本文撰写滞后了两(三)周,由于最近沉迷大刘科幻作品,写作内容会时不时穿插大量胡言乱语。
本公众号一字一句完全UGC,除配图不含任何AI成分。保留一下人类在AI时代最后的一点坚持。
在硅谷呆了一个月。基本上一周半分配给了产业的同学,半周分配给了我自由的灵魂,一周在AllinPodcastLiquiditySummit和一些TechConf见世面,一周在闲聊/组织Hiking/发呆。
3月份的时候也来过,正值OpenCLaw带来的HypeCyclePeak,结合最近发生的各种事情,以及和3月时候的对比,分享一些takeaway:
0/AGI会非常快。不要质疑、不要质疑、不要质疑!3月份的感受是,作为白领/知识工作者的我们已经被AI替代50%,Researcher被AI替代30%;现在的感受是知识工作者被替代80%,Researcher被替代50%,Infra的Ai自动化也开始了,定性感受是10-20%;
不同researcher都表达了Scalinglaw还远远没有到头,不管是数据余量、算法还是Infra的优化,都还有很大的headroom。当然,模型的进步已经是只属于少部分人的事情了,和大部分人都无关。
1/之前觉得LLM吃掉80%的应用的价值,现在觉得可能是90%+。不过这是一个量的概念,90%的应用都没有价值。剩下的10%有杠杠可撬,最终可以释放出来的价值未必低,我甚至觉得在这里有机会出现非常大的公司。
刘慈欣在《吞食者》里面写到,文明是什么?文明就是吞食,不停地吃啊吃,不停地扩张和膨胀,其他的一切都是次要的。而自己生存是以征服和消灭别人为基础的,这是这个宇宙中生命和文明生存的铁的法则,谁要首先不遵从它而自省起来,就必死无疑。吞食者是依靠不断吞食行星来扩张的一种文明,在吞噬行星后会与它依靠相互引力作用保持同等速度运行,进行长达一个世纪的消化。
行星对抗吞食者有三种态:1.归属;2.平行;3.逃逸。
归属是一种活路。
平行必然意味着被消化,被毁灭;
第三种,吞食者最终会因为自身结构膨胀到达一个加速度的物理极限,这是最终人类对抗吞食者,以及所有行星的潜在“逃生速度”,其实也是应用类型公司对大模型的“逃生速度”。
这部小说的点睛之笔在于,吞食者其实和人类同源,吞食者就是恐龙。无限制吞食自带的负反馈平衡机制,使得地球上的文明生物有越来越小的趋势,恐龙——人——然后可能是蚂蚁,甚至最后是草。虽然在变小,但是生态系统的强度和韧性并不见得低。
大模型是一种新的不断吞食的超级文明,但这种文明本身也存在物理极限的“加速度”,越是无限制扩张越会存在内生结构的脆弱性。应用类型的公司可以靠给自己疯狂“加”速度来实现逃逸——最终极的答案可能是一种数据上的加速度。
至于怎么加杠杆的问题我们下次再说(嘿嘿)。
2/Codingmodel能力在快速收敛:1)是头部模型之间的追及问题;2)开源和闭源之间的追及问题(本质是中国和美国之间的追及问题)。但是CodingModel格局——>Coding格局咋翻译,没完全想明白,之前在硅谷和各路企业、创业者、开发者聊下来的感受是:
1)Coding很容易切换,但是AgenticWorkflow没那么容易;
2)个人开发者和创业团队很容易切换,但是Enterprise不容易(第一是价格敏感,第二是都在担心自己工作要丢,切换工具的成本很高,犯不着)。
3/企业AI需求是最大的盲区。
企业需求的特点是:
1)Adoptioncurve是阶梯跳跃式;一方面是人才结构更复杂,学习能力不同,一方面要看预算
2)模型能力不是卡点,但模型理论能力和实际能力之间的Gap会更大,企业落地需要对AI、企业Workflow和管理都懂的复合型人才;
3)价格并不敏感;
生产力进步会带动生产关系进步;生产关系变革会反作用于生产力变革。此时正处于两句话的交界处。
企业需求的结构是,模糊不清的结构:
1)100%cloud:云infra+云LLM;——>CSP、Neocloud、头部LLM
2)Hybrid:本地Infra+云LLM;——>某些ODM/OEM服务器玩家、头部LLM
3)100%本地:本地Infra+本地LLM(开源);——>某些ODM/OEM服务器玩家、开源LLM
倒回到10年前的SaaS时刻,请问长期到底有多少会彻底云化,多少是留在本地的需求?黑箱啊黑箱,但是很大就对了,都在猛猛增长就对了。
4/马上会进入模型分层的时代,ModelRouting是接下来的超级简单题,比纯粹价格战有意义100倍;
哈耶克有一篇论文是《知识在社会中的运用》,以前因为知识的分布是零碎的,价格信号成为了知识运用的最大杠杠,所以广告是最好的商业模式。但是有了AI,知识的分布可以被逆向工程,意味着知识可以直接被定价。
但是现在的问题很大:token就是信息和知识的载体,但token目前是平权的;生产不同知识凝结的劳动力是不同的,但现在不同任务都是用的一套模型。为什么我做一个简单的搜索和知识问答也需要Opus4.8呢?
