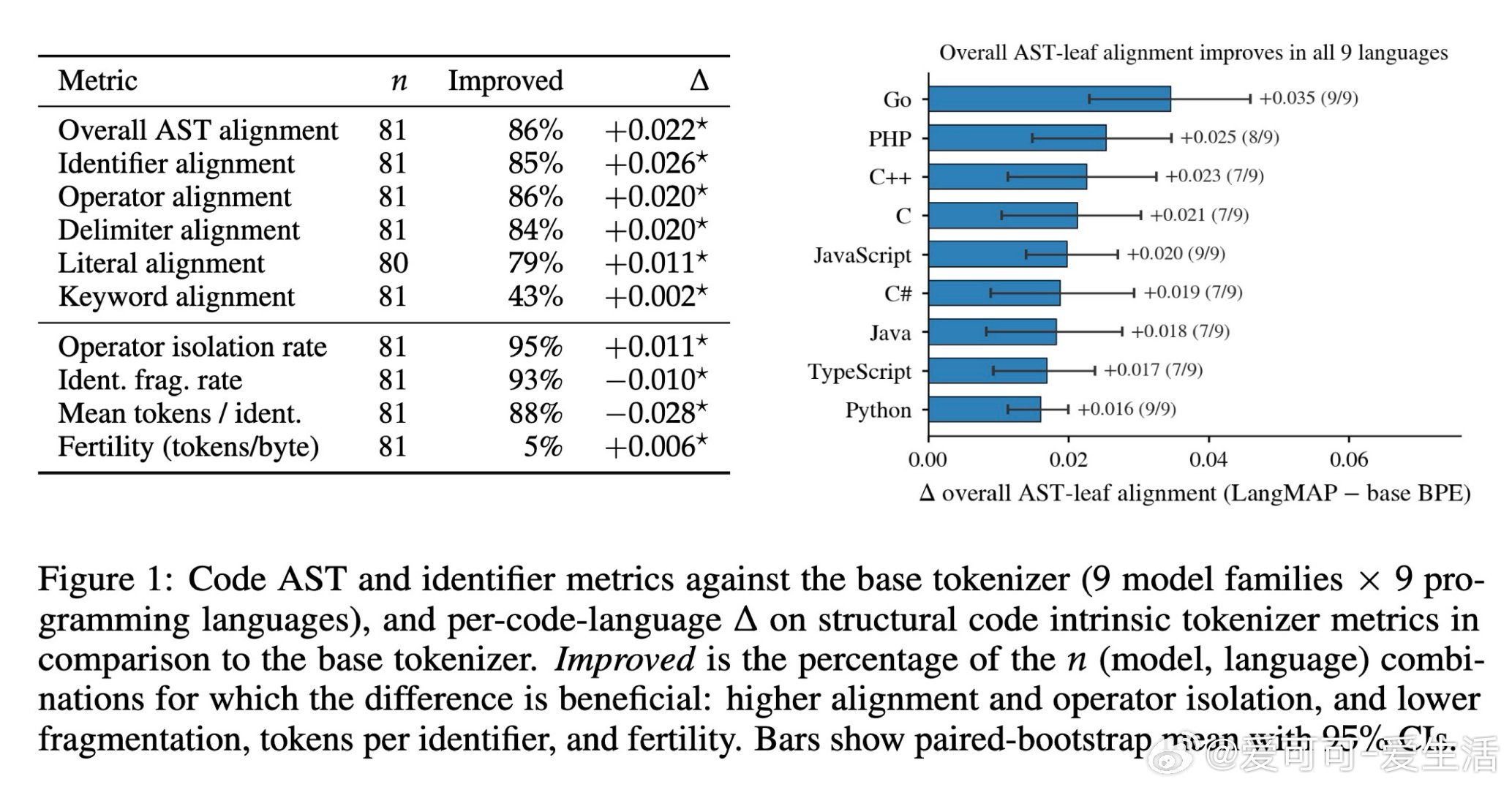
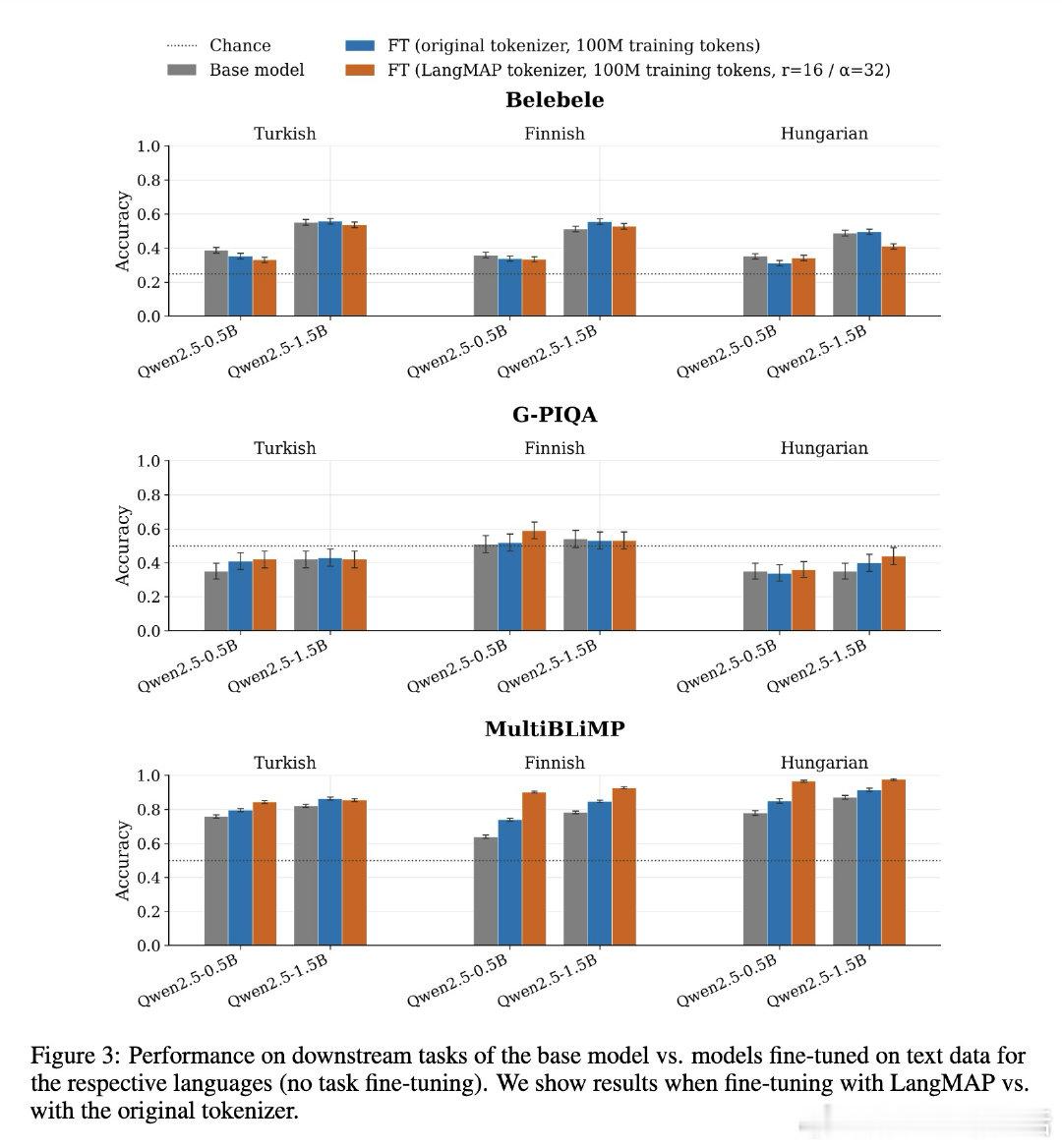
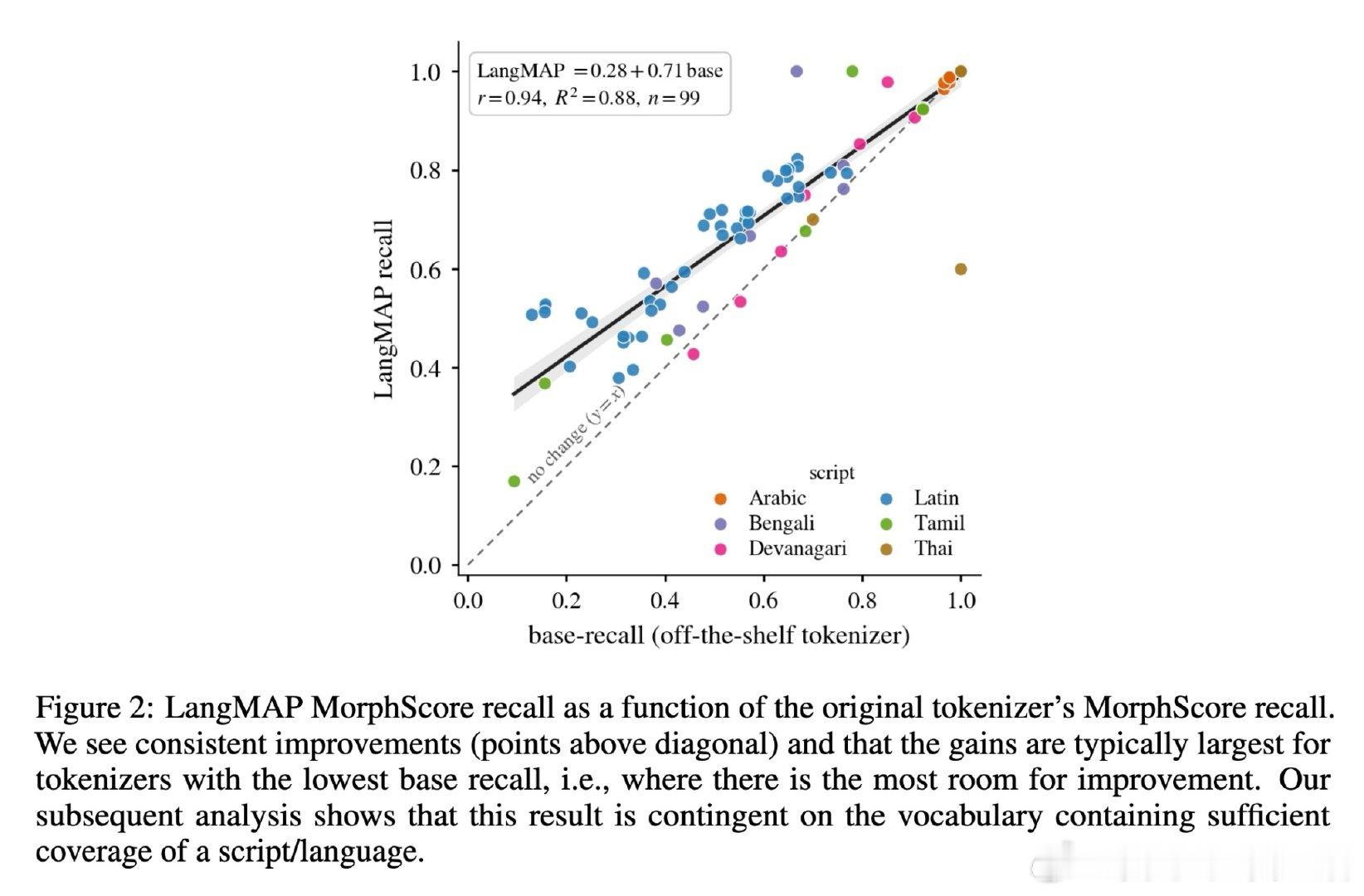
[CL]《LangMAP: A Language-Adaptive Approach to Tokenization》C Meister, S Salhan, A Szablewski, P Lesci… [EPFL & University of Cambridge] (2026)
