AI巅峰赛,正在向“达链将死,谷王当兴”的两强争霸版本过渡。
人们对“英伟达联盟”左脚踩右脚的无禁止梯云纵感到审美疲劳,反而对谷歌可落地的AI变现逻辑表现出极大兴趣。现如今,相似的剧情也在大模型圈上演。只不过,拿到谷歌生态位的,是一个略显低调的身影——MiniMax M2。
没有铺天盖地的营销,也没有惊世骇俗的整活,在发布后短短几天内,MiniMax M2冲上全球权威测评榜单Artificial Analysis(AA),成为前五名里唯一的国产开源模型。与此同时,在开发者最常使用的OpenRouter平台上,它也登顶编程场景调用量的榜首。
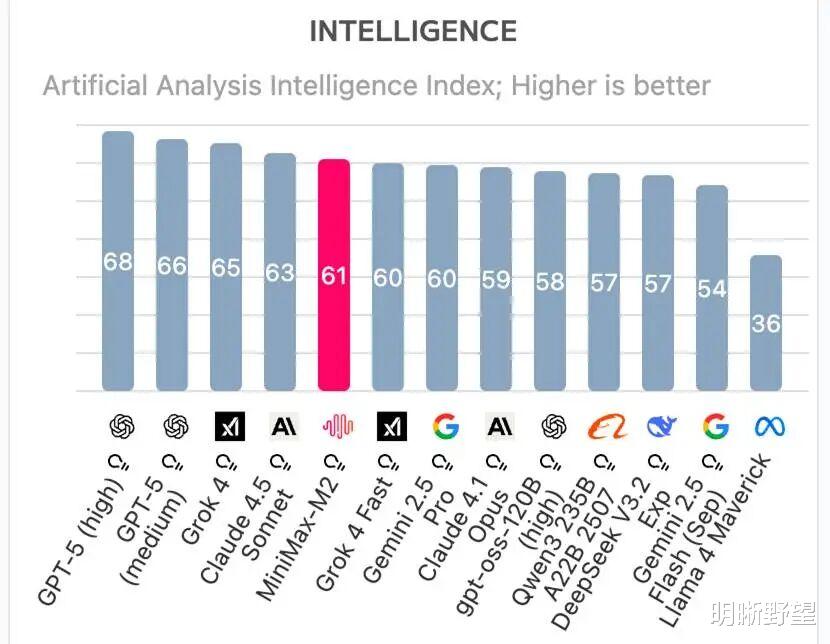
在一将功成万骨枯的“百模大战”里,MiniMax M2的快速崛起像精心策划的“突袭”。它不与巨头争夺天空的高度,反而用朴素的务实主义戳中行业痛点,为最需要AI生产力的开发者们端上了盘热气腾腾的“拼好饭”。
01
务实主义,成就大模型“拼好饭”
回顾近一两年出圈的国产大模型,会发现它们各有不同的鲜明“人设”。
月之暗面的Kimi-K2-Thinking是“记忆大师”,能一口气“读”完百万字的小说;古汉语大语言模型AI太炎3.0是精通国学的“文言文达人”,具有将文言文翻译为多语种的独特能力;腾讯的混元图像3.0则是场景应用的“魔术师”,看图翻译、解题等功能信手拈来。

它们像是舞台上的表演者,用炫目的功法成就了各自的“宗门”。
相比之下,专注落地的MiniMax M2成长路径更像是《凡人修仙传》里的“散修”,在拥有自保能力前从不显山露水,而是默默修炼内功,终于在关键时刻祭出了本命法宝。
诞生初期,MiniMax M2几乎没有进行过大规模的宣传,它放弃了在通用聊天和内容创作上与巨头们正面硬刚,而是选择更为垂直和深入的赛道——专注服务Agent(智能体)和代码开发。
它的目标用户画像极其清晰:不是追求新奇体验的普通大众,而是那些真正在一线“搬砖”、对效率和成本有着极致要求的开发者、创业者和中小企业。
它不追求写出最华丽的诗篇,而是要生成最稳定、最可用的代码;它不追求最长的对话轮次,而是要最高效地完成复杂的开发任务。没有极致的单项性能的执念,而是尽可能的钻研“多快好省”路线。
务实主义的发展路径最直接的体现,莫过于其惊人的性价比。
根据官方公布的数据,MiniMax M2的API定价为0.3美元/百万Tokens输入、1.2美元/百万Tokens输出,这个数字本身略显抽象,但一旦放入市场坐标系中,其颠覆性便显露无疑。
