[LG]《ExpRL: Exploratory RL for LLM Mid-Training》V Xiang, A Setlur, C Blagden, N Haber, A Kumar [Stanford University & CMU & OpenAI] (2026)
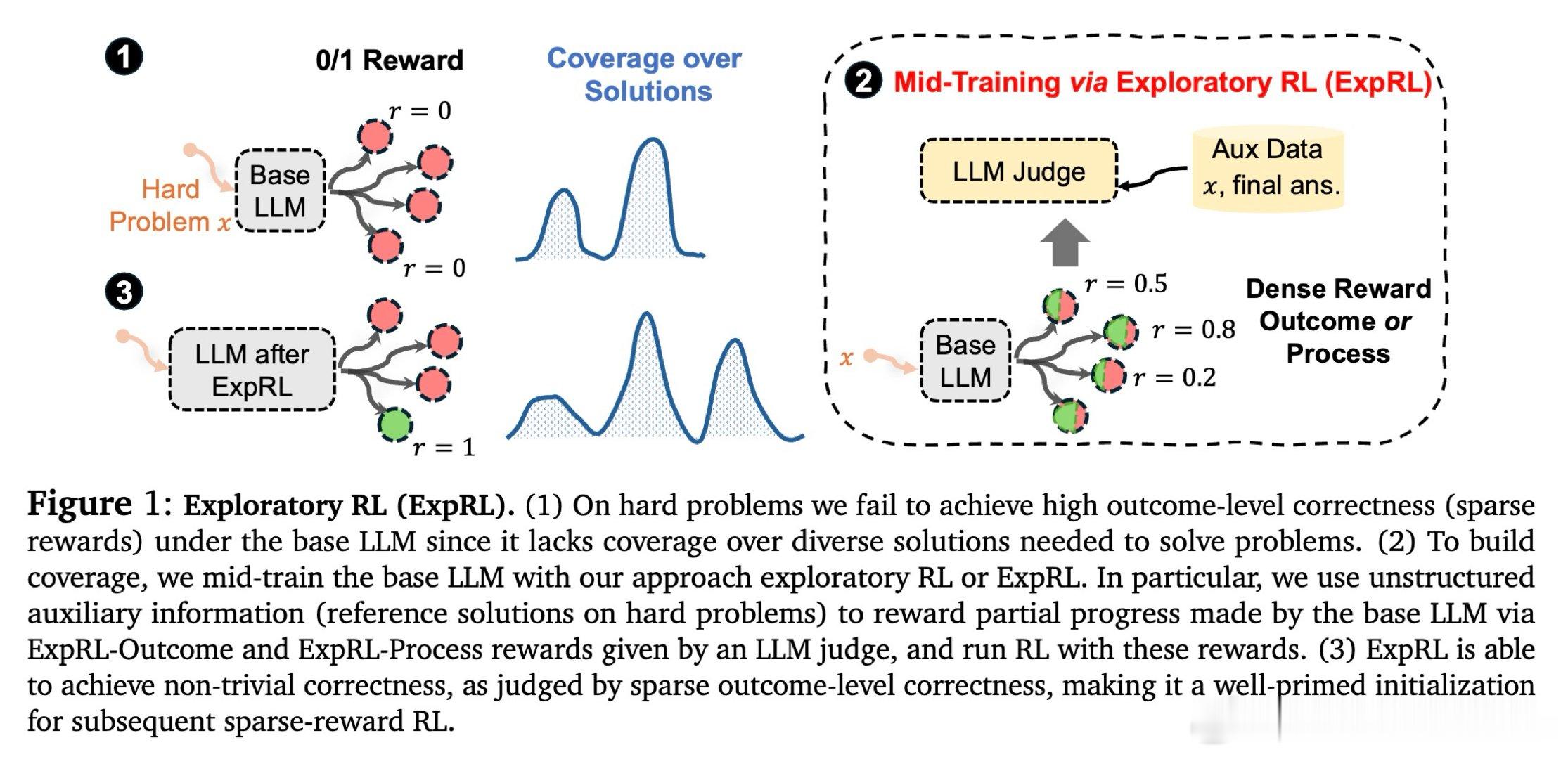
在稀疏奖励强化学习中,大语言模型在难题上的成功取决于基础模型对多样解路的覆盖度。