
2025年10月9日,英特尔于业界重磅发布新一代客户端处理器——代号 “Panther Lake” 的第三代酷睿Ultra处理器架构细节。此举不仅彰显了英特尔在AI PC领域深耕不辍的战略定力,更堪称其技术演进史上里程碑式的跨越:Panther Lake作为英特尔首款基于全新Intel 18A制程工艺打造的处理器,标志着其在先进制程与架构创新的征程上迈出了至关重要的一步。
英特尔公司客户端计算事业部副总裁兼中国区总经理高嵩表示:“Panther Lake 汲取了Lunar Lake高能效和Arrow Lake强性能的优势,为用户呈现更强的AI PC 体验。” 这一表述概括了该处理器的核心突破——它并非简单的技术叠加,而是对前序产品优势的博采众长与融会贯通。接下来,GEEK极客将依托英特尔官方披露的资料,对这一架构进行部分解析。

以Intel 18A制程破局,开启2nm级计算新纪元

Panther Lake之所以能在性能与能效上实现跨越式突破,核心支撑在于其搭载的Intel 18A制程工艺——其不仅是英特尔当前量产阶段的 “巅峰之作”,更是迈入2nm级别制程时代的“里程碑式成果”,为处理器的性能释放与场景适配筑牢了根基。作为英特尔首款正式量产的2nm级制程,Intel 18A在技术方面实现了“脱胎换骨” 的升级。目前,首款采用Intel 18A工艺的消费级处理器是Panther Lake处理器,而在服务器市场,首款采用Intel 18A工艺的产品是英特尔至强6+处理器,代号为Clearwater Forest。

相较于前一代制程节点,它在能效比与芯片密度两大核心指标上均实现质的飞跃:能效层面的大幅提升,可让处理器在同等功耗下释放更强算力,或在维持性能的同时显著降低能耗,完美适配 AI PC、游戏本等对功耗敏感的设备;芯片密度的跨越式增长,则能在有限的芯片面积内集成更多晶体管,从而更好地突破性能瓶颈。官方数据显示,相较于Intel 3制程工艺,Intel 18A的每瓦性能提升高达15%;在相似的性能水平下,Intel 18A可以将功耗降低超过25%。此外,Intel 18A工艺的芯片密度相较于Intel 3工艺节点提升了约30%。

Intel 18A制程工艺已正式开启量产进程。从量产节奏来看,该制程将在今年年底前完成产量爬坡。按照规划,明年年初,全球范围内的OEM厂商等合作伙伴将完成基于该制程的 PC 产品设计,并推动全新机型正式上市,届时消费者将能亲身体验到先进制程带来的性能革新。

英特尔首席执行官陈立武站在位于亚利桑那州钱德勒市的英特尔Ocotillo园区中,正手持代号为Panther Lake的英特尔酷睿Ultra处理器(第三代)的晶圆。Panther Lake是首款基于Intel 18A制程工艺节点打造的客户端SoC。英特尔首席执行官陈立武表示:“得益于半导体技术的巨大飞跃,我们正迈入一个令人振奋的全新计算时代,这些技术进步有望塑造未来数十年的发展。结合领先的制程技术、制造能力和先进封装技术,我们的新一代计算平台将成为推动公司各业务领域创新的催化剂,助力我们打造一个全新的英特尔。”

值得称道的是,Intel 18A工艺创新性集成RibbonFET(栅极环绕技术)与PowerVia(背侧供电技术)两大核心技术,二者相辅相成、相得益彰,共同构筑起该制程在密度与能效上同步跃升的坚实基石——RibbonFET深度释放晶体管潜能,PowerVia则彻底扫清供电瓶颈,形成 “性能释放+能效优化” 的双重突破。
RibbonFET(栅极环绕技术)其命名中的 “Ribbon”(彩带)形象诠释了电流通道的全新形态:如同悬浮的纳米级薄片,栅极可从四面完整环抱电流通道。这一设计不仅大幅增强晶体管的开关控制精度与响应速度,更能显著抑制漏电现象,实现 “控电精准、损耗极低” 的效果。另外,RibbonFET的优势体现在两个方面:其一,能效表现更优——在同等频率下可降低工作电压,或在同等电压下提升驱动能力,每瓦性能的提升精准契合行业对能效的核心需求;其二,设计灵活度更高——通过调节纳米片宽度、层数,搭配不同电压阈值,可在同一工艺平台衍生出高性能、低功耗等多类晶体管规格,为客户提供 “按需定制” 的设计自由度,完美适配多元终端场景。

