2025年12月11日,旧金山湾区的雾气还未散尽,OpenAI的总部却已沸腾。CEO Sam Altman站在发布会舞台中央,身后大屏滚动着最新基准测试分数,他微微一笑:“我们从未落后,我们只是需要一点时间来证明。”
这就是GPT-5.2发布的日子——一款被外界称为“代码红色产物”的模型。短短两周前,Altman内部发出“code red”备忘录,暂停非核心项目,全力加速开发,只为应对Google Gemini 3在上个月带来的冲击。那款模型不仅登顶多项排行榜,还让Altman罕见地在X上公开赞叹:“Great model.”
但现在,轮到OpenAI还击了。
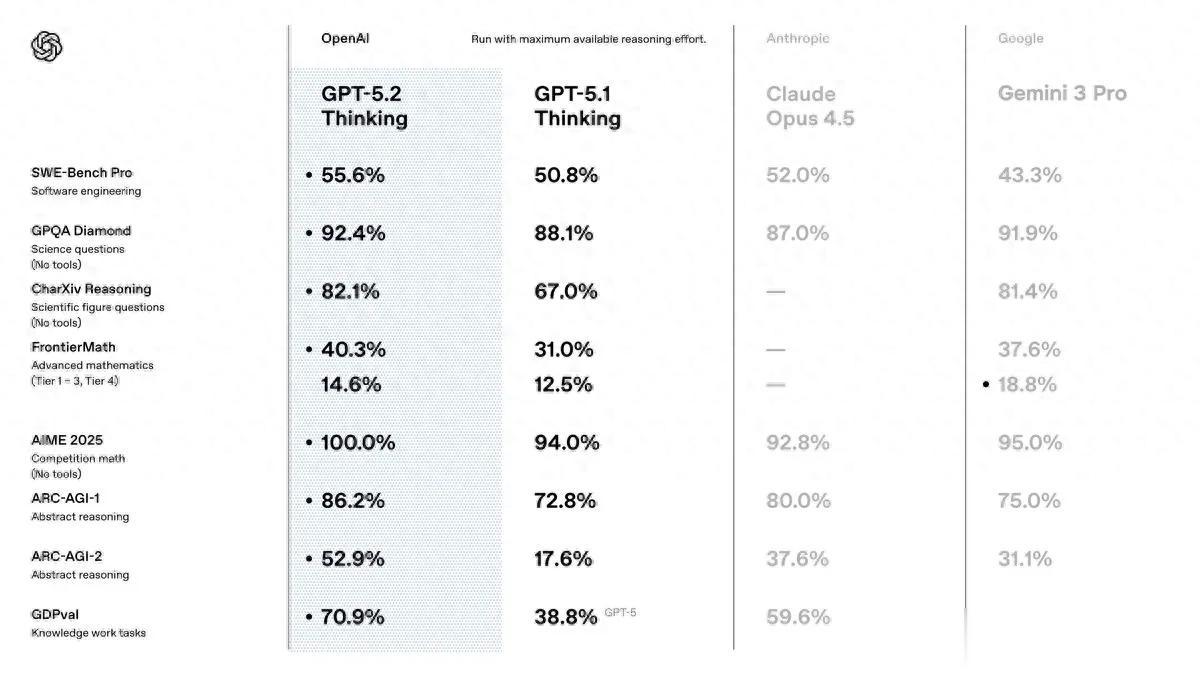
GPT-5.2并非革命性跃进,而是精密打磨的升级。它分为三个版本:Instant(快速响应日常查询)、Thinking(专注复杂推理,如编码、数学和长文档分析)和Pro(顶级精度,针对最棘手问题)。OpenAI宣称,这款模型在编程、数学、科学和视觉理解基准上全面超越前辈,并在自家新基准GDPval上击败或持平人类专业人士70.9%的任务——从财务建模到法律文档起草,无所不包。
发布会现场,一段演示让在场记者屏息:GPT-5.2 Thinking分析一张复杂电路板图像,不仅精准识别每个元件,还生成详细标签和故障诊断报告,误差率比GPT-5.1低近一半。另一段视频显示,它在SWE-Bench Pro编码测试中得分55.6%,甩开Gemini 3 Pro的43.3%。
“这是为专业知识工作者量身打造的模型,”OpenAI应用CEO Fidji Simo在简报中强调,“它能帮你建电子表格、写演示文稿、生成生产级代码,还能处理跨大上下文的复杂项目。”

竞争的火药味从未如此浓烈。Gemini 3在上月发布后迅速集成到Google生态,覆盖搜索、Workspace和云服务,吸引了无数企业用户。Anthropic的Claude Opus 4.5也在编码领域紧咬不放。OpenAI内部员工甚至有人建议推迟发布,以进一步完善模型,但Altman选择加速——结果证明,这是一记精准的反击。
基准数据成了战场焦点。在ARC-AGI-2抽象推理测试中,GPT-5.2 Pro得分54.2%,远超Claude的37.6%和Gemini 3 Deep Think的45.1%。幻觉率降低30%,长上下文理解更稳健。OpenAI还强调,模型在敏感话题上的响应更安全,减少了过度拒绝和情感依赖问题。
当然,这一切代价不菲。OpenAI预计到2030年计算投资将达1.4万亿美元,而营收目标虽雄心勃勃(年底月跑率超200亿美元),但烧钱速度仍让投资者捏把汗。Altman在采访中淡定回应:“Gemini 3对我们指标的影响比预想小得多。我们在正确的轨道上。”

发布当天,ChatGPT付费用户已开始尝鲜,API开发者紧随其后。旧模型如GPT-5.1将保留数月过渡。硅谷的AI军备赛进入新阶段:更快、更强、更实用。
GPT-5.2不是终点,而是OpenAI的宣言——在AI王冠的争夺战中,他们绝不甘居人后。下一个回合,谁先出牌?或许就在下个月。