[LG]《A theoretical model for task routing in mixture-of-expert transformers》Y Xiang, V Nandakumar, Y Yao, P Li… [University of Sydney & Zhejiang University] (2026)
MoE语言模型中,任务专家专化已被实验观测,却缺乏理论保证。现有框架受困于高斯混合等连续分布假设,本质是这类模型无法表达离散句法结构,亦不包含注意力机制。
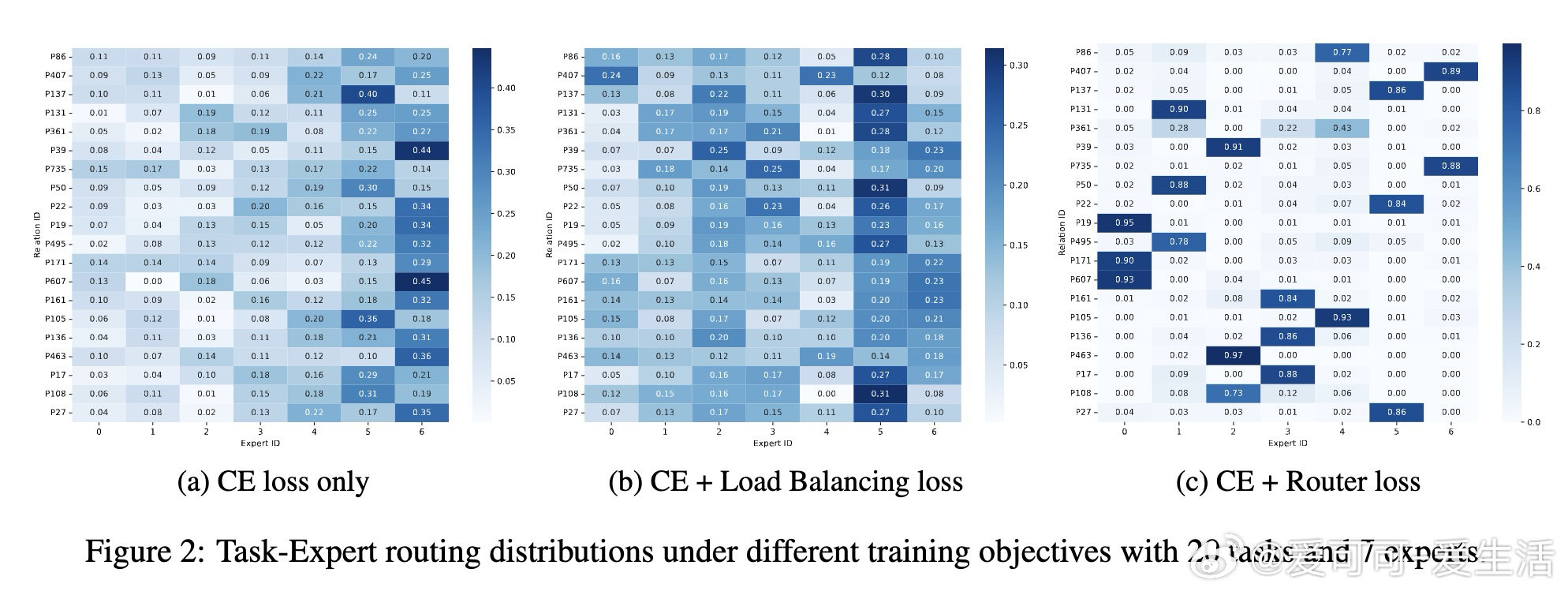
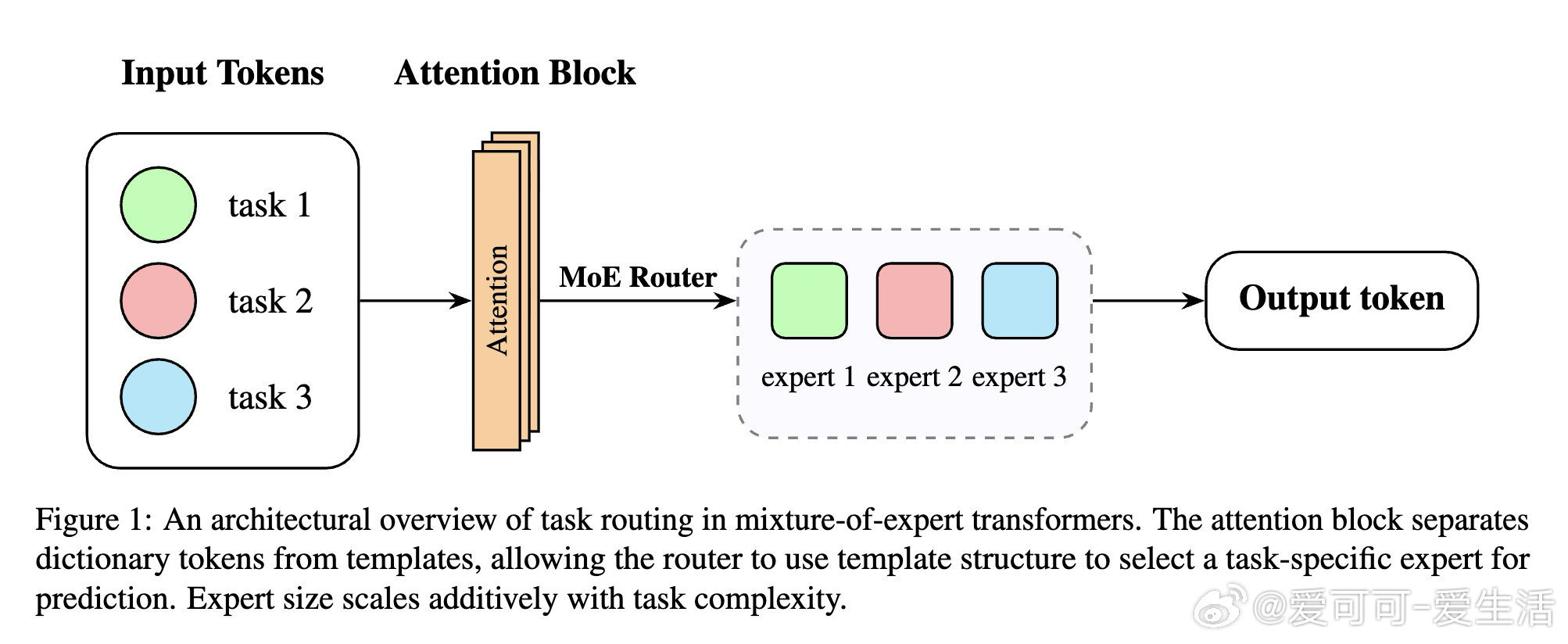
