[LG]《How Post-Training Shapes Biological Reasoning Models》L Fesser, H Zhang, M M. Li, E Wang… [Harvard University] (2026)
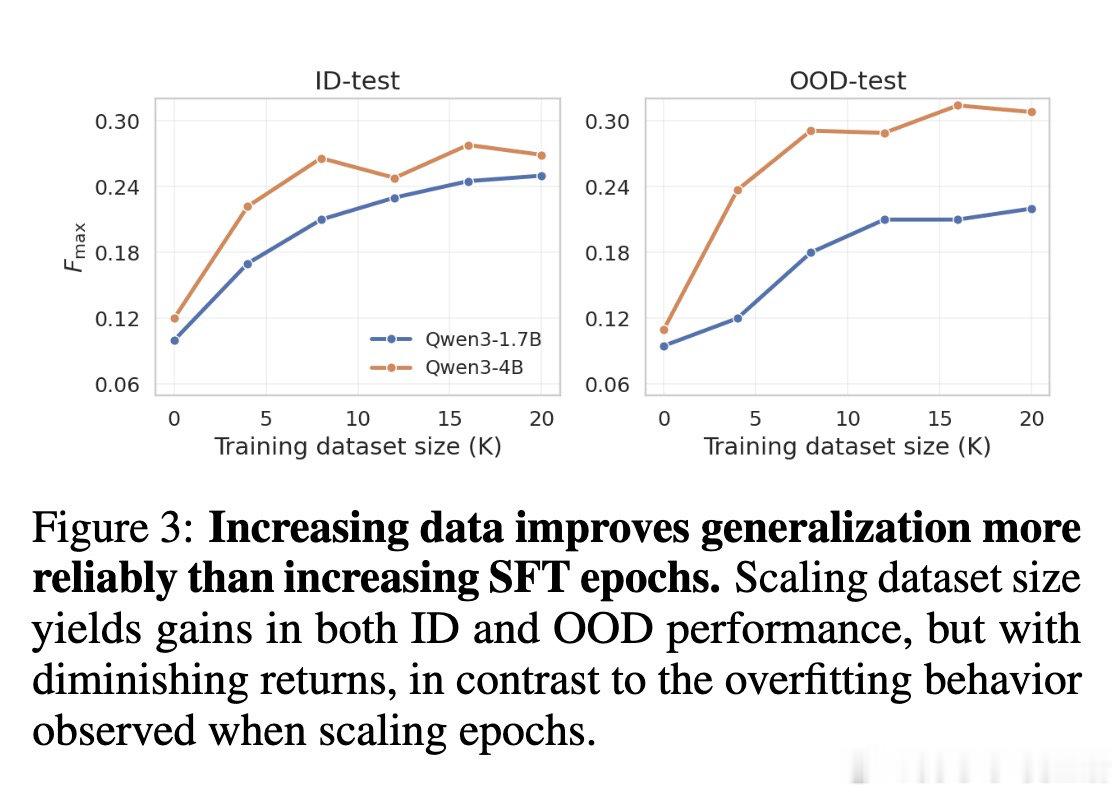
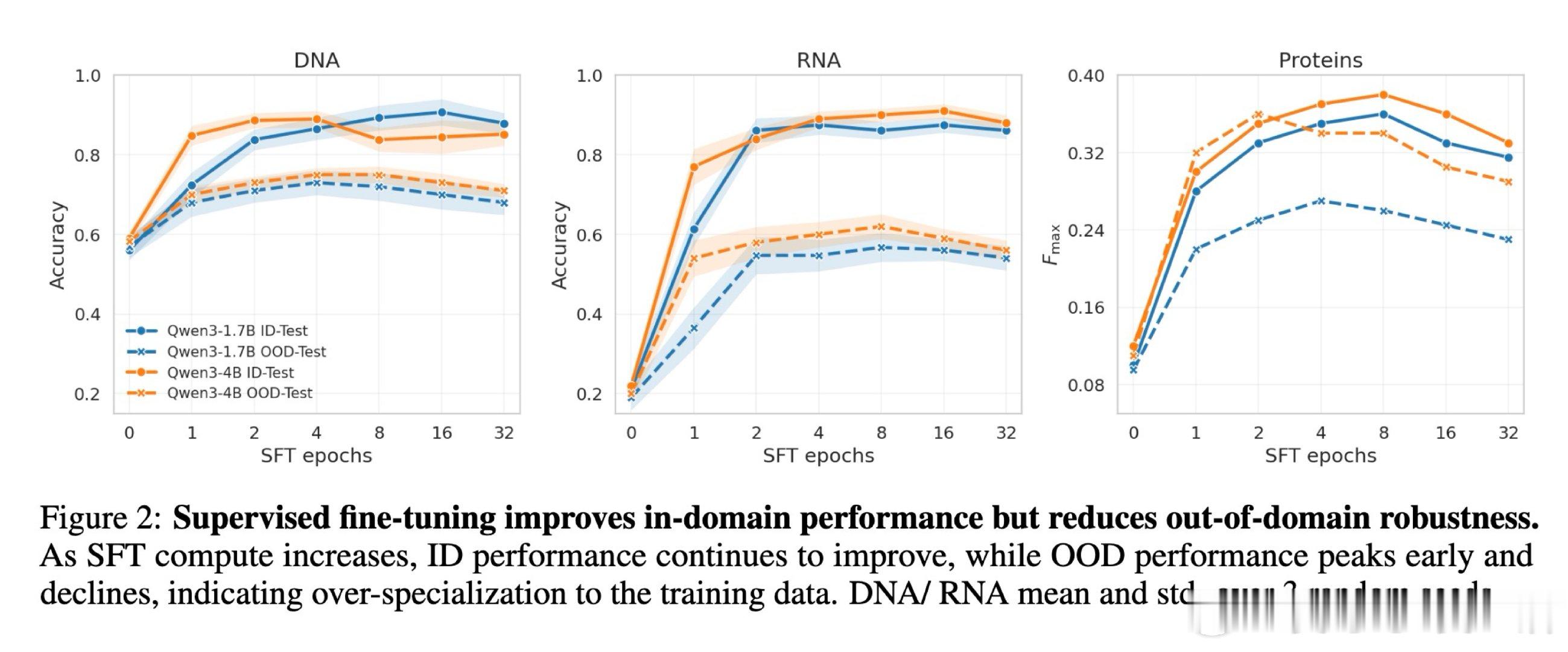
