在数字化时代,数据已成为企业决策的核心驱动力。网页爬取(Web Scraping)作为一种高效的数据提取技术,已广泛应用于市场研究、竞争情报、价格监控和AI训练等领域。进入2025年,随着反爬虫机制的日益复杂和数据隐私法规的加强,因此选择一个可靠的网页爬取API变得至关重要。本指南将深入探讨2025年最佳网页爬取API,帮助您在海量可替代方案中做出明智选择。作为一名资深计算机网络和网络数据爬虫领域的专家,我将结合技术深度和实际应用,为您提供专业洞见。无论您是开发者、数据分析师还是企业主,这篇文章将助您提升数据采集效率,并最终推动业务增长。
网页数据爬虫的定义网页爬虫(Web Crawler),也称为网络蜘蛛或爬虫程序,是一个自动化脚本或系统,用于系统性地浏览互联网,提取特定网页上的数据。简单来说,网页数据爬虫是数据驱动业务的基石,帮助企业从海量网页中挖掘价值。它模拟人类浏览行为,通过发送HTTP/HTTPS请求到目标服务器,解析返回的HTML、JSON或其他结构化数据。
爬虫的挑战在于网站的反爬措施,如CAPTCHA、IP封禁和速率限制。这要求爬虫具备代理旋转(Proxy Rotation)和指纹伪装(Fingerprint Spoofing)能力。2025年,随着5G和边缘计算的普及,爬虫速度可达毫秒级,但合规性(如GDPR和CCPA)已成为必须考虑的因素。
从技术角度来看,爬虫的核心组件包括:
请求模块:使用如Python的requests库或Node.js的axios,发起GET/POST请求。需要处理User-Agent伪装、Cookie管理和TLS指纹以避免检测。
解析模块:利用BeautifulSoup、Cheerio或XPath/CSS选择器提取元素。例如,针对动态加载页面(如React或Vue应用),需集成Headless Browser如Puppeteer来执行JavaScript。
存储模块:将数据保存为CSV、JSON或数据库,支持分布式存储如MongoDB以处理大规模数据。

网页爬取API并非简单的HTTP请求工具,而是一种集成了高级网络工程的综合平台。在计算机网络层面,爬取涉及TCP/IP协议栈的多层交互:从DNS解析到TLS加密,再到HTTP/2或HTTP/3的优化传输。传统爬虫容易因User-Agent指纹或请求频率被网站的反爬虫系统(如Cloudflare或Akamai)识别,容易导致429 Too Many Requests错误。
为什么在2025年API如此关键?首先,反爬虫技术已进化到AI驱动的水平。例如,网站使用行为分析(如鼠标轨迹或键入速度)来区分人类与机器人。API提供内置的浏览器指纹随机化和 headless browser 支持,能模拟真实用户行为。其次,数据规模爆炸式增长:据估计,全球网页数据量每年翻番,API的分布式架构(如基于Kubernetes的云集群)能处理TB级任务,而无需您维护服务器。
从IP代理角度看,API的重要性更显突出。高质量代理池(如包含数百万住宅IP)能实现地理位置轮换,避免单一IP被封禁。举例来说,在爬取区域限制内容时,使用代理可以绕过geo-blocking,确保数据完整性。此外,API往往集成合规工具,遵守GDPR和CCPA,帮助企业规避法律风险。
实际应用中,API已渗透多个行业:电商使用它监控竞争价格,金融领域提取股票新闻用于算法交易,营销团队抓取社交数据优化广告投放。没有API,这些任务将耗费数周开发时间,并面临维护成本。总之,选择API不仅是技术升级,更是战略投资,优秀的网页爬取API服务能将数据采集效率提升5-10倍。
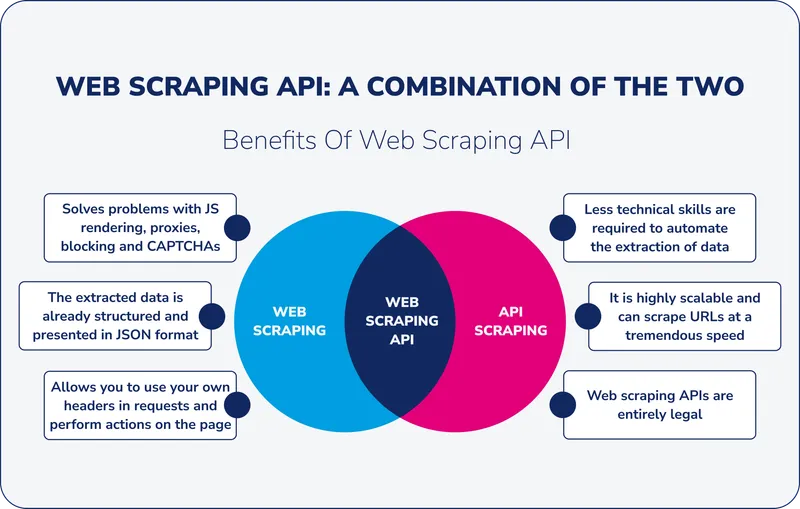
挑选API时,不能仅看表面宣传,而需从技术深度评估。以下是2025年挑选优秀网页爬虫API的核心标准:
可靠性和成功率:API应保证99%以上的提取成功率。故应重点考察其代理池大小(至少100万IP)和旋转机制。其中住宅代理优于数据中心代理,因为前者更接近真实用户IP,可有效降低反爬虫检测的风险。