在传统半导体设计体系中,电源(VDD/GND)与信号互连的布线均集中于硅晶圆顶部的多层结构,这种 “正面集成” 的模式在技术迭代初期曾发挥稳定作用,但随着晶体管尺寸持续微缩、布线密度呈的逐渐增长,其固有的缺陷逐渐暴露,已然成为制约性能提升的 “瓶颈所在”。具体而言,传统正面布线方案会引发三大核心问题:其一,路由拥堵现象愈发严重,有限的顶部布线空间难以承载海量信号与电源线路,导致线路规划 “捉襟见肘”;其二,电压降与IR降问题凸显,复杂的布线交织增加了电流传输损耗,影响芯片供电稳定性;其三,电源效率大幅降低,能量在传输过程中损耗加剧,难以满足高性能芯片对能效与信号完整性的严苛要求,最终导致芯片性能难以突破既定目标。面对这一行业共性难题,半导体领域纷纷探索技术革新路径,背面供电方案应运而生,成为破解困局的“关键之举”。而PowerVia技术,正是英特尔专为Intel 18A工艺研发的专有背面供电网络(BSPDN)技术,它通过将电源布线转移至晶圆背面,彻底重构了布线体系,为解决传统方案的痛点提供了 “釜底抽薪” 的创新思路。

Panther Lake的技术突破并非局限于制程层面,其在封装领域同样暗藏玄机——Foveros-S封装技术作为核心创新之一,与RibbonFET、PowerVia形成 “三管齐下” ,共同支撑起处理器的综合性能跃升。相较于前几代封装方案,Foveros-S技术有新的提升,当然其核心优势还是在于 “模块化灵活组合”的设计理念。该技术可将计算模块、图形模块、基础模块、平台控制模块及填充模块等核心单元,按需搭配、精准集成,构建起高度可扩展的架构体系。这种设计不仅让产品研发更具灵活性,能快速响应不同终端的需求,更实现了 “能效与性能的两全其美”—— 既延续了Lunar Lake高能效的核心优势,又集成了Arrow Lake高性能基因,彻底摆脱了前代产品“顾此失彼”的困境。事实上,Foveros-S封装技术为Panther Lake赋予了“因材施教”的场景适配能力。无论是轻薄本、游戏本,还是高性能工作站等不同PC应用场景,该技术都能通过模块组合的动态调整,为各类设备提供“恰到好处”的算力支持,既避免了算力冗余导致的功耗浪费,又防止了算力不足影响用户体验。
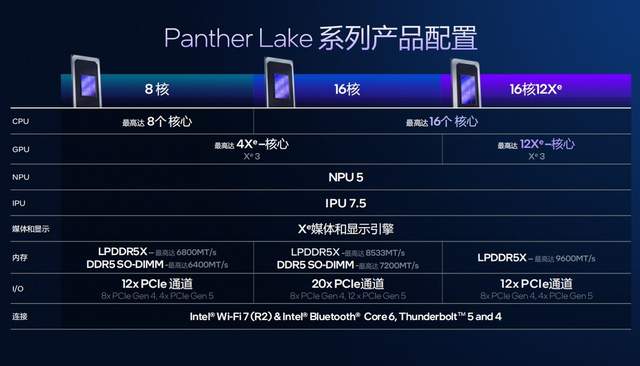
Panther Lake的产品有8核、16核,有不同的GPU的配置,这一切都得益于SoC、Xe架构的优化,也包括我们在Foveros封装技术方面的升级,为产品带来了更多灵活性。Panther Lake这款产品最多可以有16核的CPU,最高有12个Xe核的GPU——其中,8核心产品:CPU最高8核心设计(4P+4LPE),GPU配备4个Xe 3核心,最高支持LPDDR5X 6800或者DDR5 6400内存,配备12条PCIe通道。16核心产品:CPU最高16核心设计(4P+8E+4LPE),GPU规格与8核心产品一致(4个Xe 3核心),最高支持LPDDR5X 8533或者DDR5 7200内存,配备20条PCIe通道。16核心加强版产品:CPU最高16核心,GPU规格大幅提升至12核Xe 3,同时最高仅支持LPDDR5X 9600内存,内置12条PCIe通道。