在多语言建模领域,英文中心化的分词器导致非英语语种面临严重的过度切分难题,这不仅推高了计算成本,更损害了下游性能。过去的方法受困于必须重新训练模型或进行昂贵的词表迁移,本质原因是开发者误以为瓶颈在于“词表覆盖率”,而忽略了共享参数在概率上倾向于英文合并规则,从而“封锁”了词表中本已存在的语言学合理切分。
本文的核心洞见是:将分词过程重新看作是在共享词表下的多套语言特异性概率分布的竞争。由此,通过为每个语种独立训练概率参数而不改变词表,系统能够在推理时计算不同语言模型下的最大似然得分,从而在不增加模型参数、不依赖语言标签的前提下,通过重新激活词表中的长尾片段,实现了对输入文本的自适应精准切分。
这项工作真正留下的遗产是证明了分词偏见本质上是“权重分配”而非“词表缺失”的问题。它为后来者打开的新门是为预训练模型提供了一种零成本的语种适配路径,通过微调概率分布即可优化跨语言表现。但尚未跨过的门槛是其表现高度依赖原始词表的广度,对于词表中完全未覆盖的生僻字符或特定脚本,单纯的概率重绘依然无法突破表征能力的上限。
arxiv.org/abs/2606.23566 机器学习 人工智能 论文 AI创造营