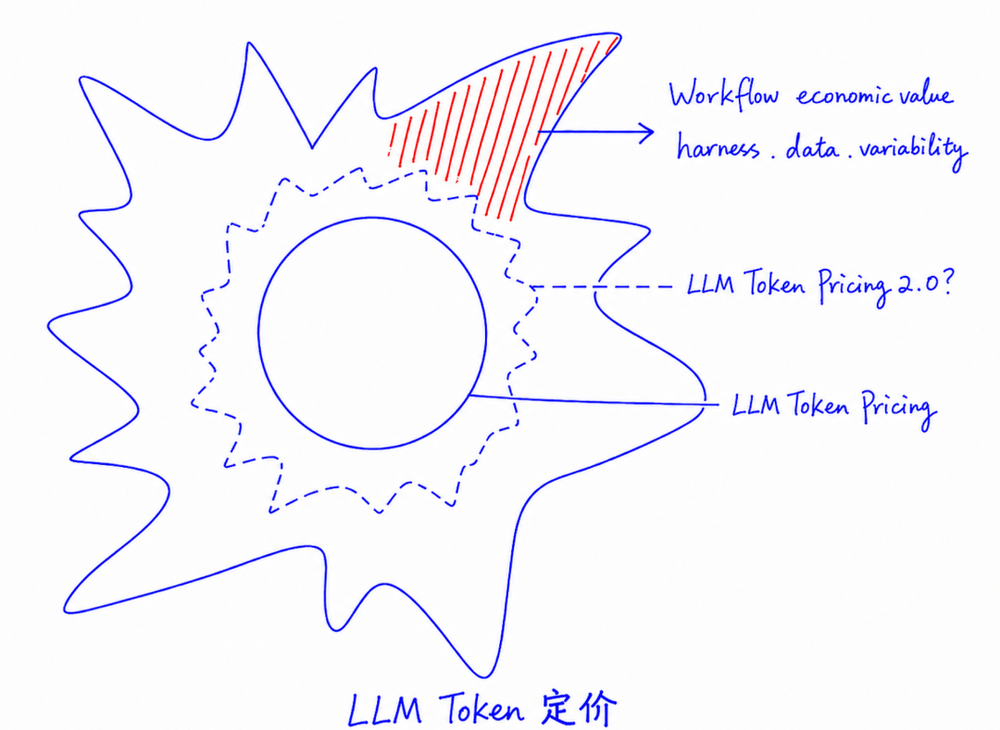
Token定价是下一个重要议题。
并不认为现下的盲目价格战有太大的意义,两个差不多的模型,如果价差只有30-50%,其实很容易被infra和tokenefficiency的优化吃掉。做好Modelrouting是线下更简单且直接的策略。
模型一旦分层,给中国选手留出的TAM会打开得巨大。
《朝闻道》里面,南方古猿开始仰望星空,真理之门就此打开了,从此以后人类就会踏上不断求索的道路。朝闻道,夕死可矣。
大刘通过宇宙文明的准则,同时也揭露了顶级闭源模型和开源模型之间的关系。Fable无论怎么封锁都是没有用的,上士闻道中士闻道下士闻道,大刘说得比这更有暴力美学。

6/这其中,Harness和数据isKey。
好的Modelrouting意味着对于workflow的价值需要有正确度量,一个超级中心化、集权制的模型公司,未必会有这样的能力。
那么,是否存在这样的机会呢:一方面,大模型不断拓展知识的边界,当算力足够的时候连人类的Taste也没有价值(因为Taste本质也是一种有偏分布,算力不够的时候AI无法充分捕捉所有的Outlier);但是一方面,在垂直领域留下了一部分知识的定价套利空间?
