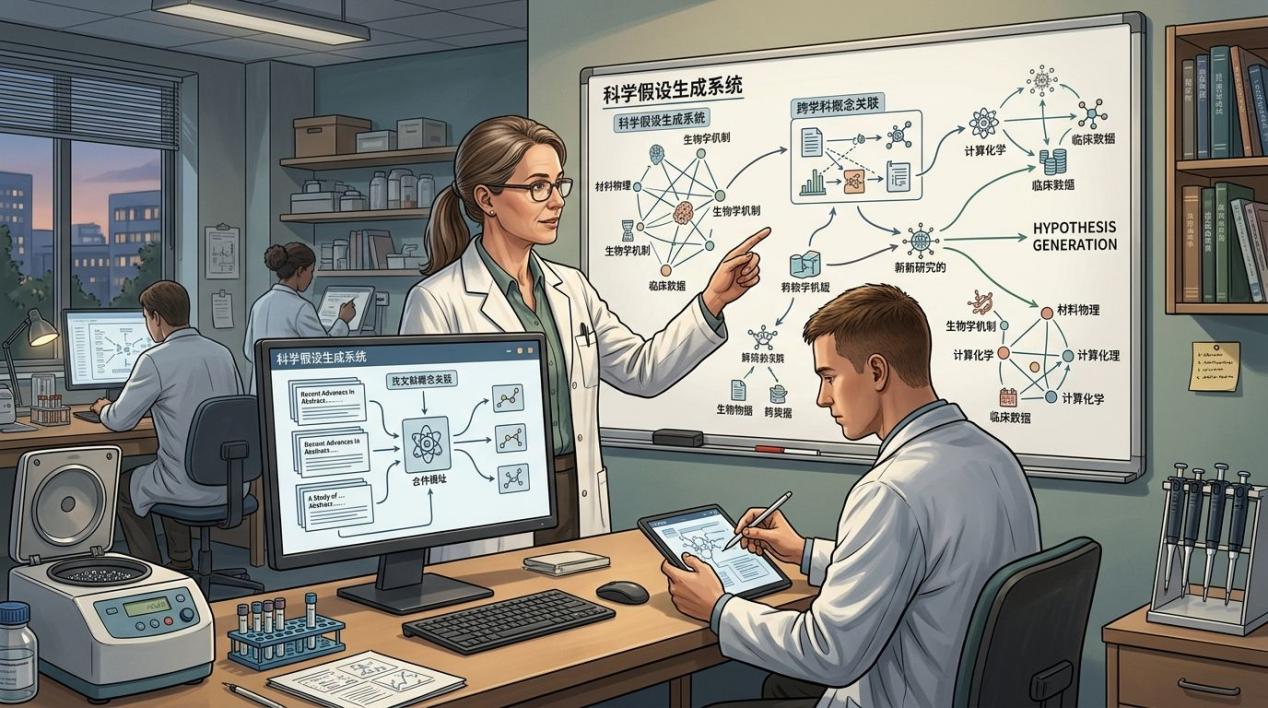
“当机器阅读文献的速度远远超过人类产出文献的速度,科研工作流的真正瓶颈就不再是‘获取知识’,而是‘提出有效问题’。”
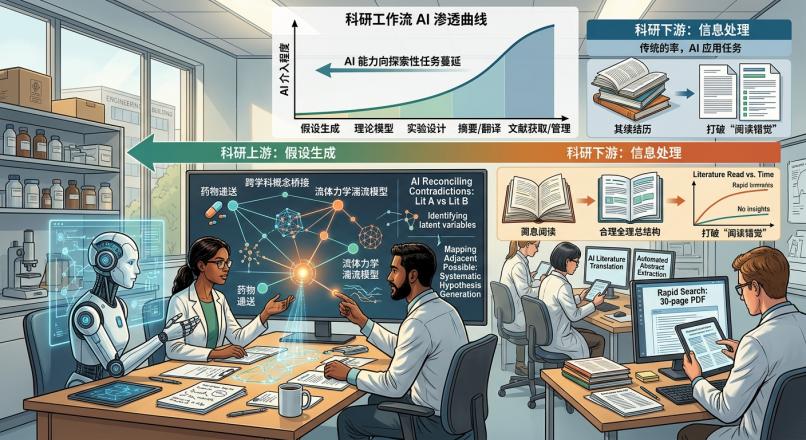
科研圈正在经历一场隐秘的重心转移。过去两年,行业通常认为大模型在科研领域的最佳落脚点是“读论文”。于是,从
PDF
解析到长文本总结,各类工具迅速将文献阅读的门槛铲平。但不少研究者会感受到一种新的虚无:当五分钟就能提炼出一百篇文献的核心结论时,为什么我们依然很难写出一篇有突破性洞见的顶刊?