本文的核心洞见是:把结构化知识重新看作句法模板与键值字典的二元组合。由此,注意力头将语法结构与事实主语解耦这一关键操作使问题得以解开——路由器仅凭模板向量即可精准将输入导向对应任务专家。
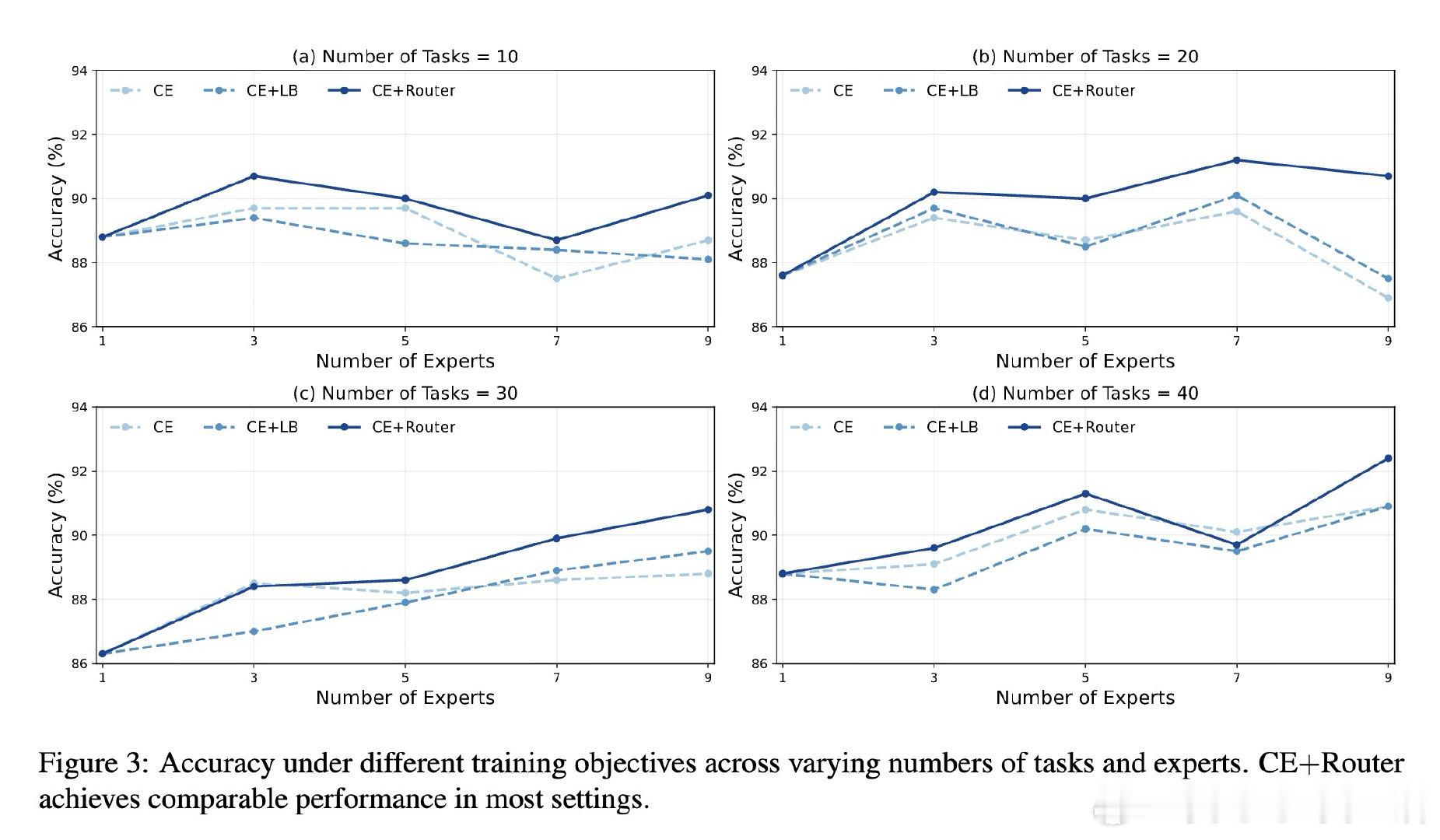
这项工作真正留下的遗产是含注意力机制的MoE任务专化首个构造性证明,专家容量由任务固有复杂度严格界定。它为后来者打开的新门是可解释知识电路的设计语言,但尚未跨过的门槛是证明局限于单层合成数据——深层网络与无监督路由仍无理论覆盖。
arxiv.org/abs/2606.14398 机器学习 人工智能 论文 AI创造营