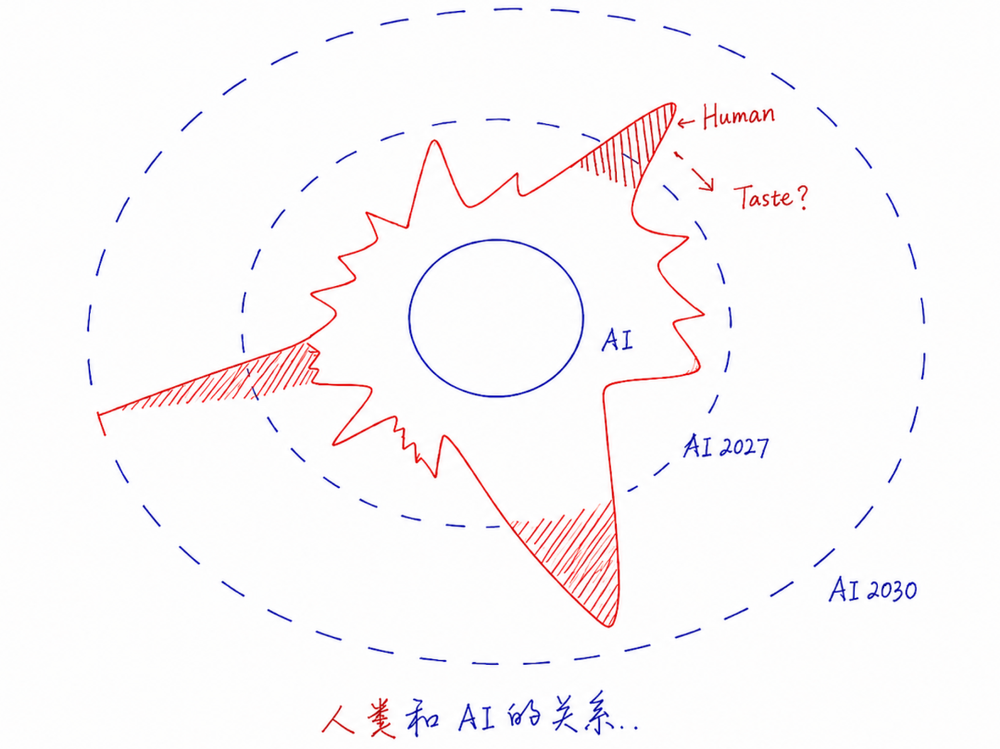
在和一些前沿lab聊的时候了解到,目前海内外数据已经可以占到大模型训练(Pretrain+posttrain)的1/10,意味着1T的Capex,训练占30%,数据市场规模可以有30bn。大模型在不断通过数据去扩充知识边界,反过来想,这里是不是大量垂直公司的机会,以及是不是会出现新的平台和生态?
综上一下吧:
1.Tokenmaxxing是一个局部问题,不用刻意夸大;
2.但从科技先驱->企业深水区,大模型增长斜率会迎来一个“Reset时刻”,此后继续健康发展(3/)
3.中国开源模型未来会有非常巨大的空间(严重看好ChinaAI,具体什么投资机会欢迎大家来讨论)(2/,3/和4/)
4.不在任何阵营头部梯队的LLM公司,和应用公司无差别(1/和4/)。要么gotop,要么gocheap,中间一点机会都没有(2/和4/)
5.Modelrouting和Token重定价带来的变化和机会,需要持续关注
再说说在Liquidityevent和某行Techconf上的见闻吧,尤其是老外咋看的。
1.存储>CPU>>光。
存储=学一个票;
CPU=学3个Maybe4个;
光=学???;太难了;NVDA和AMD的会上一半时间都在讨论CPU而不是GPU;
2.老外已经进入自我强化模式。
印象最深刻是某globalcross-overfundparter的分享,大概意思是GPU是有fab和foundry两种bizmodel的,但是Memory没有TSMC,没有Broadcom,所有Memory公司都是端到端的没有第三方平台,所以Memory的估值倍数应该更高。
总结来说,每次在硅谷呆着AI信仰会暴力充值到200%,回国了会被理性拉回来一部分。深入第一线的时候才会感受到涌现的魅力。