答案在于,仅仅提高“信息摄入”的吞吐量,并不能直接转化为科研产出。科研的核心壁垒始终位于工作流的最上游——假设生成(Hypothesis
Generation)。而现在的趋势观察表明,AI
正在跨越文献理解的浅水区,悄然逼近这一科研的“深水区”。
跨界连接:AI
如何触碰科研上游
假设生成并非玄学,它的本质往往是高维空间中的“跨界连接”。人类科学史上的许多重大突破,都源于将
A 领域的某种机制,借用到看似毫不相干的
B 领域。
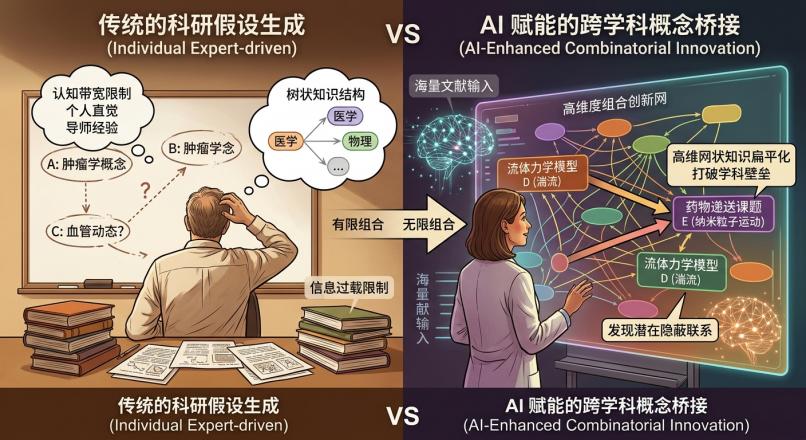
然而,人类研究者的局限在于“认知带宽”。一个生物学博士可能对某种特定的蛋白激酶通路了如指掌,但他极大概率不会去阅读材料物理学的最新进展。人类的知识结构是树状的、垂直的,而
AI 的知识结构是网状的、扁平的。
在
AI科研的语境下,大模型通过海量语料的预训练,实际上构建了一个极其庞大的概念拓扑图。一种常见情况是:当研究者向
AI 喂入特定方向的数十篇核心文献,并要求其寻找潜在的研究空白时,AI
能够通过向量检索和逻辑推演,发现
A 论文中的现象与
C 论文中的方法之间,存在一个尚未被人类验证的隐藏节点
B。
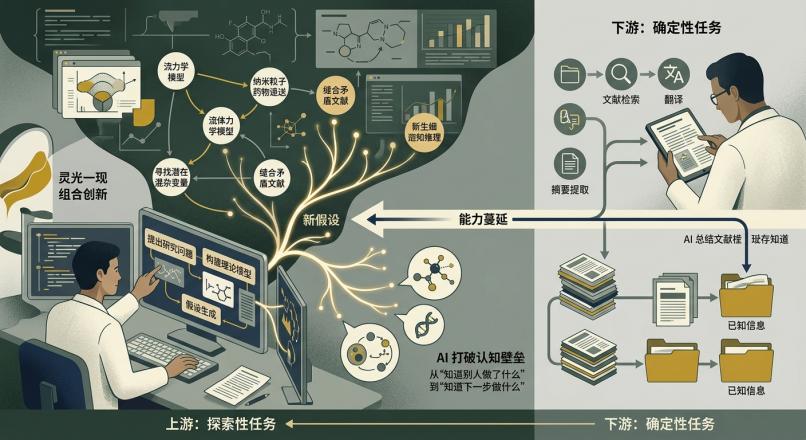
这就构成了假设生成的雏形。它不是凭空捏造,而是基于现有知识图谱的穷举式拓扑连接。当
AI
指出“某类用于电池电解液的聚合物结构,或许能改善某种靶向药的递送效率”时,它实际上是在替人类完成那些极其耗时且极度依赖运气的跨学科联想。
研究者的现实处境:从“创造者”到“裁判员”
当
AI 具备了初步的假设生成能力,科研组织和个体的真实处境正在发生微妙的变化。
对于课题组的
PI(Principal
Investigator)而言,过去的痛点是“手下的学生读文献太慢,想不出好点子”。未来的痛点可能会变成“AI
每天能生成十个看似合理的假设,但实验室的经费和算力只够验证其中一个”。
在这种新范式下,人类研究者的核心竞争力正在发生转移。文献检索和初步的
idea
