【Alisa的大语言模型之书:神经网络与大模型的“暴力美学”手册】
“Alisa’s book of LLMs”
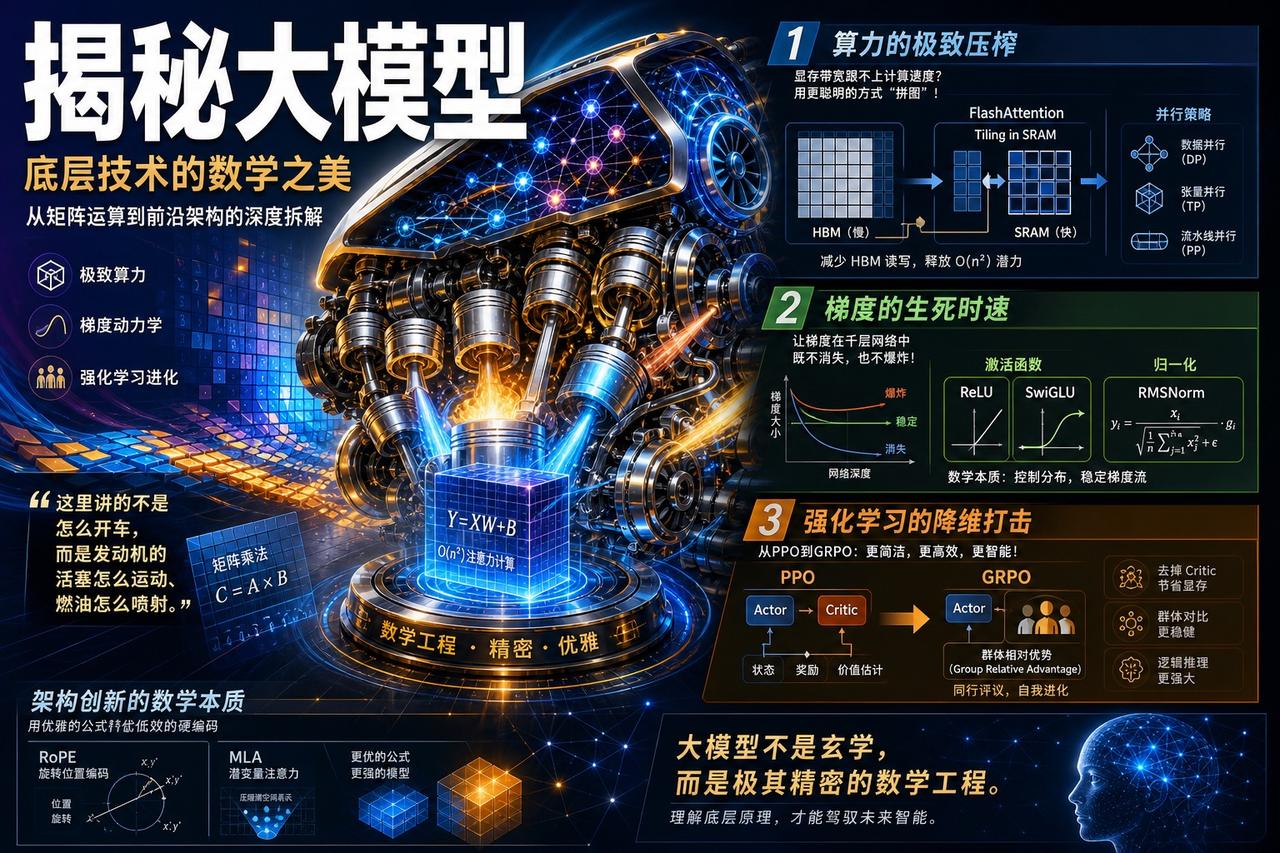
这是一份极高浓度的AI底层技术备忘录,它把从最基础的矩阵乘法到最前沿的DeepSeek架构全部拆解开了。如果把大模型比作一辆跑车,这里讲的不是怎么开车,而是发动机的活塞怎么运动、燃油怎么喷射。
核心逻辑其实就三层:
1. 算力的极致压榨:从FlashAttention到各种并行策略(DP/TP/PP),本质上都是在解决一个矛盾——显存带宽跟不上计算速度。FlashAttention通过在SRAM里玩“拼图”(Tiling),避免了频繁读写慢速的HBM,让$O(n^2)$的注意力计算在物理层面快了起来。
2. 梯度的“生死时速”:神经网络的灵魂是Backpropagation(反向传播)。文章深挖了激活函数(ReLU、SwiGLU)和归一化(RMSNorm)的数学本质,其实都是为了让梯度在成百上千层的网络中穿行时,既不消失也不爆炸。
3. 强化学习的“降维打击”:从PPO到DeepSeek推崇的GRPO,进化路径非常清晰——去掉沉重的Critic网络,改用群体相对优势(Group Relative Advantage)。这不仅省了显存,更重要的是通过“同行评议”式的对比,让模型在逻辑推理上实现了自我进化。
大模型不是玄学,而是极其精密的数学工程。所有的架构创新(如RoPE旋转位置编码、MLA潜变量注意力),本质上都是在用更优雅的数学公式去替代低效的硬编码。
alisawuffles.notion.site/alisa-s-book-of-llms