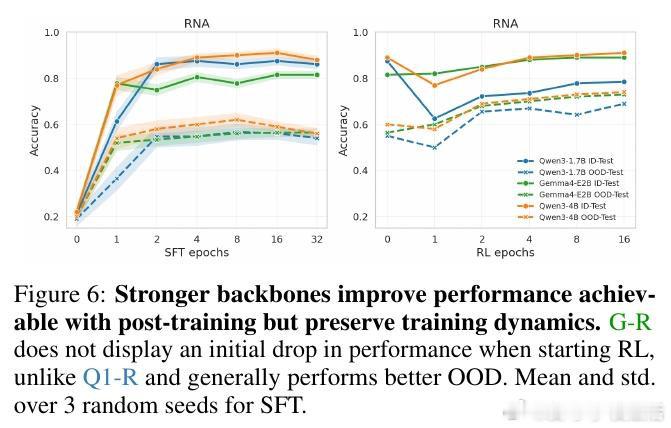
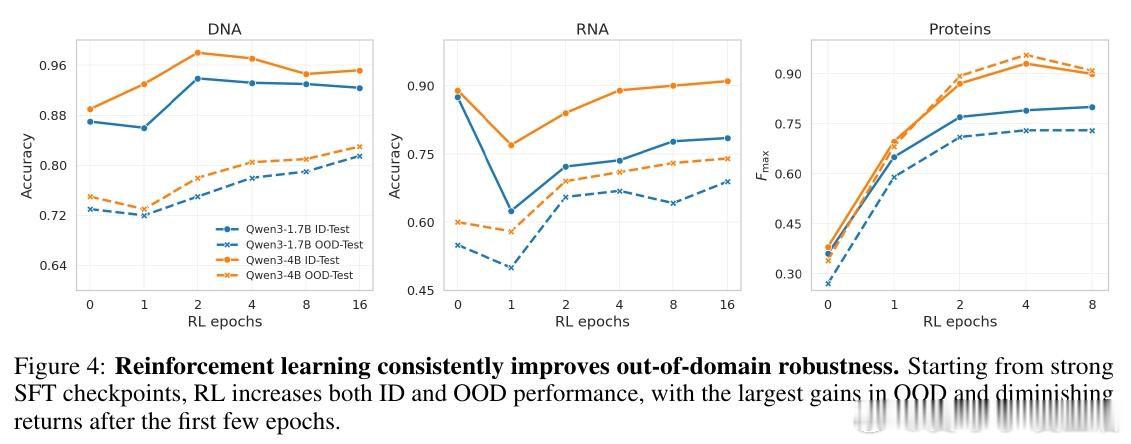
在生物推理模型领域,跨 unseen 生物系统(如新通路、新物种、新疾病)的稳健泛化是一个悬而未决的难题。过去方法受困于监督微调的单向强化,过去的方法本质原因是额外监督让模型过度贴合训练分布,而非掌握可迁移的生物机制,导致 OOD 性能随训练反而下降。
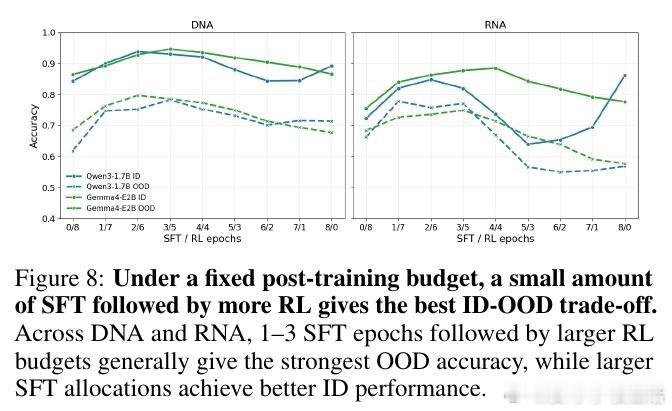