值得一提的是,Panther Lake的性能核采用全新的Cougar Cove架构,旨在提升单线程性能和吞吐量。全新的性能核采用增强的分支预测以及拆分乱序引擎,并拥有多达18个执行端口。Cougar Cove源自Arrow Lake的Lion Cove,并在此前积累的丰富性能优化基础上,进行了更深层次的精进。而其主要有三点核心优化:第一是内存消歧,Cougar Cove能大幅提升CPU与内存带宽利用率。相较Lion Cove,其消歧技术更可靠、细节更精准、恢复速度更快,可更好打通内存数据传输“堵点”。第二是TLB增强,TLB作为CPU内虚拟与物理地址的映射缓存,对混合型负载至关重要。Cougar Cove通过优化TLB,避免CPU频繁访问系统内存进行耗时页表遍历,以预存常用地址映射实现快速查找,显著加速内存访问,提升复杂场景性能。第三是分支预测。Panther Lake在Lunar Lake中引入分支预测新的算法基础上,进行了深度迭代与优化,可以让分支预测的效率更高。

Panther Lake的Darkmont能效核延续Meteor Lake式低功耗配置逻辑,却在性能上实现脱胎换骨的跃升,其核心依托四重关键升级,既守牢低功耗底线,又突破性能天花板。主要升级点包括第一是分支预测,其预测更后面的分支,并且可以提高准确性,降低延迟。第二是动态预取器控制。预取器的核心作用是预测CPU即将需要的数据和指令,并提前将其从内存加载到缓存中,以确保执行单元能够持续高效工作,避免因等待数据而产生的空闲。第三是Nanocode——其可以理解为比传统Microcode更底层的微操作指令,通常面向CPU的逻辑模块,定义了如何执行一条复杂的指令。其更细粒度的控制,能够更精准、更灵活地调度硬件资源,可以提高硬件资源利用率,从而显著提升了整体性能并降低了CPU的执行延迟。第四是内存消歧,其效果与性能核相似,主要用于提升内存利用率。
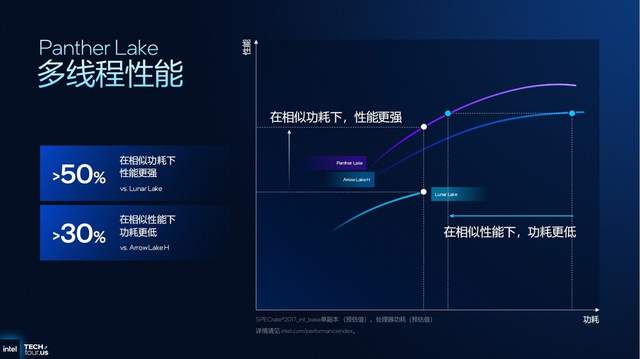
根据英特尔官方数据,Panther Lake的多线程性能在相似功耗下,面对Lunar Lake有50%的性能提升;而在相似性能下,较Arrow Lake H平台有30%的功耗下探。
升级NPU 5、XESS 3,游戏性能、AI性能均有提升

作为面向AI PC时代的核心硬件支撑,Panther Lake 引入了NPU 5——该单元在性能、尺寸、成本与能耗上实现“多赢”突破,相较上一代产品,既显著提升算力,又大幅缩减芯片面积,进而降低成本与能耗,完美契合AI PC对“高能效、低成本”算力的述求。从硬件配置来看,NPU 5搭载4.5MB暂存器 RAM、256KB二级缓存及6个SHAVE DSP,硬件基础扎实,为高效处理AI任务筑牢根基。而英特尔明确指出,NPU 5的最大革新在于对MAC(乘法累加)阵列的深度优化调整。据官方披露,其单位面积MAC数量实现翻倍增长,这一关键突破直接推动单位面积TOPS较Lunar Lake的NPU提升40%,真正实现“以更小空间,释放更强算力”。

