[LG]《Pretraining Recurrent Networks without Recurrence》A Kumar, P Isola [MIT] (2026)
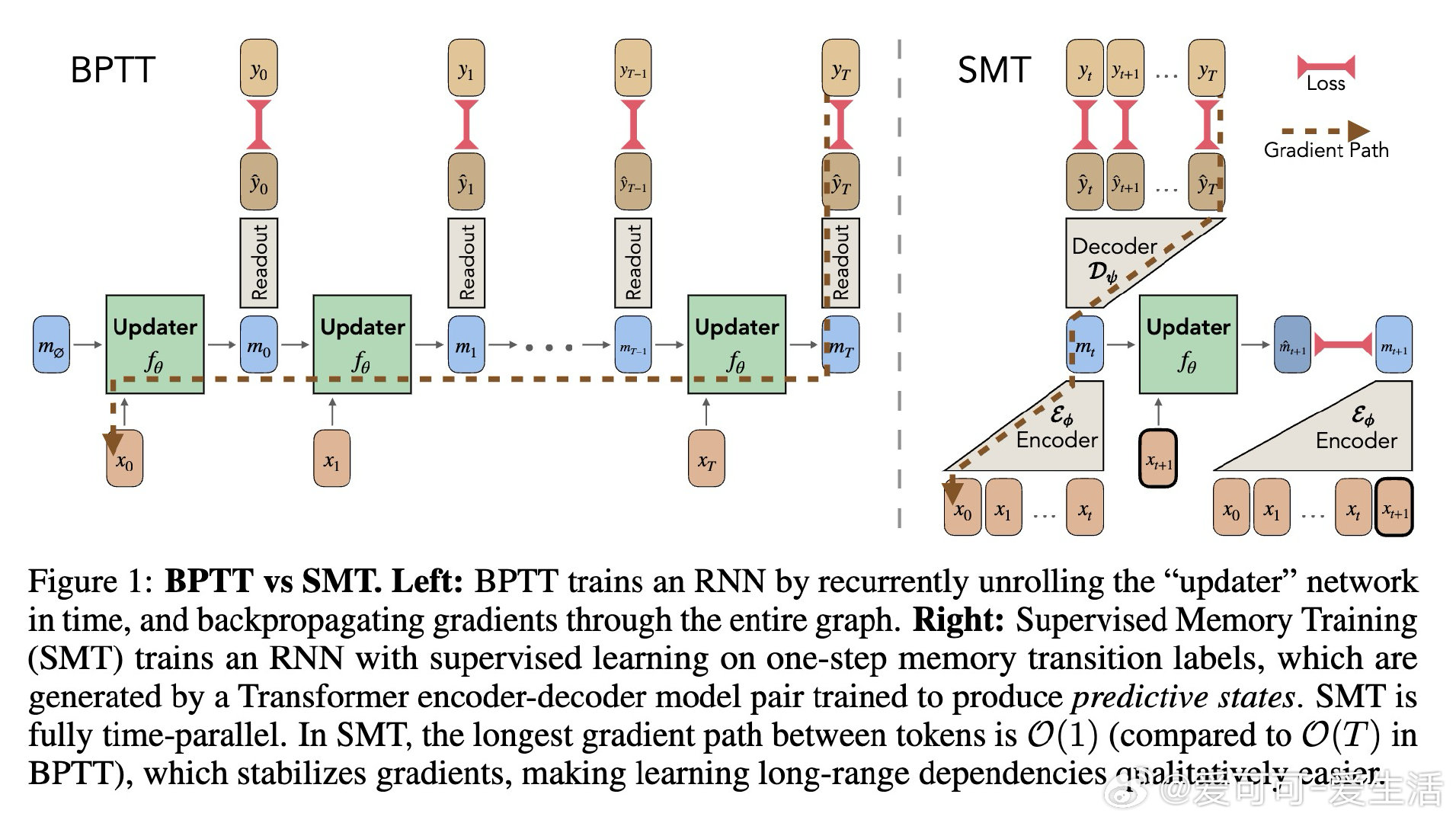
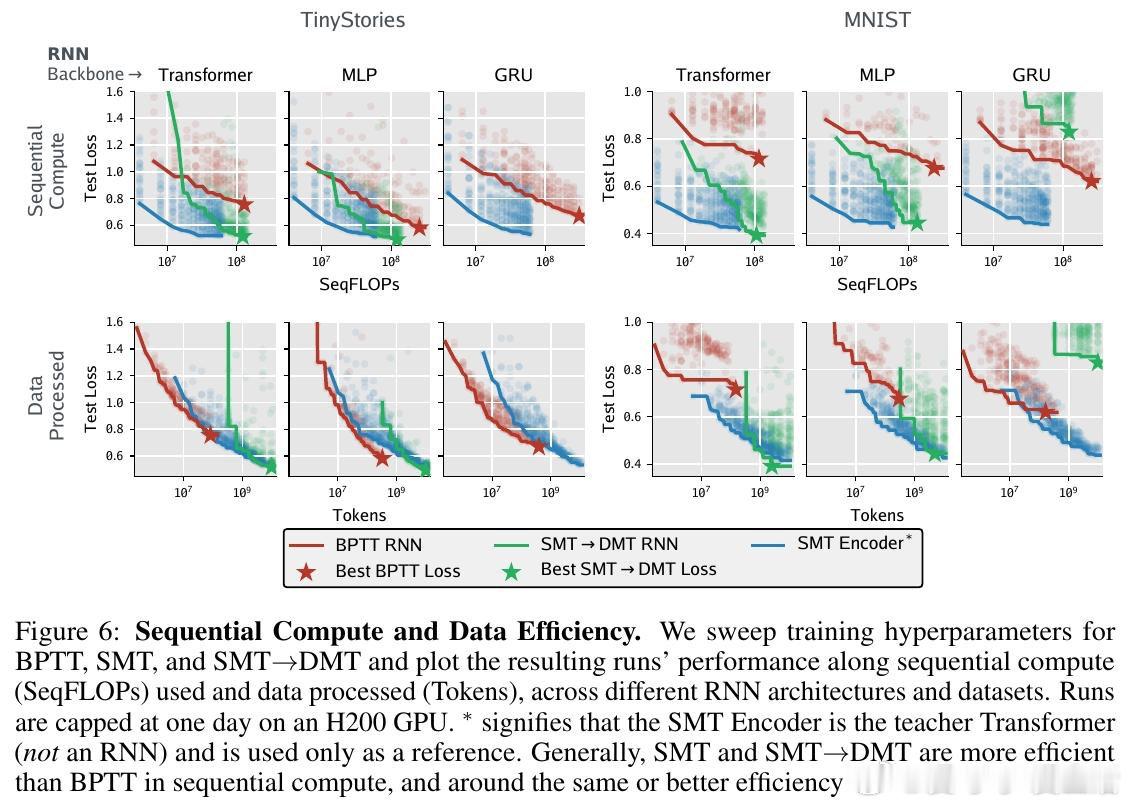
在序列建模领域,训练非线性 RNN 长期受困于“时间反向传播”(BPTT)的串行本质。由于梯度必须跨越与序列长度 T 成正比的路径,导致信息在长距离传输中极易消失或爆炸。