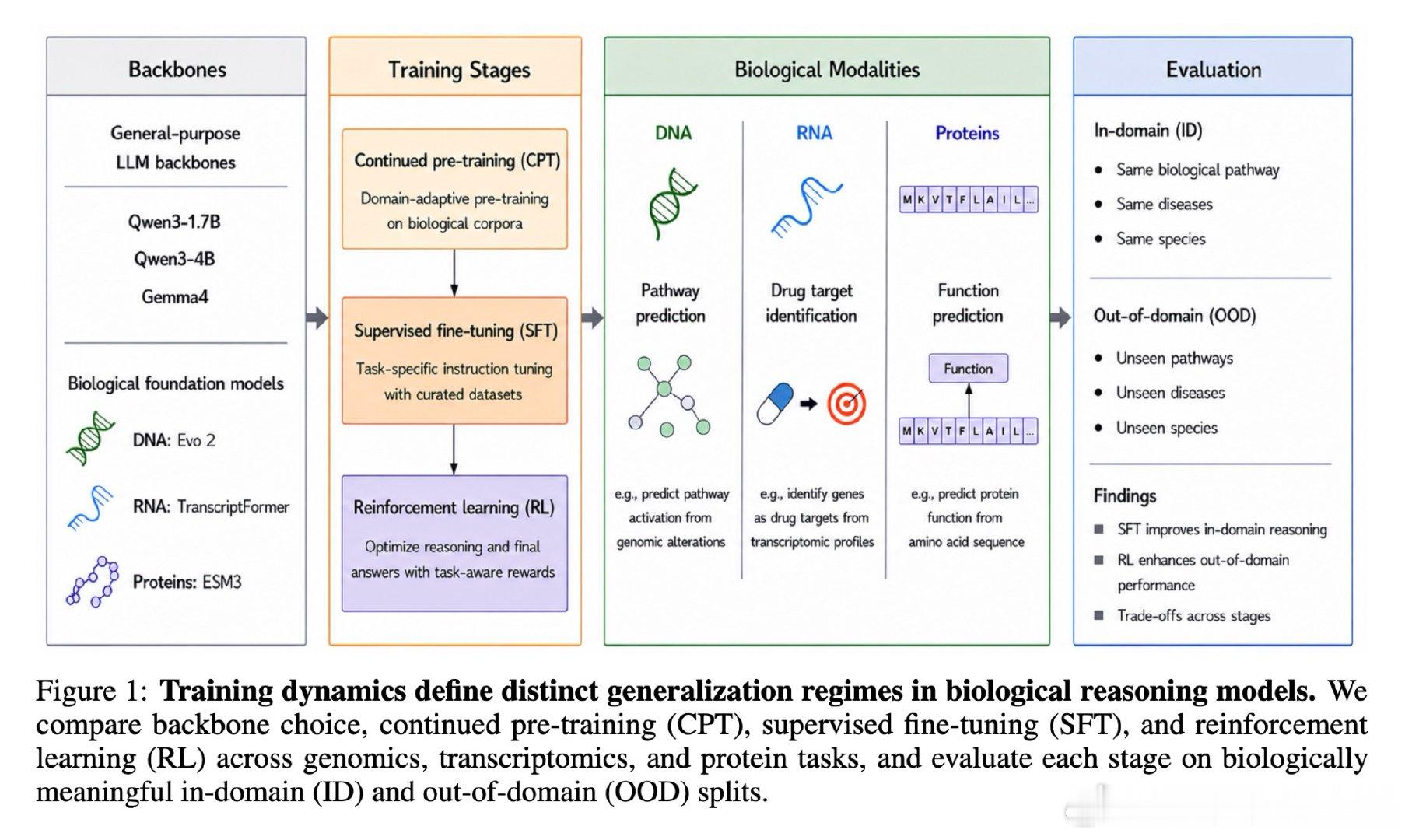
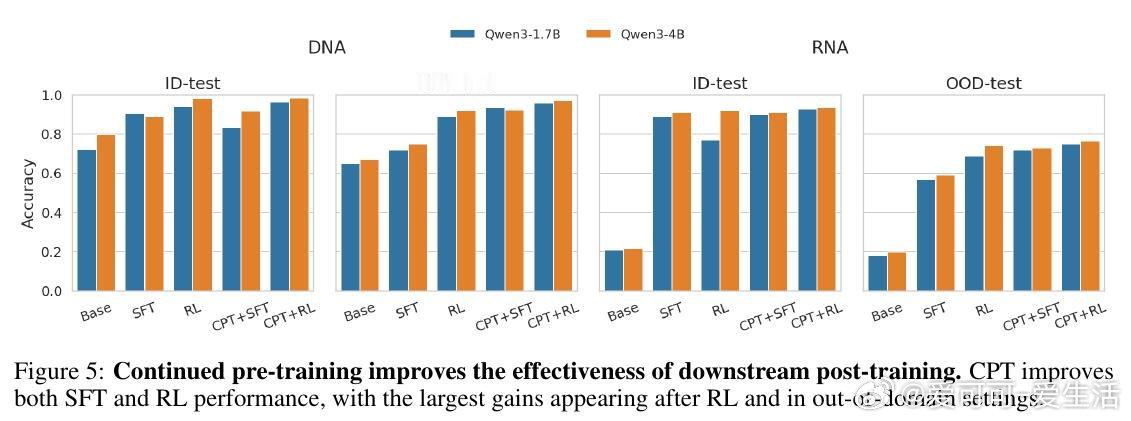
本文的核心洞见是:把后训练各阶段(CPT、SFT、RL)重新看作塑造泛化曲线的不同杠杆,而非均匀叠加的计算。由此,简短 SFT 建立任务能力、随后分配更多 RL 优化奖励、辅以 CPT 对齐生物语言这一关键操作,使 ID-OOD 权衡得以解开。