不仅如此,Panther Lake还将GPU迭代至全新Xe3——其经过重新设计,以 “扩展性跃升” 为核心目标,从硬件配置到策略优化均实现质的突破,为图形渲染与 AI加速注入强劲动能。在核心配置层面,Xe3 GPU的Xe核心数量从4个增至6 个,一级缓存从192KB扩容至256KB,二级缓存从8MB翻倍至16MB。这一系列调整大幅减少对本地内存的依赖,可更好打通数据传输瓶颈,图形处理性能随之显著提升。同时,Xe3 GPU还采用可变线程分配策略,通过动态适配负载需求优化资源调度,进一步释放硬件潜力,对性能提升起到画龙点睛之效。
另外,Xe3还有以下关键升级点,包括:增强型光线追踪单元、优化后的Xe2矢量引擎及更高效的图形专用硬件管线——其搭载8个512位矢量引擎与8个 2048位XMX引擎。其中,XMX AI加速引擎作为核心算力源,矩阵运算能力呈爆炸式增长,峰值算力高达120 TOPS,为Panther Lake的AI性能提供坚实支撑;而增强型光线追踪单元支持异步光线追踪的动态光线管理,可大幅提升光追负载下的运行效率,完美适配3A游戏与专业设计场景。

Panther Lake针对不同终端场景的性能需求精准划分,推出 4 Xe GPU与12 Xe GPU两种配置,实现“按需匹配、效能最优” 的布局目标——4 Xe GPU的基本配置包含4个Xe核心、32个XMX引擎、4MB L2缓存、1个几何管线和4个光追单元等。

而规格最高12 Xe GPU则具备更强的计算能力,包含12个Xe核心、96个XMX引擎、16MB L2缓存、2个几何管线、12个采样器、12个光线追踪单元和4个像素后端。无论从计算能力、后端像素处理能力还是缓存能力来看,这都是非常强大的集成显卡。
作为Xe3 GPU家族的旗舰级规格,12 Xe GPU则是适配高性能场景的核心利器。该规格硬件参数极具竞争力,涵盖12个Xe核心、96个XMX引擎、16MB L2缓存,同时配备2个几何管线、12个采样器、12个光线追踪单元及4个像素后端。不仅能为复杂计算任务提供澎湃动力,还可以大幅提升画面渲染与处理效率。同时,16MB L2缓存可有效降低数据访问延迟,保障算力持续释放。综合来看,12 Xe GPU在计算、渲染以及缓存性能方面颇为强大。

据英特尔官方测试数据,Panther Lake的Xe3 GPU相较前一代Lunar Lake的Xe2 GPU,图形性能提升超50%,增幅斐然可观。这一跨越式提升,源于两大核心因素的相辅相成:一是渲染切片规模扩容,从4 Xe升级至6 Xe,算力基础显著增强;二是Die尺寸优化,支持12 Xe高规格配置,为性能释放提供充足空间。
在追逐高性能的同时,Xe3 GPU对能效比的打磨亦达到新高度。相较于更早一代的Xe架构(如Arrow Lake-H处理器),其每瓦性能提升超40%。这一能效优势意义重大,意味着在轻薄本、掌机等对续航与功耗敏感的设备平台上,Panther Lake能以更高效的能耗控制,稳定输出强劲图形性能,完美平衡体验与续航需求。

XeSS方面,英特尔此前推出的XeSS 2已为视频游戏图形处理加速奠定基础,其核心逻辑是在两帧 “真实” 渲染帧间插入 AI 生成帧,并依托低延迟技术抵消延迟影响,有效提升画面流畅度。Panther Lake 发布后,英特尔进一步推出XeSS-MFG(XeSS Multiframe Generation)功能,该技术最多可额外注入三帧插值帧,让游戏流畅性再攀新高。
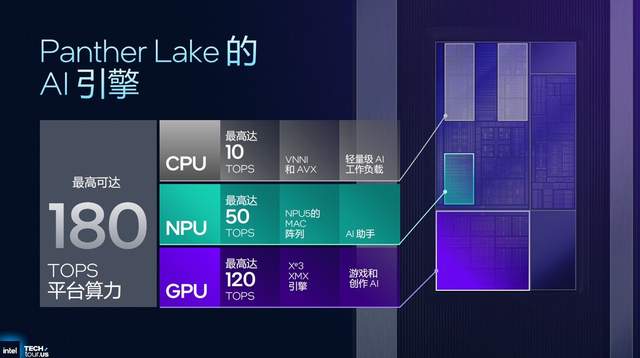
由于CPU能提供10TOPS的算力,GPU能提供120TOPS的算力,NPU能提供50TOPS的算力,这就让Panther Lake拥有180TOPS的平台总算力,因而其能够更好地应对不同场景的应用需要。