过去的方法试图在不稳定的循环迭代中同时学习“存什么”和“怎么存”,本质原因是无法在并行硬件上实现高效的长程信用分配。
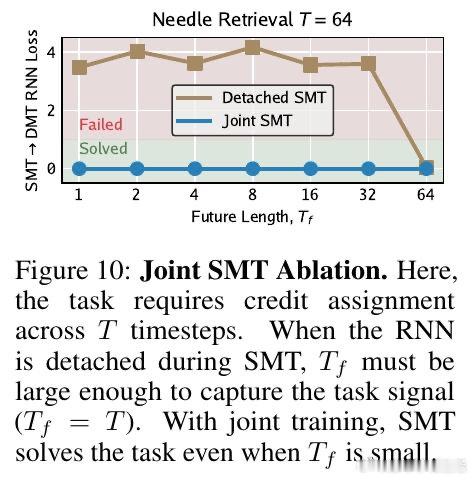
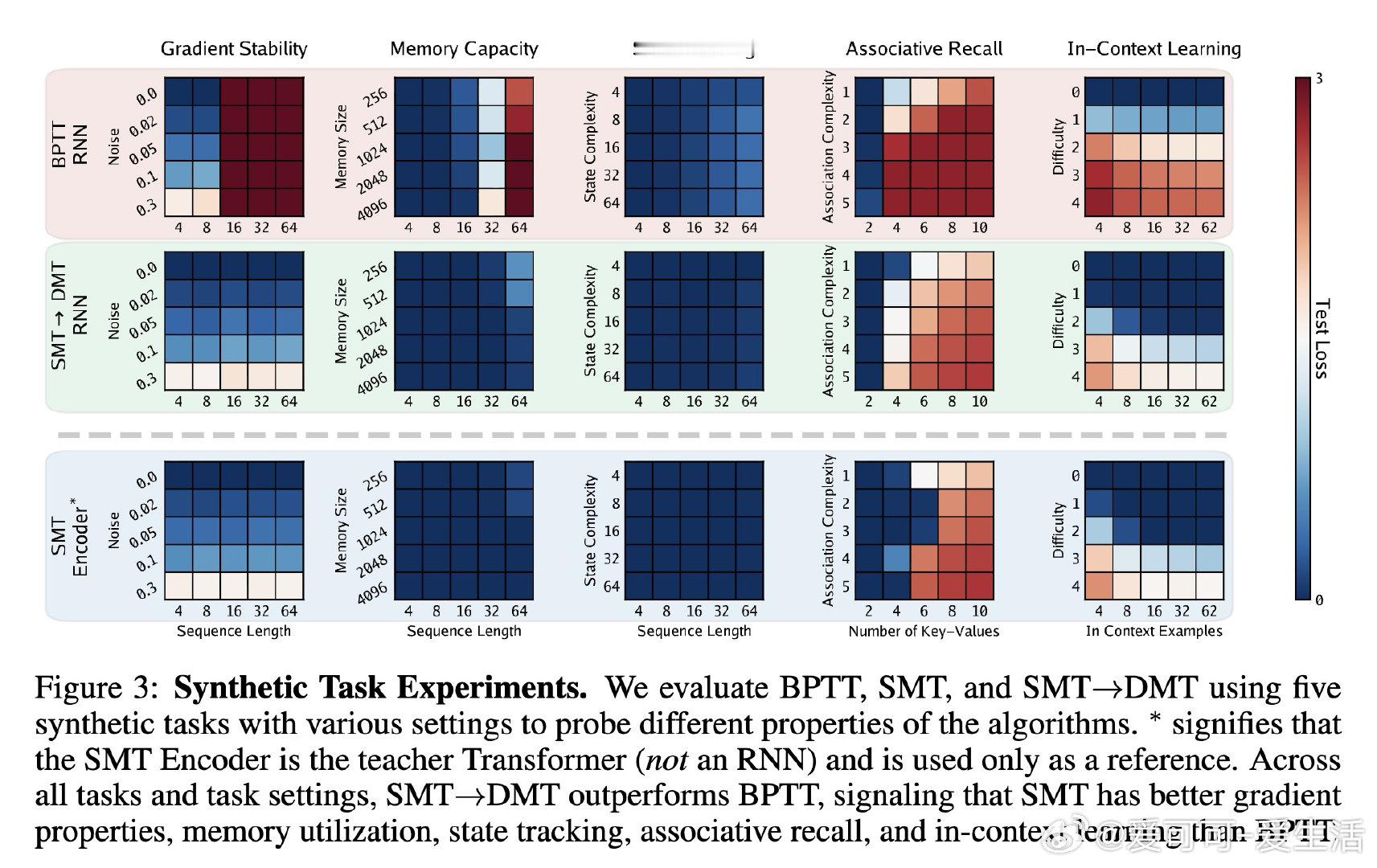
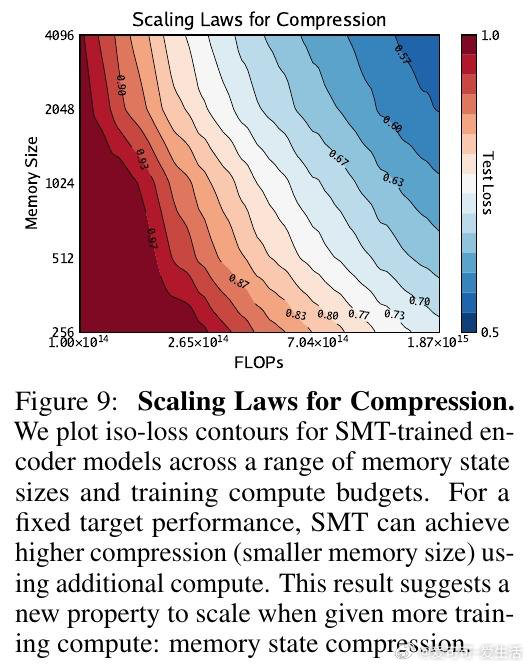
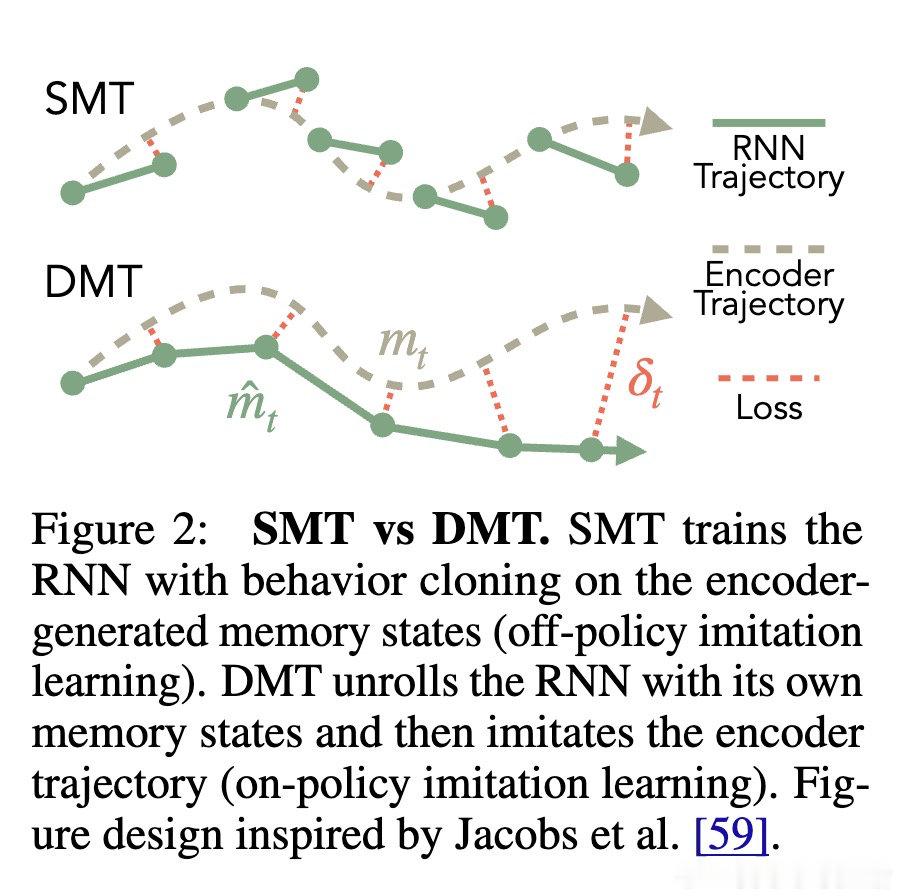