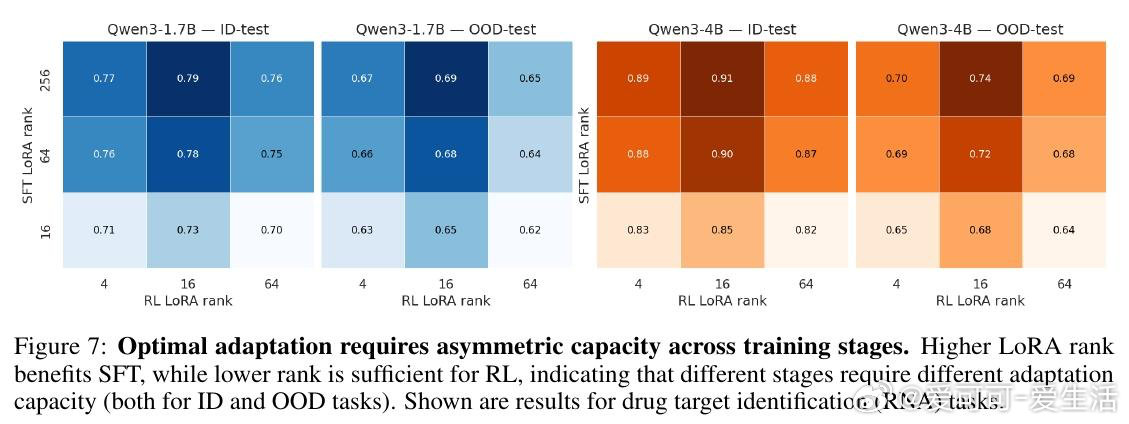
这项工作真正留下的遗产是:生物推理并不随监督或算力单调提升,而是依赖阶段组合方式。它为后来者打开的新门是:在固定预算下用非对称适配(高秩 SFT + 低秩 RL)设计后训练流程,但尚未跨过的门槛是计算归一化阶段分配、更广任务验证,以及区分真实推理与捷径。
arxiv.org/abs/2606.16517 机器学习 人工智能 论文 AI创造营