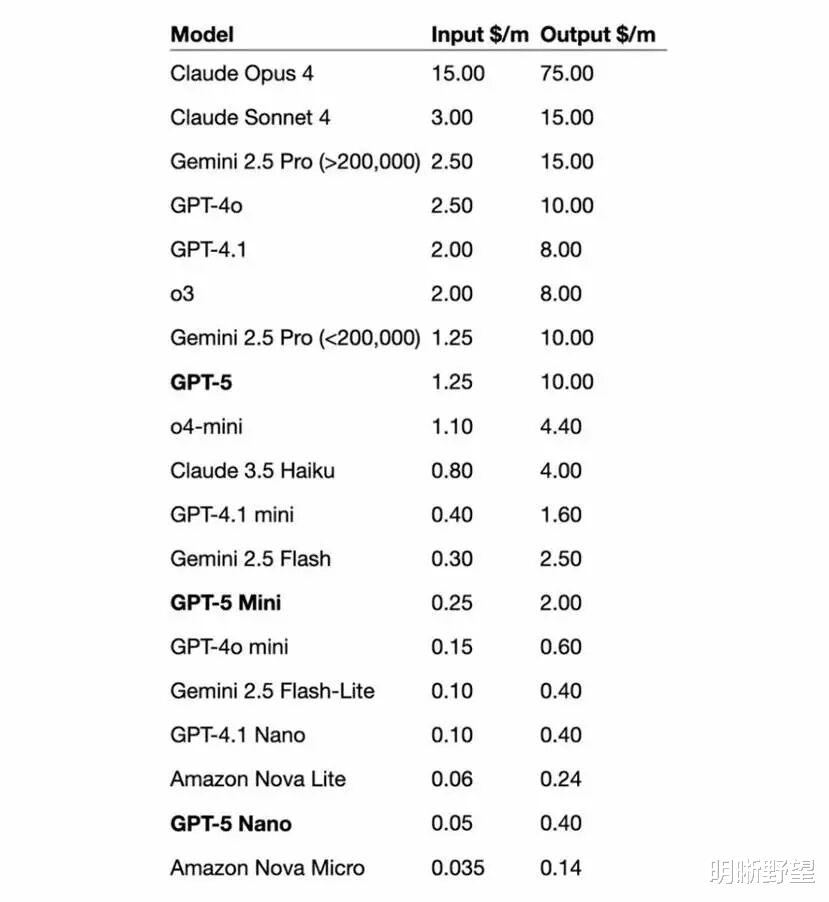
ChatGPT-5基础模型的API调用价格为1.25美元/百万Tokens输入、10美元/百万Tokens输出;Claude Sonnet4.5成本与Claude Sonnet 4.0相同,为3美元/百万Tokens输入、15美元/百万Tokens输出。
也就是说,MiniMax M2的综合成本只是谷歌Claude Sonnet 4.5的8%,但根据相关报道,MiniMax M2推理速度已经是Claude 3.5 Sonnet的两倍。
调用顶尖大模型是去米其林三星餐厅就餐,用户虽能享受到了顶级体验,但也会面临足以让任何初创公司心头一紧的账单,普通开发者更是无法天天消费。相比之下,使用MiniMax M2就像是走进了价格优惠、出餐飞快的连锁快餐店。它可能没有精致的摆盘和奢华的食材,但能以极低的价格迅速为用户补充必备能量。
对于那些曾因高昂的API费用而对AI应用望而却步的开发者而言,省钱、省心又高效的M2,无疑将曾经高不可攀的AI生产力拉到了负担得起的区间,成为名副其实的“开发者伴侣”。
02“先锋派诗人”太多,“战绩可查”太少
脚踏实地让MiniMax M2在最懂行的开发者群体中迅速引爆口碑,用“战绩可查”证明了自己。
在MiniMax M2发布后,知名科技评测平台LMarena第一时间向关注者推荐了M2的模型测试;Reddit社区技术大V在基准测试中运行了MiniMax M2,公布其获得了58.3%的优秀分数;HuggingFace的联合创始人Thomas Wolf和CoreViewHQ联合创始人Ivan Fioravant也对M2赞不绝口。
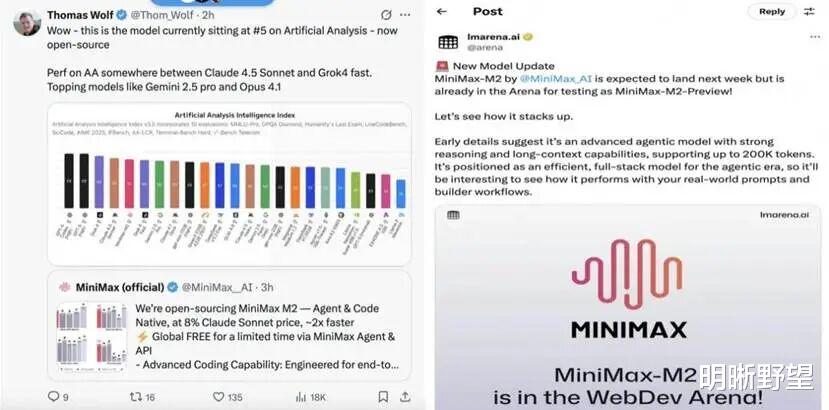
这是全球开发者根据其实际性能投出的信任票。
MiniMax M2也没有辜负从业者的关注,它的技能点几乎全部点在“落地”二字。开发者想做网站,M2不仅能写出前端代码、处理后端逻辑,甚至能自己调用工具完成部署和测试,并每个关键步骤结束后做二次检查、以保证最终的成品率,一站式完成任务目标。这种干“脏活累活”、解决实际问题的能力,在“PPT时代”尤为可贵。
事实上,MiniMax M2与全球其他产品的差异根源,主要在于技术路线上的不同选择。
当行业还在为各种混合注意力的创新而欢呼时,MiniMax却宣布放弃了看似更高效的机制,投向Full Attention的怀抱,尤其是当月之暗面发布的Kimi Linear宣称要以Efficient Attention全面超越Full Attention时,两条路线的对峙就显得尤为戏剧性。