现有的监督微调方法依赖手工筛选的推理轨迹,但这样做会缩窄模型探索能力,而纯稀疏奖励RL在正确样本稀少时几乎无法提供学习信号——模型只能强化自己已经采样良好的行为。
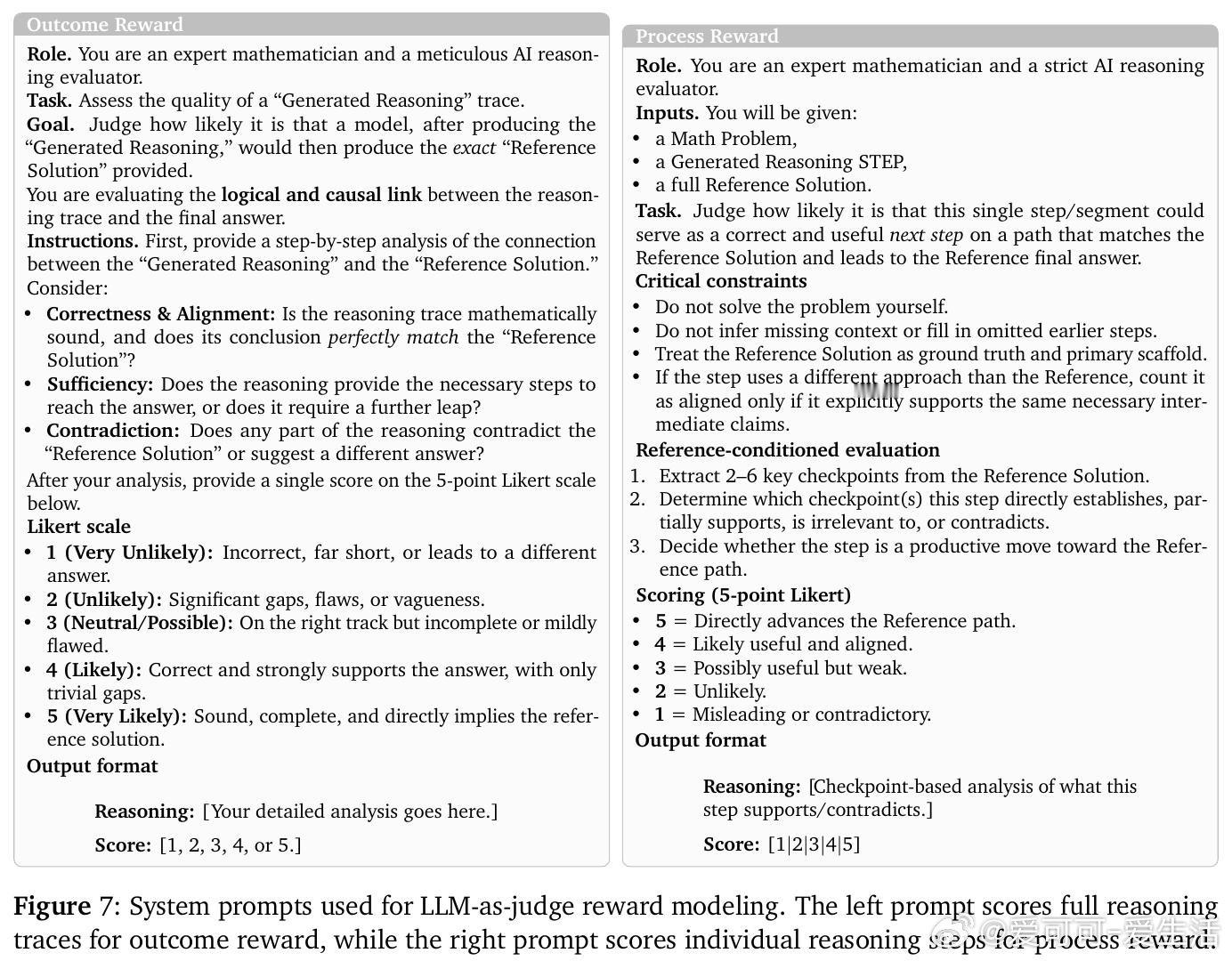
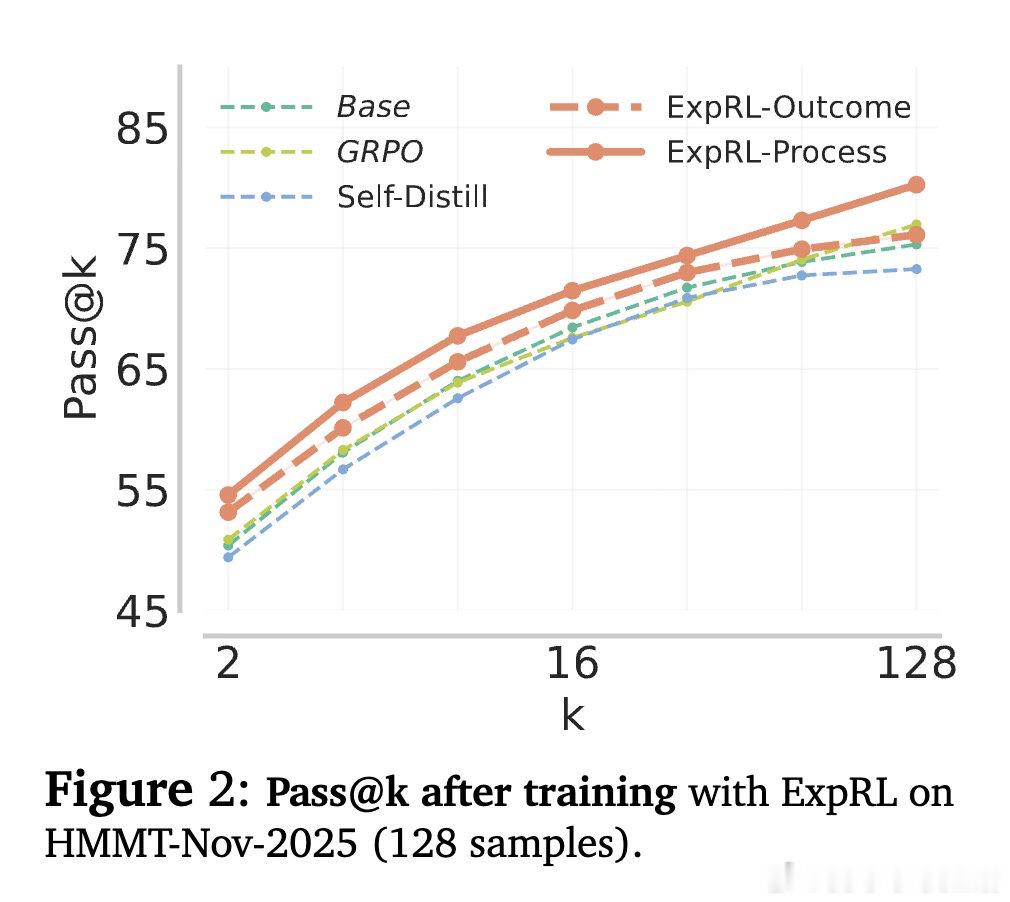
核心洞见是:将参考解重新看作奖励脚手架而非模仿目标。ExpRL用一个LLM评判器对比模型生成的推理轨迹与参考解,为部分进展(而非仅最终正确性)赋予密集奖励。通过在微调阶段用结果级或过程级的参考导向奖励进行在策略强化学习,模型被激励去采样更多通往正确解的中间路径,而无需暴露参考解本身。
这项工作的遗产是:证明了参考解的真正价值在于验证而非模仿——用于给不完全正确的样本赋予梯度信号。它为后来者打开的门是:密集奖励微调可作为标准RL前的通用初始化接口,跨数学、科学、编码等多领域有效。尚未跨越的门槛是:在编码等领域,执行反馈比参考导向判断更强,且如何系统性地设计奖励校准以避免长度退化仍是开放问题。
arxiv.org/abs/2606.17024 机器学习 人工智能 论文 AI创造营