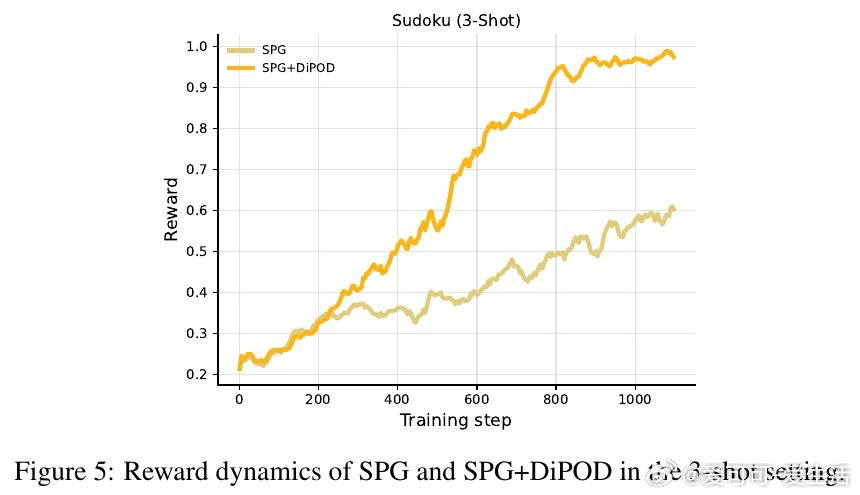
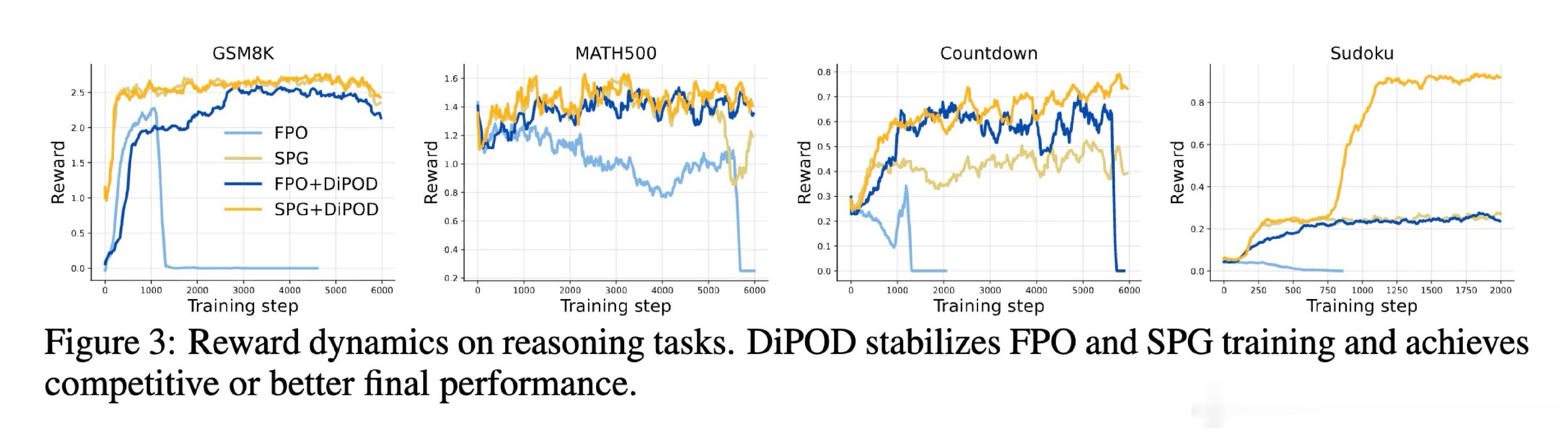
在扩散策略领域,RL后训练常先涨后崩:代理目标还能升,真实回报却掉。过去方法受困于ELBO与似然越走越散,本质原因是更新同时改了“答案”和“尺子”。
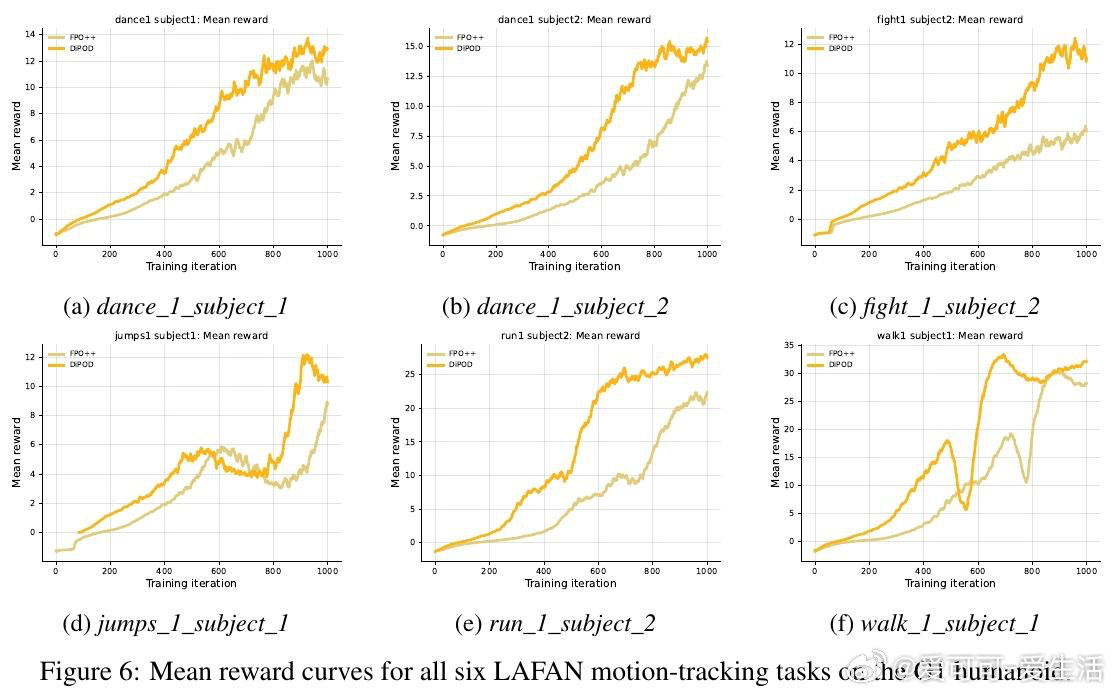
本文的核心洞见是:把ELBO漂移看作问题本身,而非只盯回报。由此,用同一批轨迹做自蒸馏先把ELBO拉紧,再做策略梯度;每步再加一项ELBO正则,阻止两者继续分家。
这项工作留下的遗产是:把“保持代理可信”变成RL后训练的设计原则。它为扩散语言模型和连续控制打开了稳定优化的路径,但仍依赖合适的蒸馏强度与近似的ELBO。
arxiv.org/abs/2606.13795 机器学习 人工智能 论文 AI创造营