构思不再是最高门槛,**判断力(Judgment)和验证能力(Verification)**将成为决定科研产出质量的胜负手。科研人员的角色,正在从单纯的“知识创造者”,转变为高通量假设的“裁判员”和“执行者”。
这要求研究者不仅要懂专业,还要懂如何向
AI 设定约束条件。如果不给
AI 划定清晰的边界(如实验成本限制、特定的伦理要求、现有设备的精度极限),AI
生成的假设往往会陷入“理论上可行,但现实中无法落地”的幻觉之中。
通向上游的阶梯:结构化的文献基建
尽管
AI 正在逼近假设生成,但我们必须保持现实感:目前的通用大模型并不能直接代替科学家思考。要让
AI 产出高质量的假设,前提是必须给它喂入极度精准、结构化且无偏差的领域知识。
这就解释了为什么在探索科研上游的道路上,底层文献工具依然是不可或缺的基建。没有扎实的文献底座,AI
的假设生成就是空中楼阁。
对于一线科研人员来说,建立一套顺畅的“人机协作”工作流是当务之急。你需要工具帮你完成从泛读到精读、从单篇解析到全局视角的跨越。以超能文献为例,其产品设计的核心逻辑正是顺应了这一工作流的变迁:
在输入端,通过中文自然语言搜索医学文献,研究者可以跳出传统关键词检索的僵化逻辑,用更符合直觉的方式圈定初始语料;配合中文摘要与文档翻译功能,快速抹平跨语种阅读的耗时。
在知识结构化阶段,工具提供的思维导图能够将长篇大论迅速降维成可视化的逻辑骨架,而Zotero插件集成则确保了这些知识节点能够无缝嵌入研究者原有的文献管理体系中。
更关键的是,当积累了足够的高质量文献后,利用其AI深度研究/综述初稿生成能力,研究者实际上是在让
AI
对现有的知识边界进行一次全面的“探底”。只有清晰地描绘出“人类已经知道了什么”,你才能站在这个边界上,去诘问
AI:“接下来,我们还可以假设什么?”
从文献理解到假设生成,AI
并没有摧毁科研的本质,它只是无情地压缩了那些机械、重复的智力劳动。对于每一个科研个体而言,这是一场无法回避的进化——要么学会驾驭这台高通量的“假设生成机”,要么淹没在它产出的海量论文中。
关注超能文献,获取更多关于
AI 科研新范式的趋势观察与实战工作流。探索中文自然语言搜索、AI
综述初稿等功能,构建你自己的智能科研底座。