Panther Lake作为一套完整的客户端平台,在连接性与媒体处理领域同样面面俱到,通过全方位升级精准适配未来高性能、高带宽的应用需求,为设备高效运行筑牢基础——该处理器支持多达20条 PCIe通道,为高性能SSD、独立显卡及各类外设的连接提供绰绰有余的带宽,彻底消除数据传输瓶颈,保障多设备协同运行时的流畅性。无线连接方面,Panther Lake集成下一代通信标准,涵盖Intel Wi-Fi 7(R2)与蓝牙6,可实现高速、稳定的无线数据交互,进一步拓展设备使用场景的灵活性。

整体来看,Panther Lake的推出目的主要指向AI PC的规模化部署,因此我们可以看到它的升级点非常多,包括新一代能效核、性能核、NPU、XE3。尤为值得关注的是,Panther Lake的总AI TOPS(每秒万亿次运算)达到180,这一算力水平相较前代实现了“质的飞跃”,不仅能轻松应对语音助手、实时翻译、图像生成等主流 AI 应用,更可支持复杂的本地AI模型运行,让AI功能摆脱对云端依赖,实现 “即时响应、高效处理”。同时,处理器集成的XESS多帧生成技术,通过AI驱动的帧间插补算法,在提升游戏、视频等场景画面流畅度的同时,有效降低硬件负载,既兼顾了用户体验,又进一步释放了核心算力,实现 “性能与体验双赢”。在连接技术层面,Panther Lake同样“与时俱进”,集成Intel Wi-Fi 7 (R2)与蓝牙6。整体来看,Panther Lake通过对核心硬件、AI 算力、连接技术的“多点开花”式升级,能很好地解决设备性能、算力、连接的关键痛点。

Panther Lake平台的性能和效率提升显著——包括单核性能在相同功耗下比上一代Lunar Lake提高了10%;综合性能在相同功耗下比上一代Lunar Lake有50%的提升;在相同多核性能下,功耗比Arrow Lake降低30%;显卡综合性能提高50%;NPU较上一代Lunar Lake有大于40%的单位面积TOPS提升;IPU功耗可以降低1.5W;SoC功耗相比Lunar Lake下降可达10%,相比Arrow Lake则有高达40%的功耗降低。
小结
Panther Lake的划时代意义,首先体现在制程工艺的脱胎换骨——其搭载的Intel 18A 制程是英特尔自主研发并量产的首个2nm级别节点,相较前代Intel 3制程,实现了每瓦性能提升15%、芯片密度提升约30%的双重突破,为处理器的高性能与低功耗奠定了坚如磐石的基础。同时,它采用成熟的2.5D Foveros-S先进封装技术,将计算、图形、平台控制等模块高效互联,既实现了高密度堆叠,又保障了低延迟通信,堪称封装技术与制程工艺珠联璧合的典范。
在核心架构设计上,Panther Lake更是精益求精。其搭载全新Cougar Cove性能核与Darkmont能效核,前者基于AI电源管理技术动态调配资源,通过内存消歧、TLB 增强、分支预测优化三大升级,实现了内存带宽利用率与指令执行效率的同步跃升;后者则延续高能效基因,与性能核协同配合,轻松应对多元负载。新一代XE3与第五代NPU的加持更让其如虎添翼——12核与4核Xe3 GPU的差异化配置适配不同场景,而NPU算力的提升则为AI任务提供了强劲澎湃的算力支撑。纵观整体架构,Panther Lake以Intel 18A制程为基、以架构创新为魂、以场景适配为纲,真正实现了“能效与性能兼备、创新与实用并行” 的研发目标,无疑将为AI PC、游戏设备注入蓬勃旺盛的发展新动力。