速度与可扩展性:在高并发场景下,API需支持异步请求和并行处理。理想延迟应低于500ms,故优秀的API最好支持JavaScript渲染(如Puppeteer集成)以处理React或Vue.js站点。
数据格式与解析:优质API可提供JSON、CSV或XML输出,并内置CSS选择器或XPath解析。此外优秀的API能自动识别表格或列表结构,减少手动配置。
成本效率:定价模型多样,包括按请求付费(CPM)或订阅制。计算总拥有成本(TCO),包括失败重试费用。免费层适合测试,但企业级需付费计划以获优先支持。
安全与合规:确保API使用HTTPS,支持API密钥认证,并有反滥用机制。IP代理集成是关键——选择支持自定义代理的API,能无缝接入您的代理服务。
易用性和支持:SDK支持多语言(Python、Node.js等),文档详尽。社区活跃度和24/7支持至关重要。
最后,评估API的生态系统:是否集成云存储如S3,或监控工具如Prometheus?通过这些因素,您能筛选出真正高效的选项,避免低质API导致的数据丢失或额外开销。
2025年顶级网页爬取API推荐基于最新市场分析和性能测试,以下是2025年五大网页爬取API推荐。每一家服务商都结合了先进网络技术和IP代理支持,我将从功能、定价和优缺点入手,提供技术深度分析。
Oxylabs:作为企业级领袖,Oxylabs拥有1亿+住宅代理池,支持实时IP旋转和AI反检测。技术亮点:集成OxyProxy Manager,能自定义User-Agent和指纹。适用于大规模爬取,如电商数据。定价:从$15/GB起。优点:99.9%成功率;缺点:入门门槛高。
ScrapingBee:预算友好型,专注于开发者。内置headless Chrome,支持JavaScript渲染和CAPTCHA绕过。代理集成无缝,适合中型项目。定价:$49/月起,包含1M请求。优点:易用SDK;缺点:代理池较小(数百万级)。
Apify:自动化专家,提供actor-based框架,能构建自定义爬虫流水线。技术深度:支持Puppeteer和Playwright,集成IP代理API。理想于复杂任务如多页导航。定价:免费层+付费$49/月。优点:开源社区活跃;缺点:学习曲线陡峭。
Bright Data:高端选择,20,000+企业用户。亮点:动态代理分配和机器学习优化请求路径。支持地理针对性爬取。定价:$500/月起。优点:合规模块化;缺点:成本较高,但ROI高。
IPWEB:开源Scrapy框架的云版,支持分布式爬取和自定义中间件。IP代理集成优秀,能处理AJAX加载。定价:$1/1k次请求。优点:灵活扩展、价格便宜;缺点:需一定的编程知识。
这些API之所以在2025年脱颖而出,因为它们正应对新兴挑战如Web3数据和移动端爬取。建议根据您的需求测试免费试用,并优先选择强代理支持的选项,以提升稳定性。
如何集成和使用这些API?集成API需遵循网络最佳实践。首先,注册账户并获取API密钥。使用Python的requests库发送GET/POST请求,例如:
Python
import requests
url = "https://api.example.com/scrape"
params = {
"url": "target-website.com",
"render_js": True,
"proxy": "residential" # 指定代理类型
}
headers = {"Authorization": "Bearer YOUR_API_KEY"}
response = requests.get(url, params=params, headers=headers)
data = response.json()
技术深度:在请求中配置代理参数,能启用IP轮换。监控响应头,如X-Rate-Limit,以避免超限。处理错误:使用重试机制(exponential backoff)和日志记录。
对于高级使用,集成IP代理服务:例如,结合IPWEB的API与自定义代理池,实现地理分散请求。测试时,使用Postman模拟调用,确保数据解析正确。安全提示:始终加密密钥,避免明文存储。