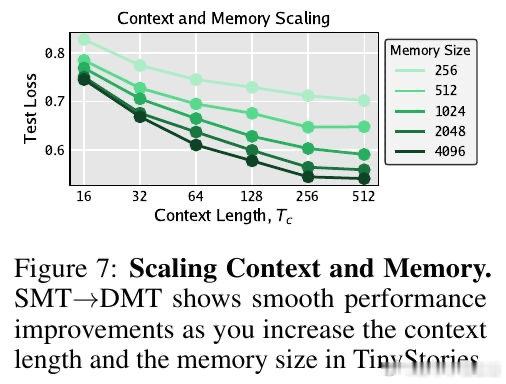
本文的核心洞见是:将过去看作一组带时间戳的事件集合,而非必须顺序处理的链条。由此,引入 Supervised Memory Training 协议,利用 Transformer 编码器作为教师,将历史压缩为预测未来的“预测状态”标签。RNN 不再需要通过展开序列来学习,而是通过单步监督学习来模仿这些内存标签的演化,将梯度路径从 O(T) 彻底降为 O(1)。
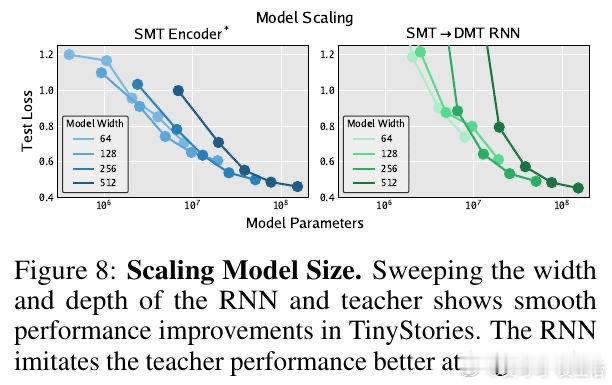
这项工作真正留下的遗产是证明了内存表示与动力学更新可以完全解耦,为非线性 RNN 的大规模预训练提供了并行化路径。它为后来者打开的新门是利用压缩状态实现无限长视野的智能体建模,但尚未跨过的门槛是 RNN 的表现上限仍受限于教师模型的表达力,且自回归推理时的累积漂移仍需依赖额外的在线模仿学习来修正。
arxiv.org/abs/2606.06479 机器学习 人工智能 论文 AI创造营