简单来说,追求各种混合注意力的模型像一个充满奇思妙想的“先锋派诗人”,他们热衷于尝试各种新颖、轻巧的表达结构。
月之暗面的Kimi Linear采用了KDA+MLA的混合架构,像诗人创造性地将不同类型诗词结合,试图用最少的词汇(计算资源)表达最丰富的意境。法国的Mistral采用的则是“滑动窗口注意力”,工作原理类似于诗人只关注上下文中最紧邻的几个词来寻找灵感。

这些前沿的探索在长文本阅读等部分场景下取得了惊人效果,但由于结构的稳定性和普适性尚未经过时间的检验,某些极端或复杂的语境下就可能会产生歧义。
在今年放出的MiniMax技术闭门会实录中,研究人员就提到曾在M1训练中尝试过混合滑动窗口注意力的方案,结果发现“上下文越长,性能下降越显著”,甚至模型在训练和推理时会出现严重错位,这对于主打Agent和长任务场景的模型来说是致命的。
于是MiniMax M2摇身一变,成了坚持Full Attention的“总工程师”,它深知稳定性和可靠性是压倒一切的前提,所以选择的不是最新潮的“复合材料”,而是经过千锤百炼、最稳定可靠的“钢筋混凝土”。
MiniMax M2发布两天后,训练负责人孙浩海在博客中直白地揭示了“先锋派诗人”们不愿提及的痛点,也解释了MiniMax选择做“总工程师”的顾虑所在:他们对任务的复杂性抱有极大的“敬畏”,也承认以目前的技术强行使用尚不成熟的“新材料”成本和风险太高。

毕竟现代大模型早已不是只有单一功能的工具,而是需要同时胜任代码生成、数学推理、Agent工具调用、多模态理解等十几种截然不同任务的“瑞士军刀”,引入新的注意力机制就相当于给这把“刀”增加新工具,必须确保新工具不会与旧有的工具发生冲突。
这就导致了验证工作的复杂度呈指数级增长,对于追求工业级稳定性的产品而言,无异于一场噩梦。
不过另一方面,MiniMax也选择“相信未来”,将成本问题交给硬件的进步。他们认为混合注意力目前依旧存在明显的遗憾,但随着GPU等硬件的算力飞速增长,成本高、性能不稳等困境迟早会被硬件的迭代所抹平。
与其现在耗费巨大精力去修补理论上尚不完美的“新架构”,不如把精力放在模型设计和工程优化上,同时耐心等待“钢筋混凝土”变得越来越便宜。
也正因此,在整个行业都为效率狂奔时,MiniMax却敢于顶着“技术保守”的质疑、走一条更稳健的“回头路”。这不仅是技术路线的选择,更是一套成熟商业哲学的体现——直面市场的短期质疑,用“滚雪球”般累积的扎实成绩说话,而不是靠“大喇叭”式的概念宣告来赢得掌声。